카카오클라우드 서비스 소식 - VM·Hadoop 성능 개선, IAM 보안 설정 등


올 해도 카카오클라우드는 사용자 여러분께 더 편리하고 안전한 클라우드 환경을 제공하기 위해 쉼 없이 달리고 있는데요, 따스한 봄기운과 함께 찾아온 3월의 주요 서비스 업데이트 소식을 모아서 전해드립니다.
최근 안내해 드린 사용자 중심의 콘솔 개편이 대대적인 화면 구조와 경험(UX)의 변화였다면, 이번에는 내실을 다지는 서비스 기능 강화 소식에 초점을 맞췄습니다. 시스템 안정성을 높이기 위한 작업과 더불어, 리소스 관리 효율성과 보안성을 한층 높인 이번 업데이트의 상세 내용을 확인해 보세요.
🖥️ 인프라 관리 효율성 및 서비스 확장성
-
GPU 서비스, Virtual Machine(VM)으로 통합: 더욱 직관적인 리소스 관리를 위해 기존에 별도로 운영되던 GPU 서비스가 Virtual Machine 서비스 내로 통합되었습니다.
- 통합 환경 제공: 이제 VM 생성 단계에서 일반 인스턴스와 GPU 인스턴스를 동일한 워크플로우 내에서 선택하고 관리할 수 있습니다.
- 알림 정책 자동 전환: 서비스 통합에 따라 기존 GPU 서비스에서 설정했던 Alert Center의 알림 정책들은 Virtual Machine 서비스의 정책으로 안전하게 자동 전환되었습니다. 별도의 재설정 없이 기존의 모니터링 환경을 그대로 이용하실 수 있습니다.
-
Virtual Machine, t1i 인스턴스 '시작 크레딧' 지원: 워크로드 처리 효율을 높이기 위해 버스터블 인스턴스인
t1i유형에 시작 크레딧 기능이 추가되었습니다. 이제 인스턴스 부팅 시 일시적으로 높은 CPU 사용률을 유지할 수 있어, 초기 구동 속도가 획기적으로 빨라졌습니다. -
Hadoop Eco, 노드 볼륨 최대 16TB로 확장: 대용량 데이터 분석을 지원하기 위해 Hadoop Eco 서비스의 노드별(마스터, 워커, 태스크) 최대 볼륨 크기를 기존 5TB에서 최대 16TB로 대폭 상향했습니다. 스토리지 제약 없이 더 방대한 데이터를 분석해 보세요.
-
Object Storage 상품명 변경: 사용자가 이용 중인 스토리지 서비스를 쉽게 인지할 수 있도록 Object Storage의 상품명이 다음과 같이 변경되었습니다. 가격은 기존과 동일하며, 3월 빌링 청구서부터 순차적으로 적용됩니다.
- 데이터 용량: Hot Bucket → Standard Storage Class
- API 호출: 기존 요청 명칭 앞에 Standard- 접두사가 추가 (예: Standard-PUT, Standard-GET 등)
🔑 보안 기능 강화
-
IAM 보안 설정 강화: 조직의 소중한 자원을 보호하기 위해 다양한 보안 설정이 콘솔 내 계정 설정 및 IAM 서비스 항목에 추가되었습니다.
- 자원 삭제 시 비밀번호 재인증: 사용자 계정이나 프로젝트 서비스 계정을 삭제할 때, 단순 실수를 방지하기 위한 비밀번호 재인증 단계가 추가되었습니다.
- 세션 및 토큰 즉시 만료 옵션: 비밀번호 변경 시, 기존에 로그인된 모든 세션과 발급된 액세스 토큰을 즉시 무효화할 수 있습니다. 계정 유출이 의심되는 긴급 상황에서 보안 사고에 빠르게 대처할 수 있습니다.
- Cloud Trail 감사 로그 확대: 보안 정책 및 계정 관리 이력을 상세히 추적할 수 있도록 17종의 신규 이벤트가 추가되었습니다.
🛠️ 개발 편의성 향상
- OpenAPI MySQL 신규 지원: 개발자를 위한 OpenAPI 지원 범위가 한층 넓어졌습니다. 이번 업데이트로 MySQL OpenAPI가 새롭게 추가되어, 카카오클라우드 MySQL 서비스를 API로 직접 제어하고 관리 자동화에 활용할 수 있습니다. OpenAPI와 관련한 자세한 업데이트는 OpenAPI Changelogs에서 확인하실 수 있습니다.
