Codeflow와 Deployflow로 시작하는 카카오클라우드 CI/CD 파이프라인



애플리케이션을 배포하는 일은 더 이상 소스 코드를 서버에 옮겨 실행하는 단순한 작업이 아닙니다. 코드 변경은 리뷰를 거쳐야 하고, 빌드 결과물은 이미지로 관리되어야 하며, 배포 매니페스트와 실제 클러스터 상태는 계속 맞춰져야 합니다. 운영 환경에서는 새 버전을 바로 노출하기보다 먼저 검증하고, 필요한 경우 승인 절차를 거친 뒤 트래픽을 전환해야 합니다.
이 과정은 개발팀과 운영팀 모두에게 익숙한 일상이지만, 여러 도구와 콘솔에 흩어져 있으면 작은 변경 하나를 추적하는 데도 많은 맥락이 필요합니다. 어떤 커밋이 어떤 이미지로 빌드됐는지, 그 이미지가 어떤 매니페스트에 반영됐는지, 실제 클러스터에는 어떤 버전이 배포됐는지 한 번에 따라가기 어렵기 때문입니다.
카카오클라우드는 이러한 개발-배포 과정을 더 효율적으로 연결할 수 있도록 Codeflow와 Deployflow를 새롭게 출시했습니다. 두 서비스를 함께 사용하면 코드 변경부터 이미지 빌드, 매니페스트 갱신, 쿠버네티스 클러스터 배포까지 이어지는 CI/CD 파이프라인을 카카오클라우드 안에서 구성할 수 있게 됩니다.
하나의 코드 변경이 실제 배포로 이어지는 과정을 따라가며, 두 서비스가 어떤 역할을 하는지 살펴보겠습니다.
왜 Codeflow와 Deployflow인가
많은 팀이 이미 Git 저장소, CI 도구, 이미지 저장소, 배포 도구를 조합해 CI/CD를 운영하고 있습니다. 하지만 클라우드 환경이 커질수록 “도구를 연결했다”는 사실만으로는 충분하지 않습니다. 코드 변경과 배포 결과를 같은 기준으로 추적할 수 있어야 하고, 배포 전 검토와 승인 절차도 자연스럽게 포함되어야 합니다.
Codeflow와 Deployflow는 특히 다음과 같은 상황에서 유용합니다.
- 카카오클라우드 안에서 소스 관리, 빌드, 이미지 저장, 쿠버네티스 배포를 연결하고 싶은 경우
- 어떤 코드 변경이 어떤 이미지와 매니페스트로 이어졌는지 명확하게 남기고 싶은 경우
- 배포 전 변경 내용을 검토하고 승인 절차를 거친 뒤 반영해야 하는 경우
- Blue/Green, Canary 같은 배포 전략으로 새 버전을 단계적으로 노출하고 싶은 경우
즉 Codeflow와 Deployflow의 핵심은 단순히 “빌드와 배포를 자동화한다”가 아니라, 코드 변경부터 운영 반영까지 이어지는 과정을 추적 가능하고 검토 가능한 구조로 만든다는 데 있습니다.
코드 변경부터 배포까지 하나의 흐름으로
예를 들어 애플리케이션의 화면 색상을 바꾸는 작은 변경 사항이 있다고 가정해 보겠습니다. 기존에는 코드 저장소, 빌드 도구, 이미지 저장소, 배포 도구를 각각 확인해야 했다면, Codeflow와 Deployflow를 함께 사용할 때는 이 과정을 크게 세 단계로 바라볼 수 있습니다.
코드 변경
└─ Codeflow에서 리뷰와 자동화 실행
└─ Deployflow에서 배포 상태 확인 및 클러스터 반영
개발자는 Codeflow에서 코드 변경과 워크플로우 실행 결과를 확인하고, 운영자는 Deployflow에서 배포 대상과 동기화 상태를 점검합니다. 덕분에 “코드가 바뀌었다”와 “운영 환경에 반영됐다” 사이의 과정을 더 일관된 방식으로 따라갈 수 있습니다.
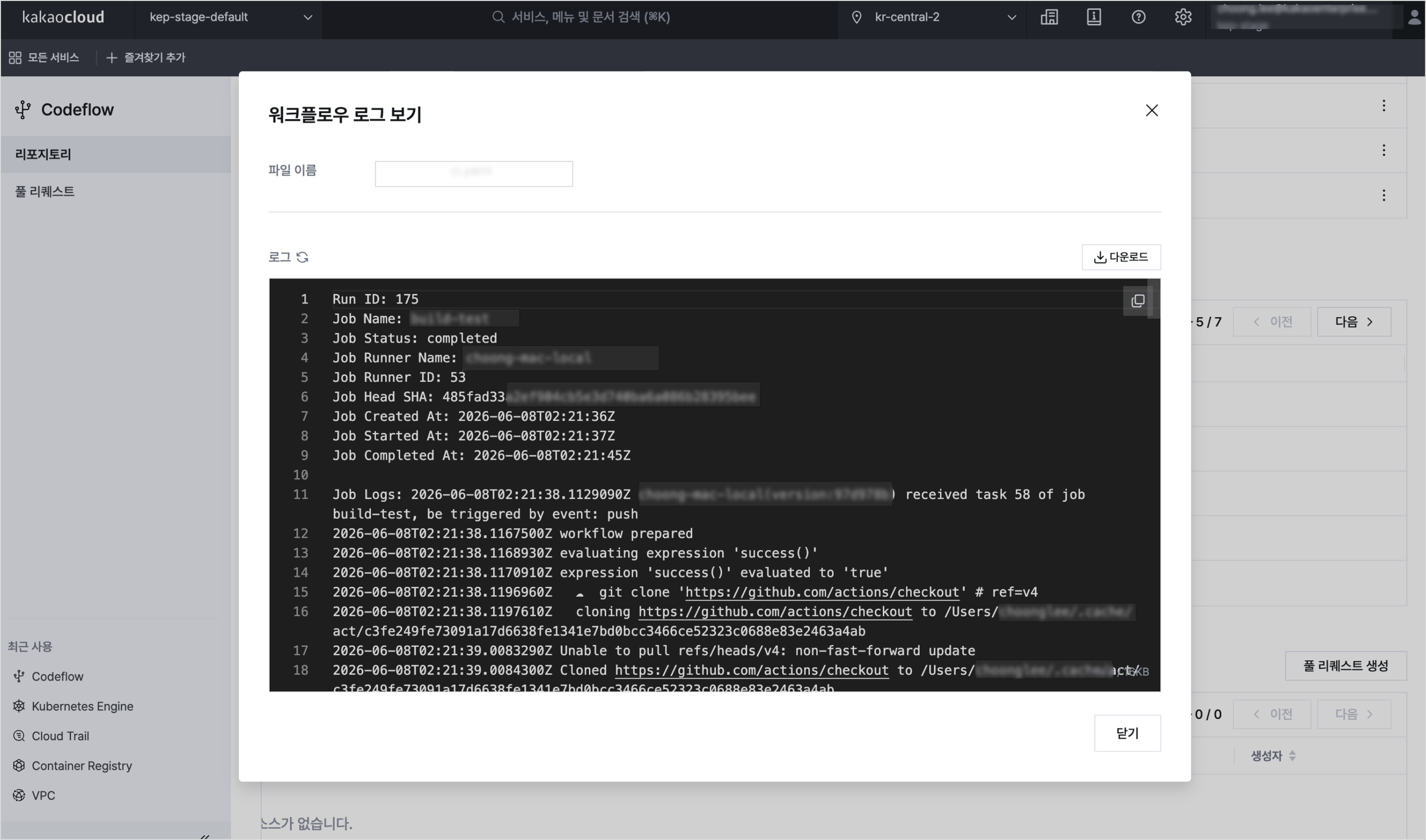 Codeflow 워크플로우 실행 로그 예시
Codeflow 워크플로우 실행 로그 예시
Codeflow: 코드 관리와 자동화
Codeflow는 소스 코드 관리와 개발 작업 자동화를 시작하는 공간입니다. 리포지토리에서 소스 코드와 설정 파일을 관리하고, 브랜치와 태그로 변경 범위를 구분하며, 풀 리퀘스트로 리뷰와 병합 절차를 운영할 수 있습니다.
또한 워크플로우와 self-hosted 러너를 사용해 반복 작업을 자동화할 수 있습니다. 워크플로우 파일은 리포지토리의 .codeflow/workflows 경로에 YAML 형식으로 정의하고, 러너는 사용자가 준비한 실행 환경에서 작업을 수행합니다. 빌드, 테스트, 이미지 생성, 매니페스트 수정처럼 배포 전후에 필요한 작업을 자동화하는 데 활용할 수 있습니다.
이처럼 Codeflow는 코드 저장소 역할에 머무르지 않고, 코드 변경 이후 필요한 자동화 작업까지 한 과정 안에서 이어갈 수 있도록 돕습니다.
Deployflow: 배포 상태와 전략 관리
Deployflow는 배포 운영의 중심입니다. 애플리케이션을 기준으로 배포 대상 클러스터, 네임스페이스, 소스 리포지토리, 배포 방식, 승인 설정을 관리합니다. Raw Manifest, Kustomize, Helm 차트와 같은 쿠버네티스 표준 구성 방식을 사용할 수 있고, Codeflow 리포지토리에 저장된 매니페스트를 배포 소스로 연결할 수 있습니다.
배포가 실행된 뒤에는 동기화 상태와 리소스 상태를 살펴볼 수 있습니다. 목표 매니페스트와 현재 클러스터 상태가 다른 경우 변경 사항을 비교해 반영하고, 승인 프로세스를 설정하면 동기화 또는 롤백 실행 전에 리뷰어가 변경 내용을 검토하도록 구성할 수 있습니다.
또한 Deployflow는 배포 전략과 히스토리를 함께 다룹니다. Blue/Green, Canary 같은 전략을 사용해 새 버전을 단계적으로 반영하고, 토폴로지와 히스토리에서 리소스 관계, 리비전, 실패 사유, 이전 배포 내역을 확인할 수 있습니다.
이처럼 Deployflow는 “배포 실행”뿐 아니라 배포 전 검토, 배포 중 상태 확인, 배포 후 이력 관리까지 운영 관점에서 필요한 정보를 함께 다룰 수 있도록 설계되었습니다.
튜토리얼로 직접 구성해 보기
CI/CD는 직접 연결해 보는 편이 훨씬 빠르게 감이 잡힙니다. 이번 출시와 함께 기본 파이프라인을 구성하는 실습형 튜토리얼도 준비했습니다.
Codeflow와 Deployflow로 CI/CD 파이프라인 구축 튜토리얼에서는 Codeflow 리포지토리, Codeflow 워크플로우, self-hosted 러너, Container Registry, Deployflow Raw Manifest 배포를 연결합니다.
실습은 예제 애플리케이션을 Codeflow 리포지토리에 올리는 것부터 시작합니다. 이후 워크플로우와 self-hosted 러너를 구성해 컨테이너 이미지를 빌드하고, 빌드한 이미지는 Container Registry에 저장합니다. 마지막으로 Deployflow 애플리케이션에서 리포지토리의 매니페스트 경로를 배포 소스로 연결하면, 코드 변경이 클러스터 배포로 이어지는 과정을 한 번에 따라가 볼 수 있습니다.
📦 예제 애플리케이션 준비
└─ Codeflow 리포지토리에 코드와 매니페스트 푸시
└─ ⚙️ 워크플로우와 self-hosted 러너 구성
└─ 🏗️ 이미지 빌드 및 Container Registry 푸시
└─ 🚀 Deployflow로 Kubernetes Engine 클러스터 배포
튜토리얼을 마치면 Codeflow에서 시작한 변경이 Deployflow를 거쳐 Kubernetes Engine 클러스터에 반영되는 과정을 직접 확인할 수 있습니다. 두 서비스를 처음 연결하는 사용자라면 이 튜토리얼을 먼저 살펴보는 것을 권장합니다.
🔵Blue / 🟢Green 배포 전략까지
기본 CI/CD 파이프라인을 구성했다면, 다음 단계는 새 버전을 더 안전하게 배포하는 방법을 확인하는 것입니다. 운영 환경에서는 새 버전을 배포한 즉시 전체 트래픽을 넘기기보다, 별도의 버전으로 먼저 준비하고 상태를 검증한 뒤 트래픽을 전환하는 전략이 필요할 수 있습니다.
Deployflow로 Blue/Green 배포 전략 구현 튜토리얼은 앞선 CI/CD 튜토리얼에서 만든 cicd-app-demo 애플리케이션을 그대로 이어서 사용합니다. Blue 버전이 현재 트래픽을 처리하는 동안 Green 버전을 새로 배포하고, 준비 상태를 확인한 뒤 트래픽을 전환하는 과정을 실습합니다.
🔵 Blue 버전 운영 중
└─ 🟢 Green 버전 준비
└─ Green Pod 상태 검증
└─ 🔁 트래픽 스위칭
└─ ✅ Green 버전 승격
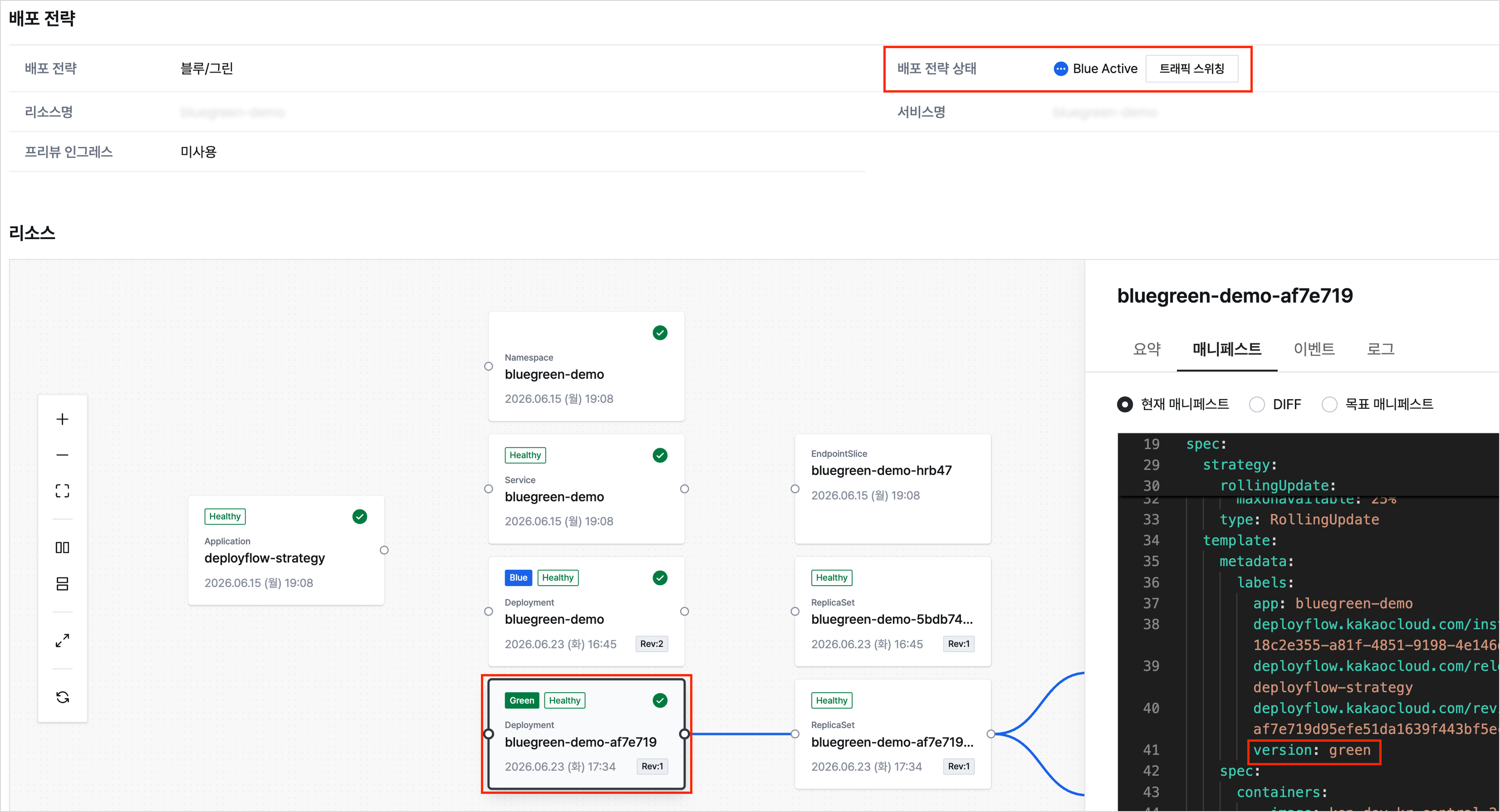 Deployflow 배포 전략 화면 예시
Deployflow 배포 전략 화면 예시
이 과정에서 기존 버전을 유지한 채 새 버전을 준비하고, 상태를 점검한 뒤 같은 서비스 엔드포인트에서 트래픽 대상을 전환하는 방식을 확인할 수 있습니다. 기본 배포 자동화에서 한 걸음 더 나아가, 배포 전략을 실제 운영 절차와 어떻게 연결할 수 있는지 살펴보고 싶다면 이 튜토리얼을 이어서 진행해 보세요.
지금 바로 시작하기
Codeflow와 Deployflow를 처음 사용한다면 먼저 Codeflow와 Deployflow로 CI/CD 파이프라인 구축 튜토리얼로 기본 파이프라인을 구성해 보세요. 이후 같은 예제 애플리케이션으로 Deployflow로 Blue/Green 배포 전략 구현 튜토리얼을 이어가면, 기본 배포 자동화에서 트래픽 전환 전략까지 자연스럽게 확장할 수 있습니다.
Codeflow와 Deployflow는 카카오클라우드에서 애플리케이션을 개발하고 배포하는 과정을 더 명확하게 연결하기 위한 Developer Tools 서비스입니다. 앞으로도 카카오클라우드는 코드 변경, 자동화, 배포, 운영 점검이 자연스럽게 이어질 수 있도록 개발 및 배포 도구를 지속적으로 고도화해 나가겠습니다.



 AI Insight > Overview
AI Insight > Overview AI Insight > GPU Explorer > GPU 모니터링
AI Insight > GPU Explorer > GPU 모니터링








 위젯 기반의 대시보드 구성
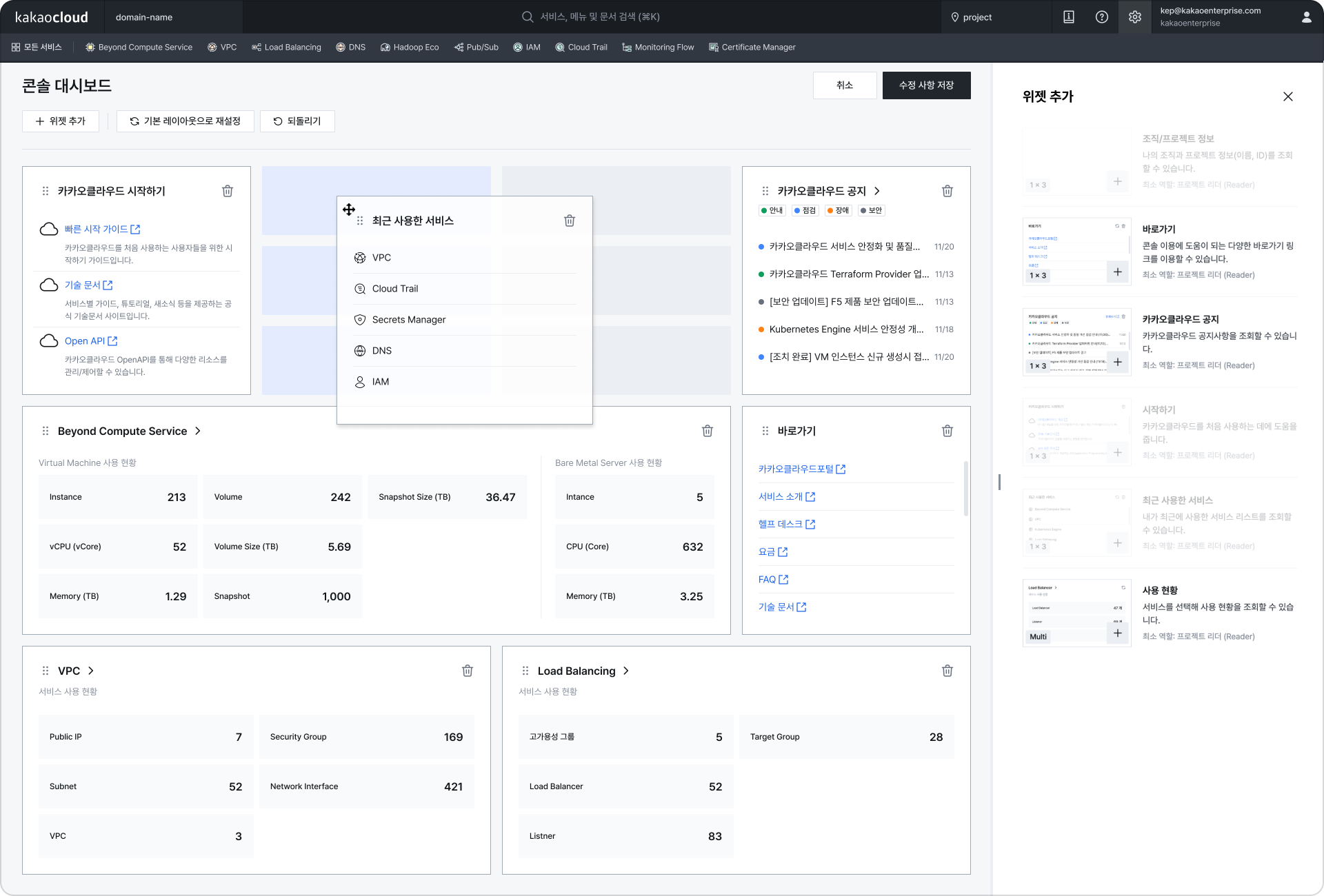
위젯 기반의 대시보드 구성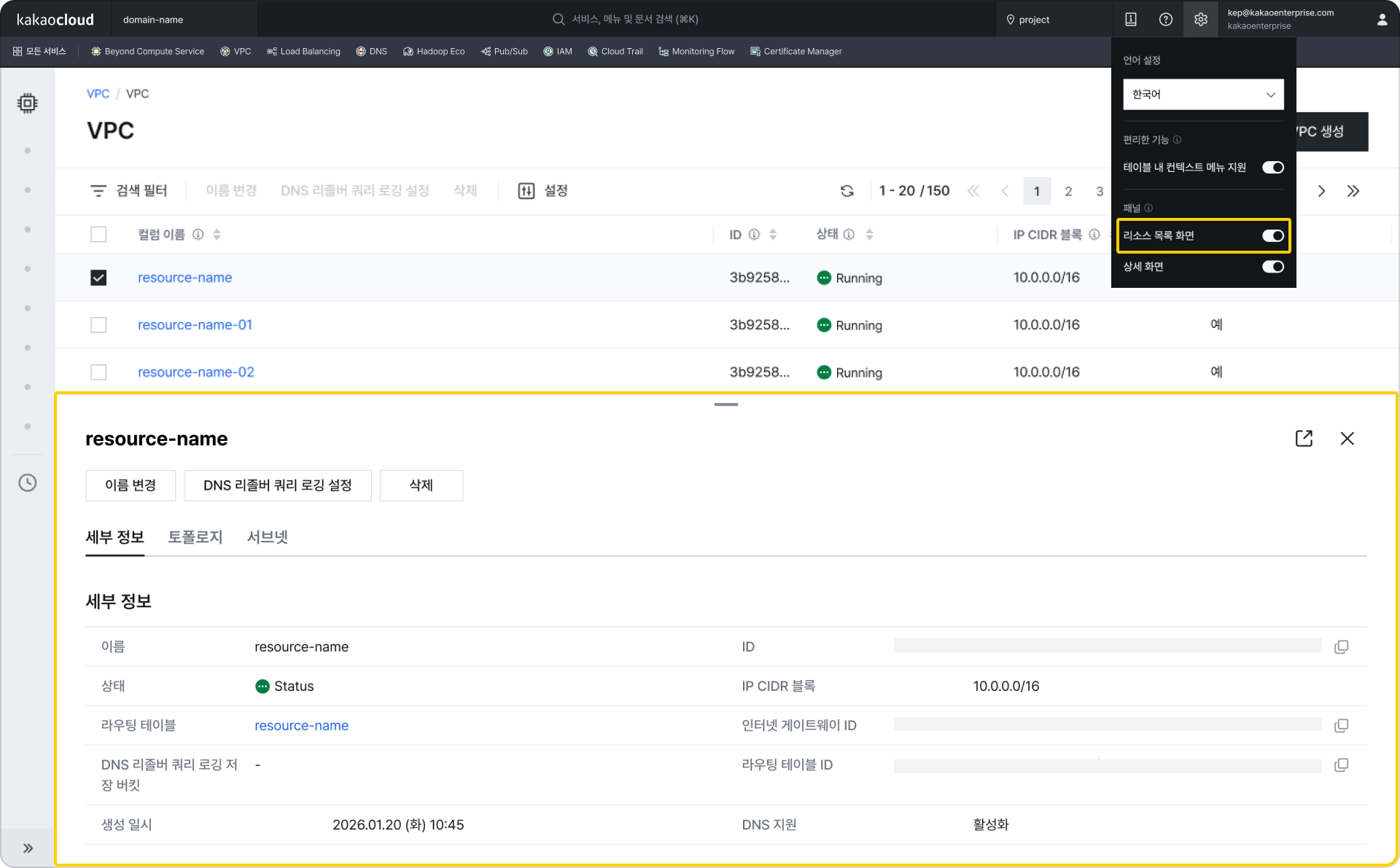 하단 패널 표시(우측 상단 설정 > 리소스 목록 화면 옵션 활성화 시)
하단 패널 표시(우측 상단 설정 > 리소스 목록 화면 옵션 활성화 시)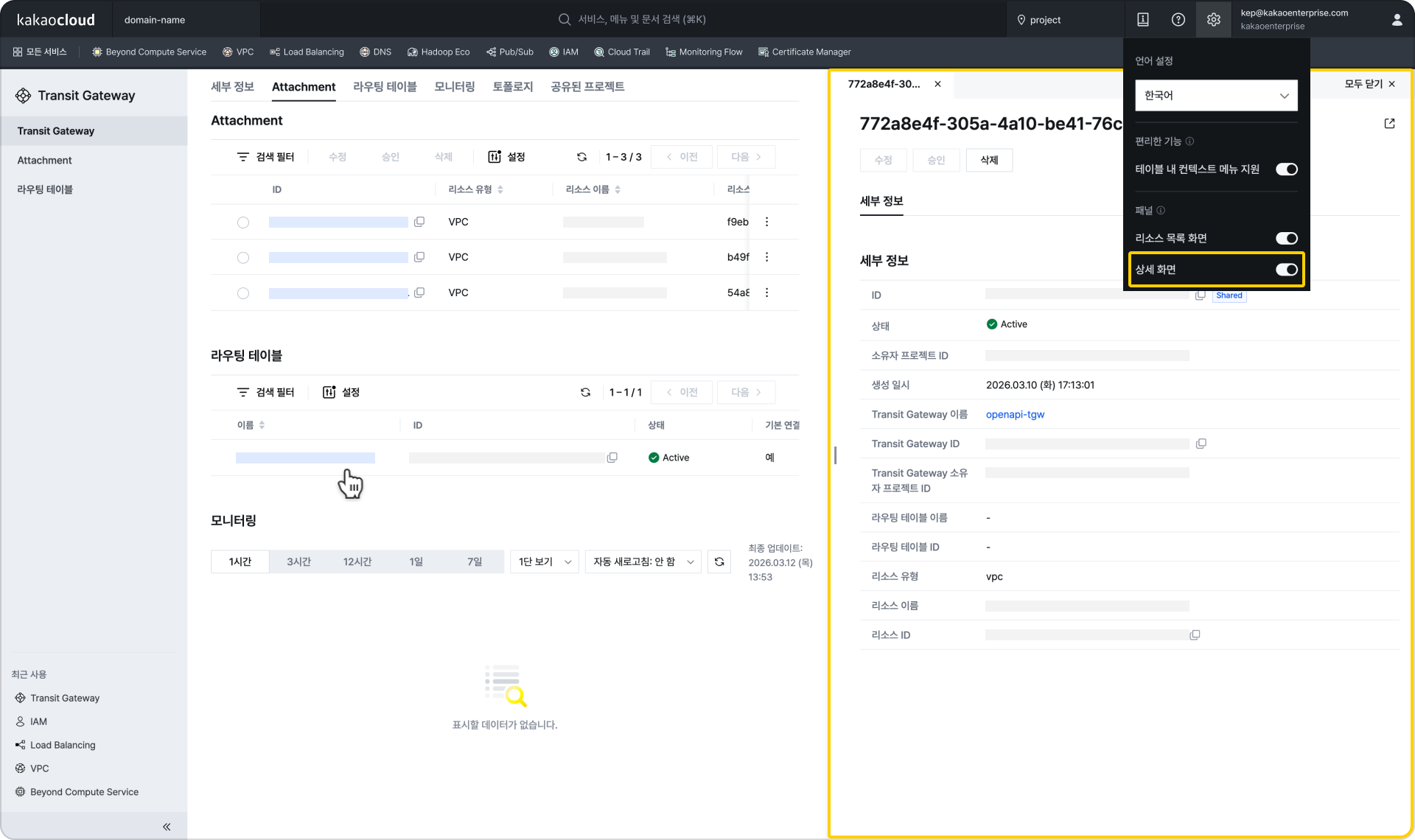 우측 패널 표시(우측 상단 설정 > 상세 화면 옵션 활성화 시)
우측 패널 표시(우측 상단 설정 > 상세 화면 옵션 활성화 시)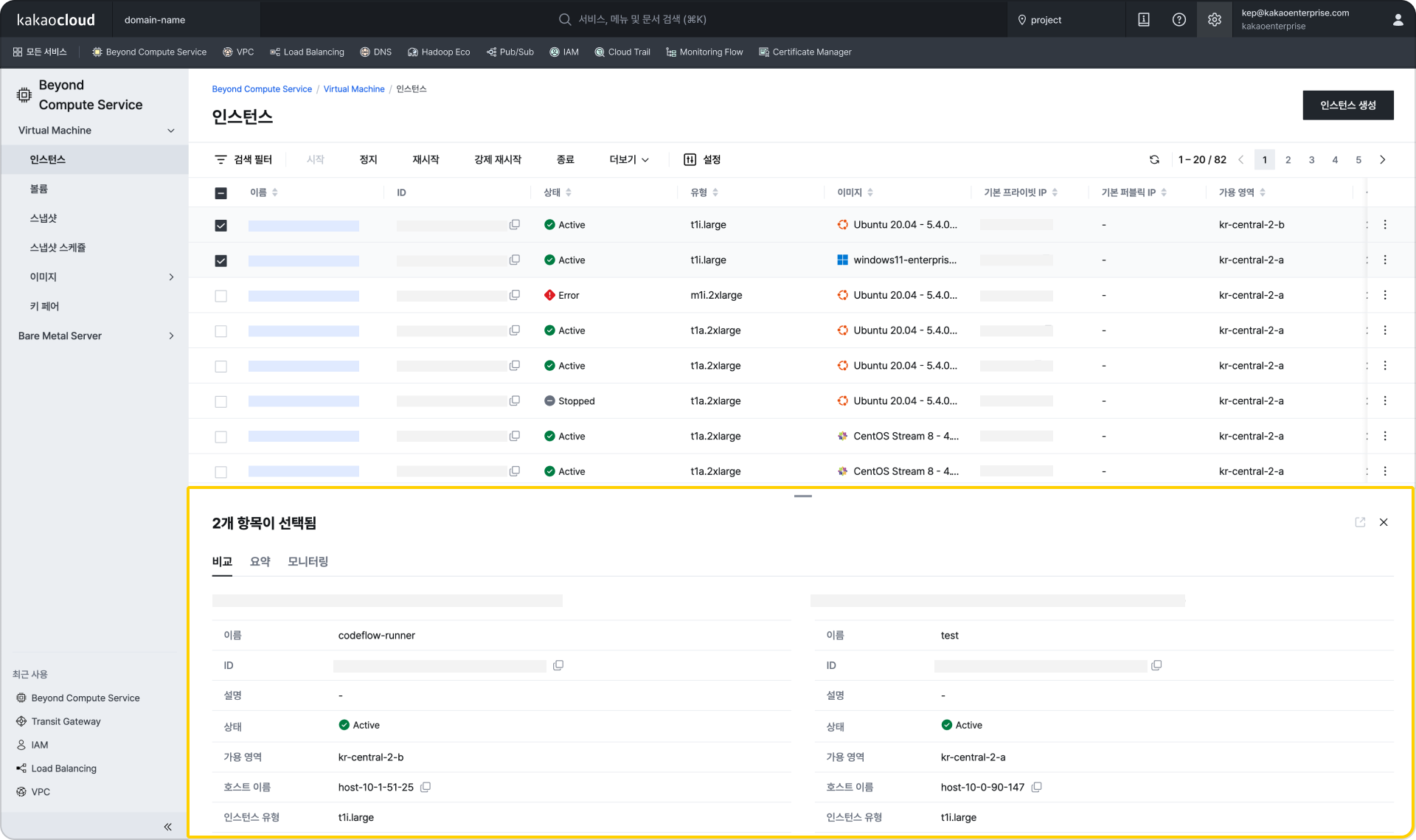 리소스 2개를 선택 시 하단 패털에서 상세 정보 조회
리소스 2개를 선택 시 하단 패털에서 상세 정보 조회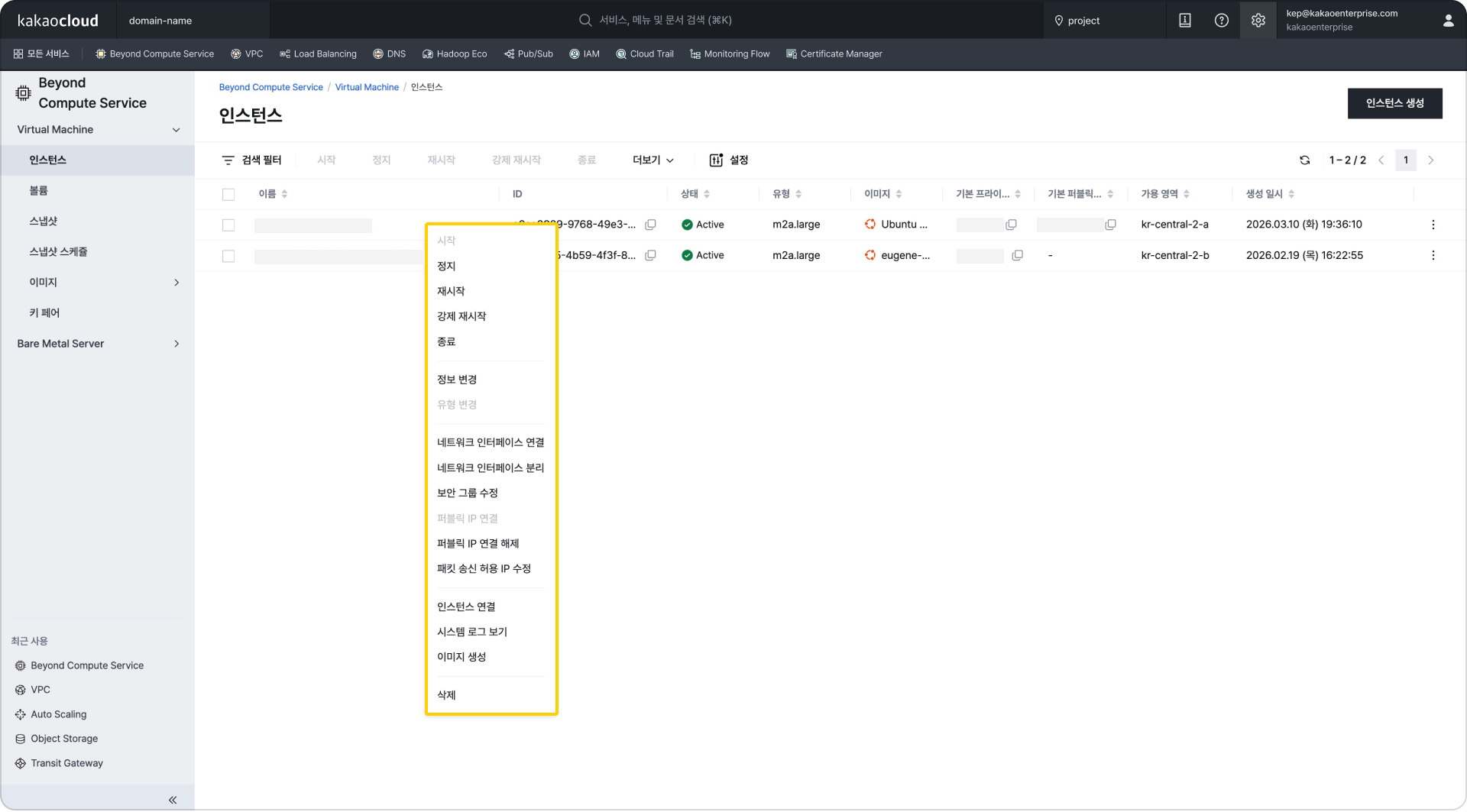 테이블 내 컨텍스트 메뉴 지원 (우측 상단 설정 > 테이블 내 컨텍스트 메뉴 지원 활성화 시)
테이블 내 컨텍스트 메뉴 지원 (우측 상단 설정 > 테이블 내 컨텍스트 메뉴 지원 활성화 시)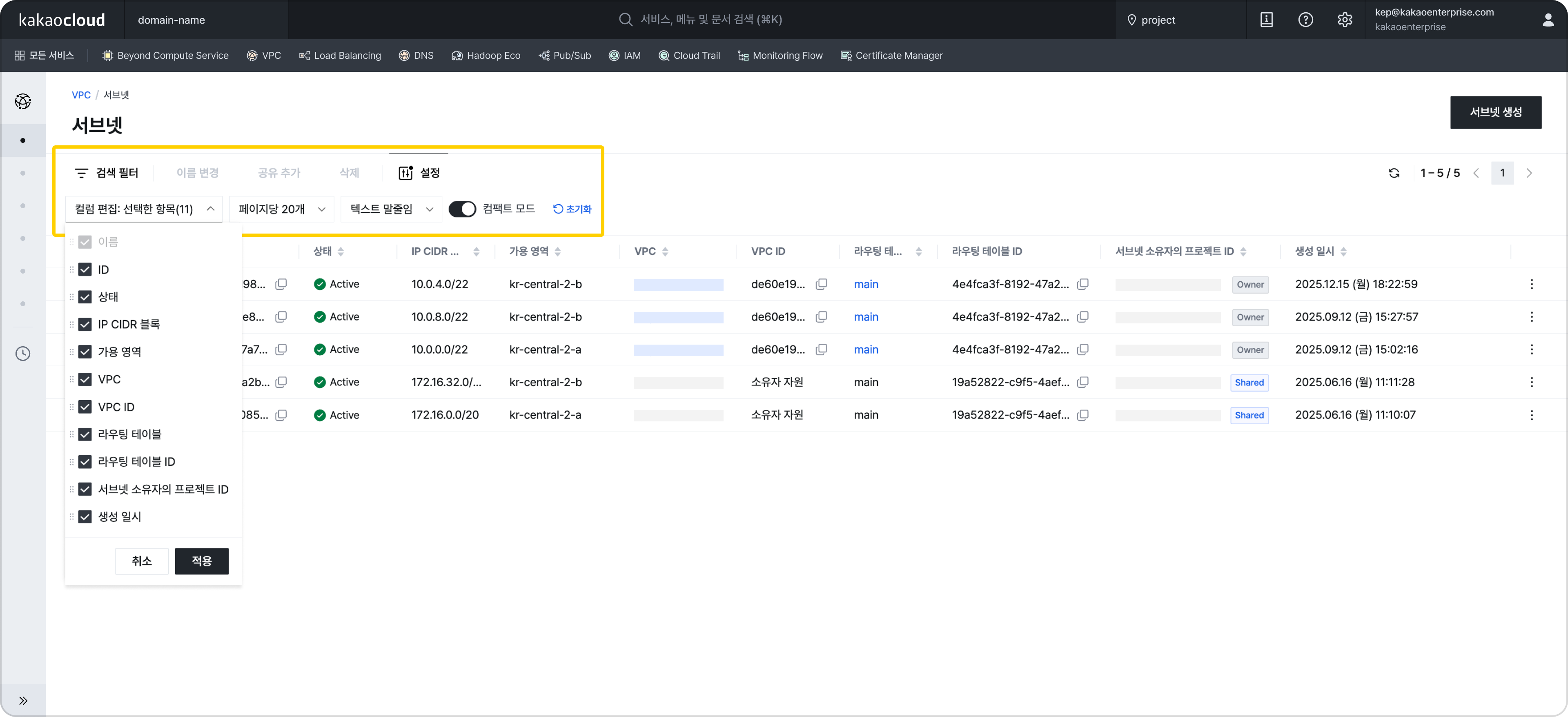 리소스 목록 화면
리소스 목록 화면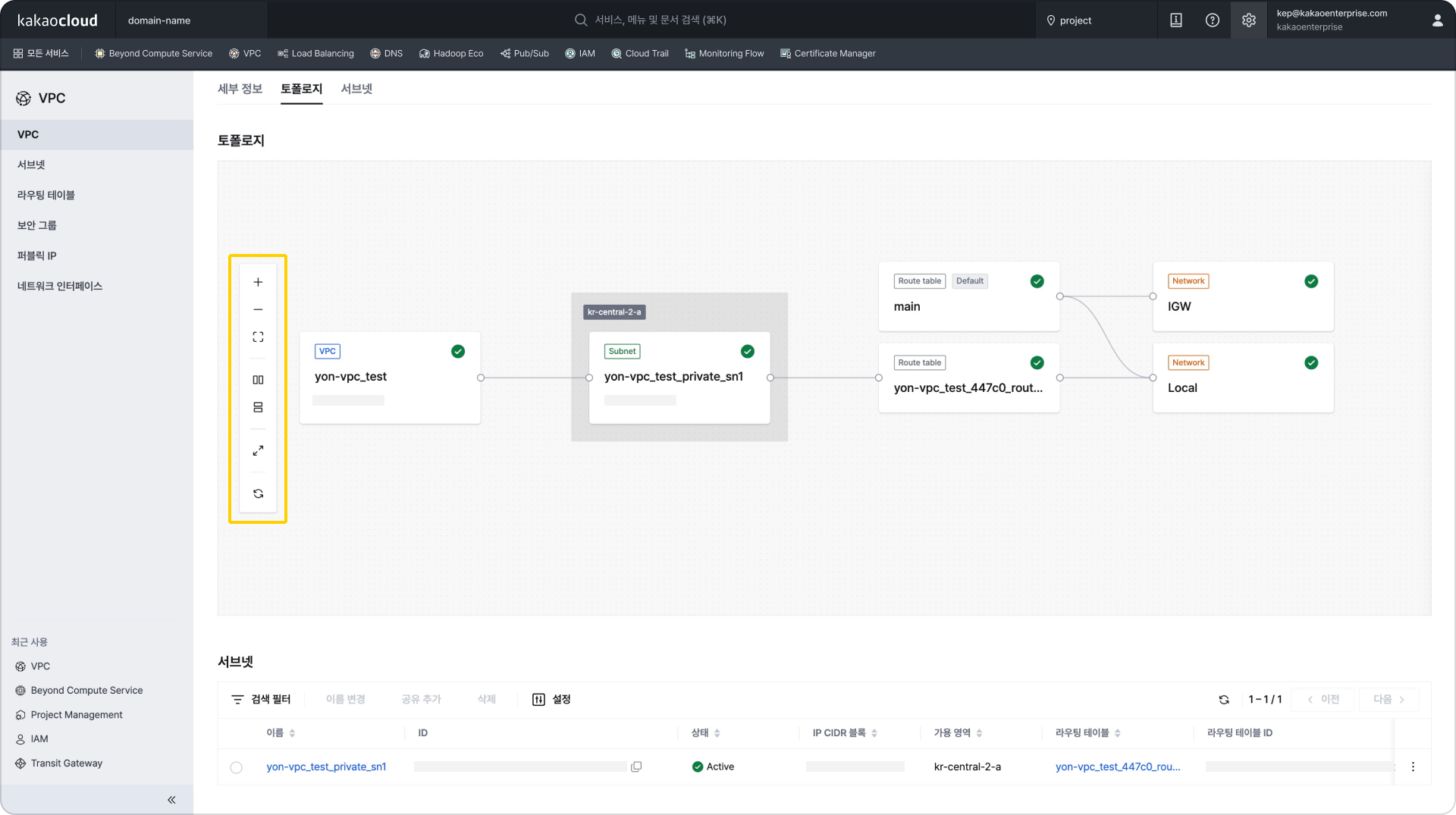 확대/축소, 정렬 기능 등이 추가된 토폴로지
확대/축소, 정렬 기능 등이 추가된 토폴로지 접기/펼치기 기능
접기/펼치기 기능

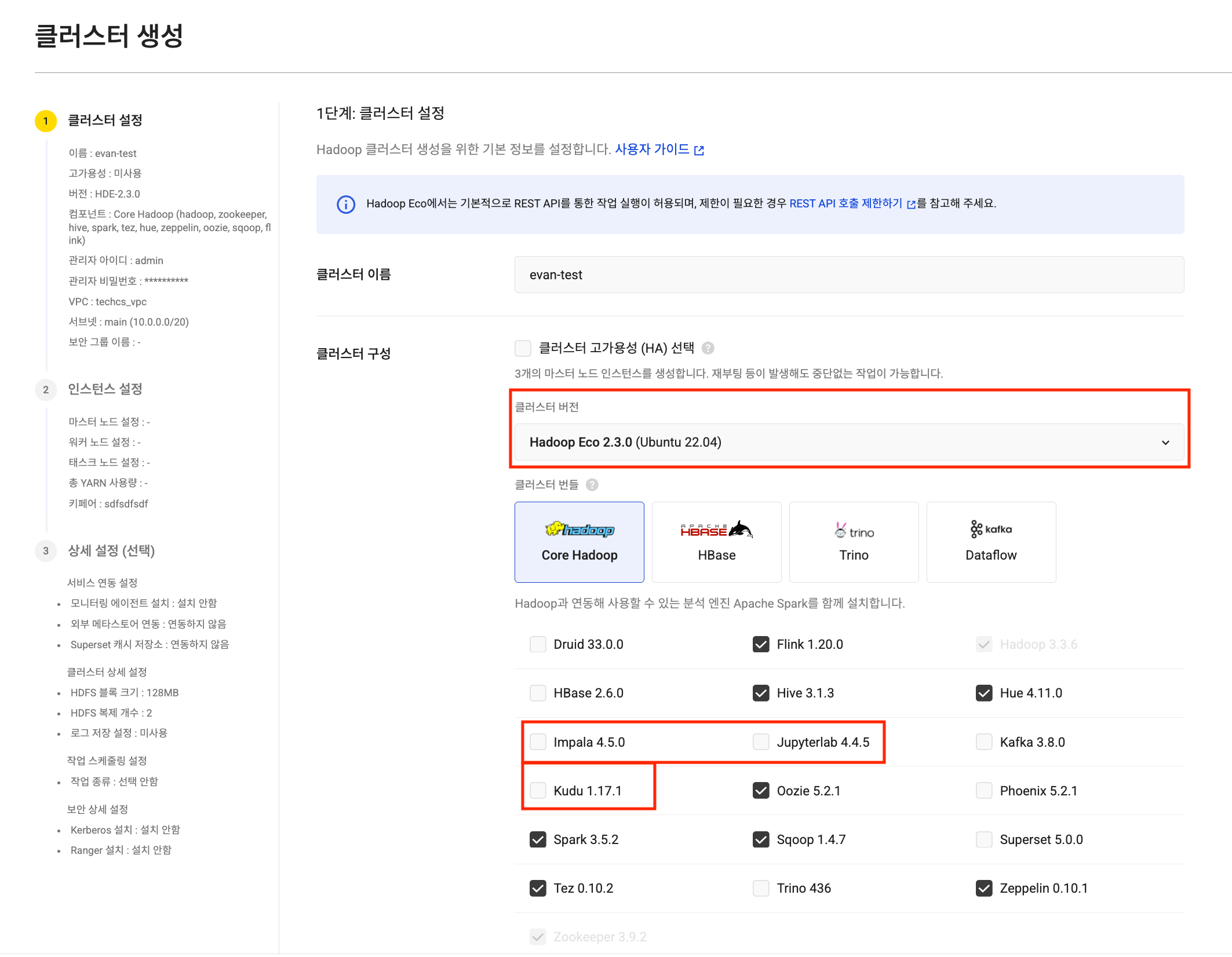 HDE 클러스터 생성
HDE 클러스터 생성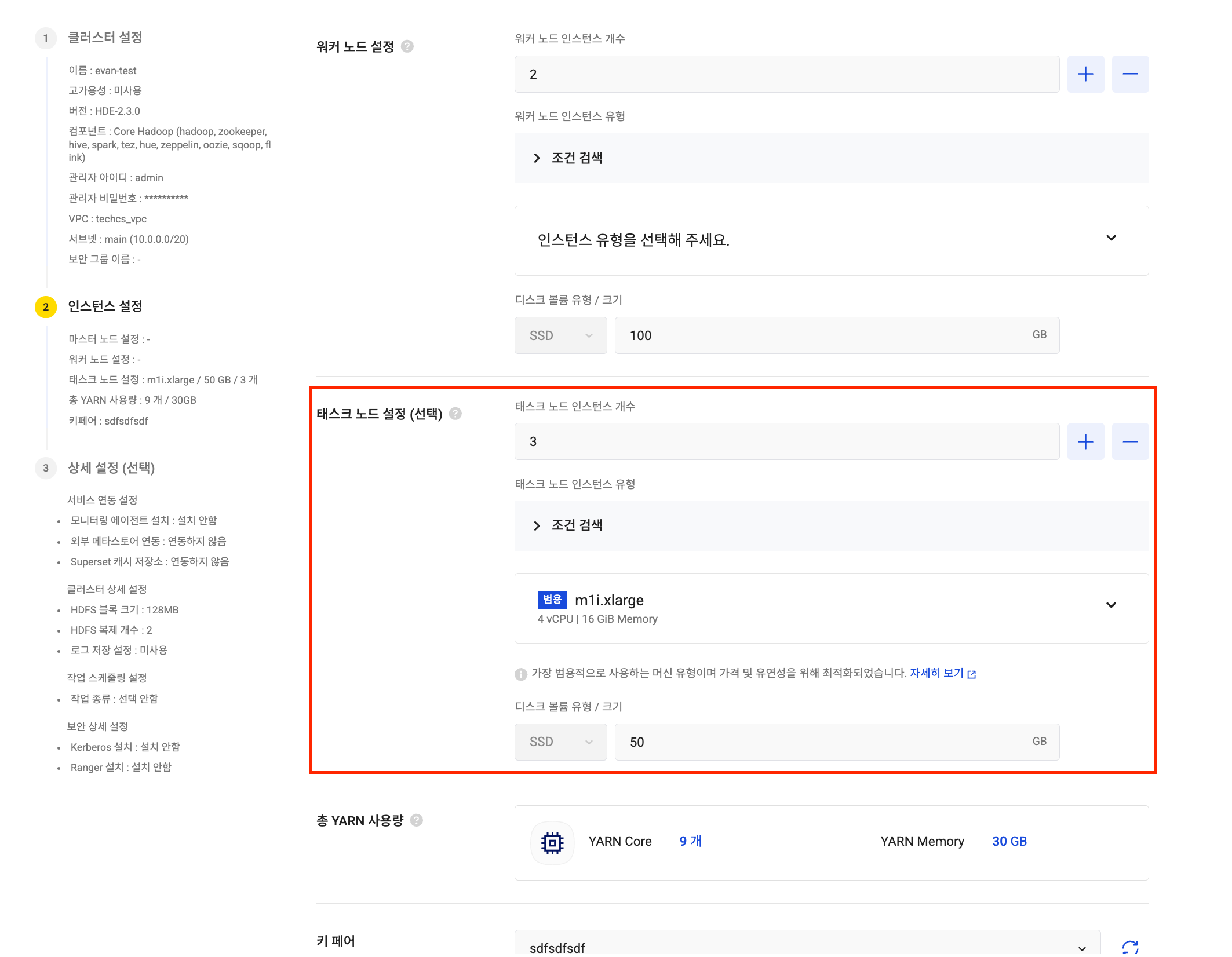 태스크 노드 설정
태스크 노드 설정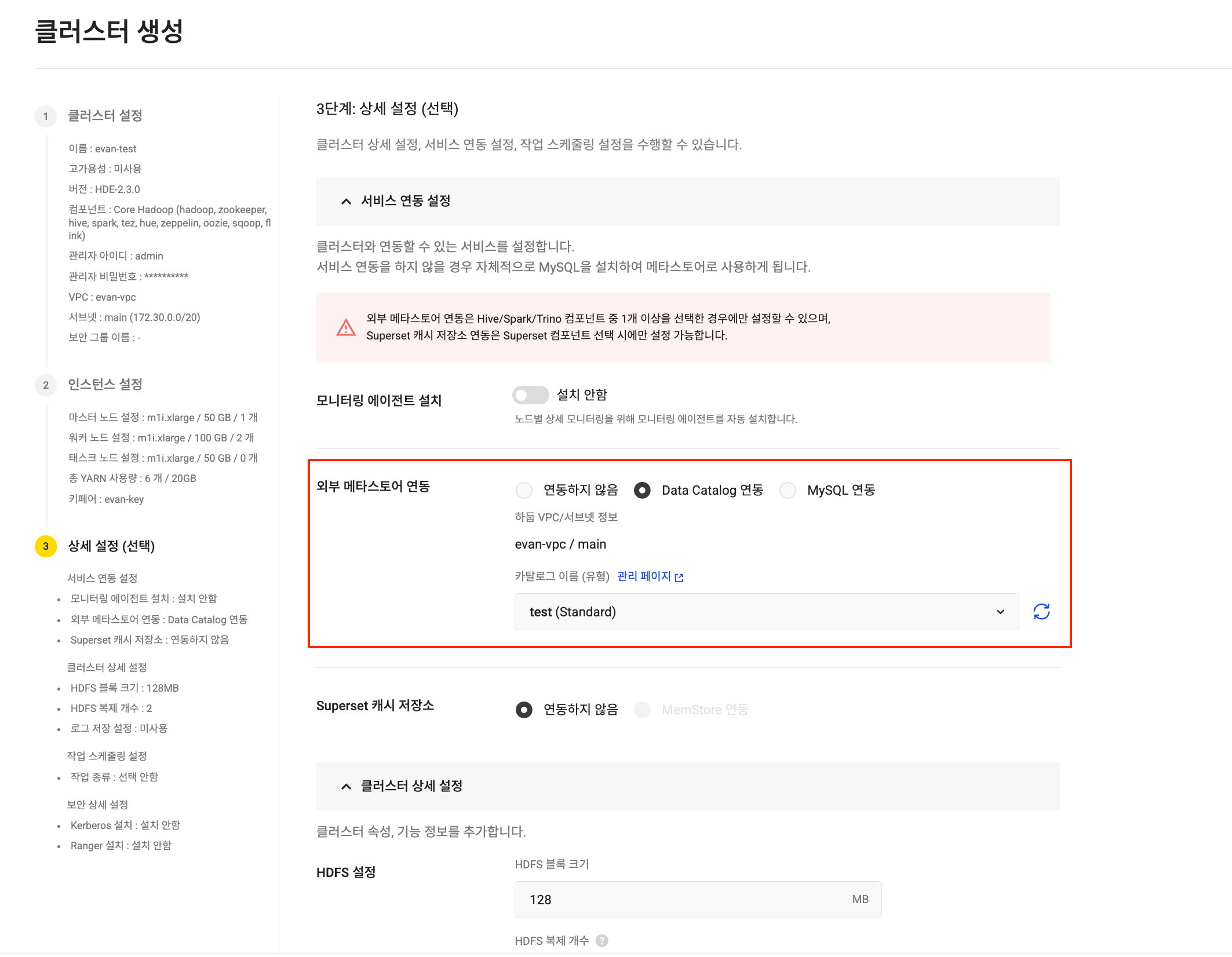 Iceberg 카탈로그 연동
Iceberg 카탈로그 연동