이번에 전해드릴 소식은 여기까지 입니다. 소개해 드린 기능 개선 외에도 각 서비스의 상세한 변경 사항과 이전 업데이트 이력은 기술문서 내 서비스별 릴리즈 노트에서 확인하실 수 있습니다.
카카오클라우드는 앞으로도 안정적인 인프라와 사용자 중심의 기능을 제공하기 위해 최선을 다하겠습니다.
서비스 이용과 관련하여 궁금하신 사항은 언제든 카카오클라우드 고객지원을 통해 문의해 주시기 바랍니다.


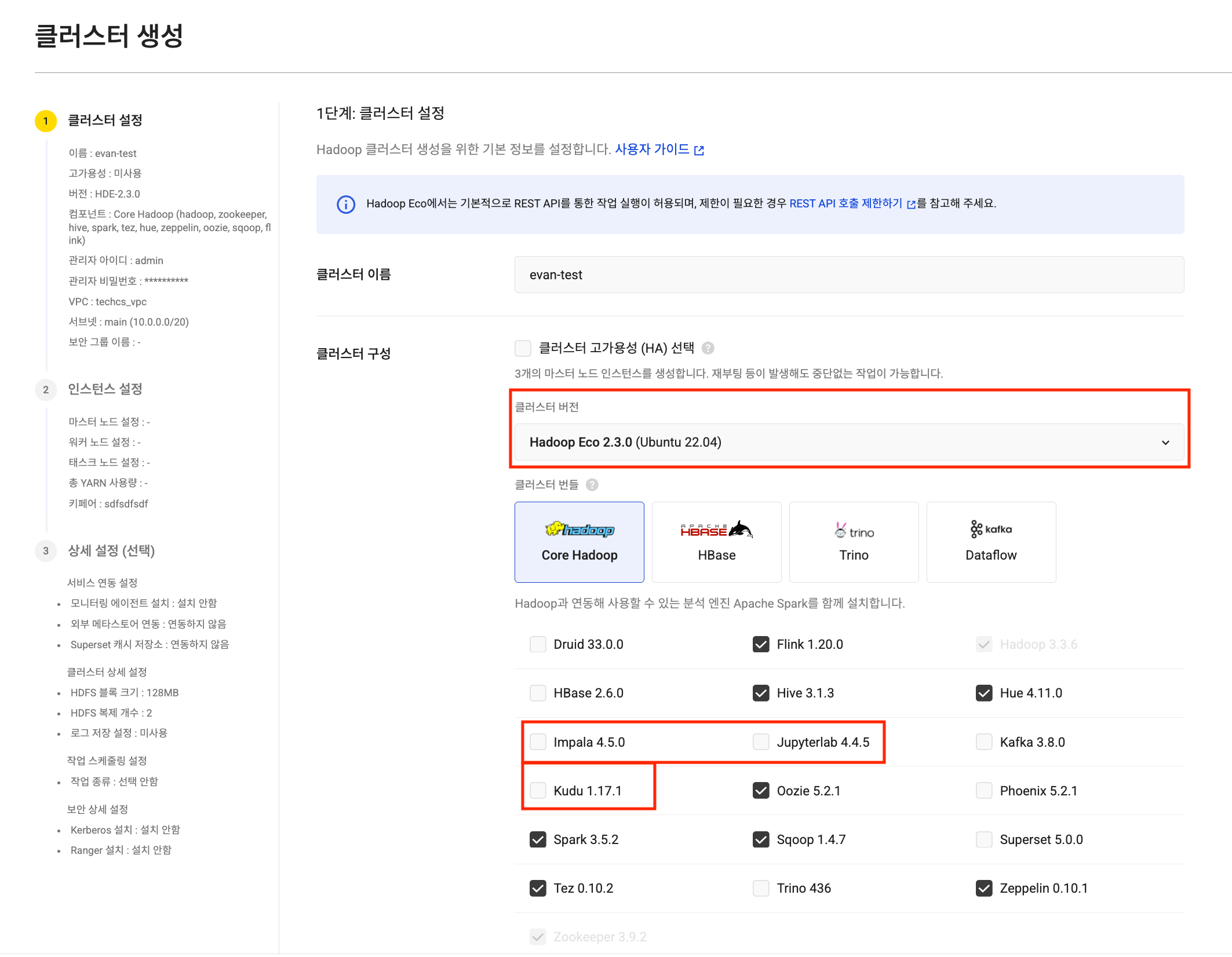 HDE 클러스터 생성
HDE 클러스터 생성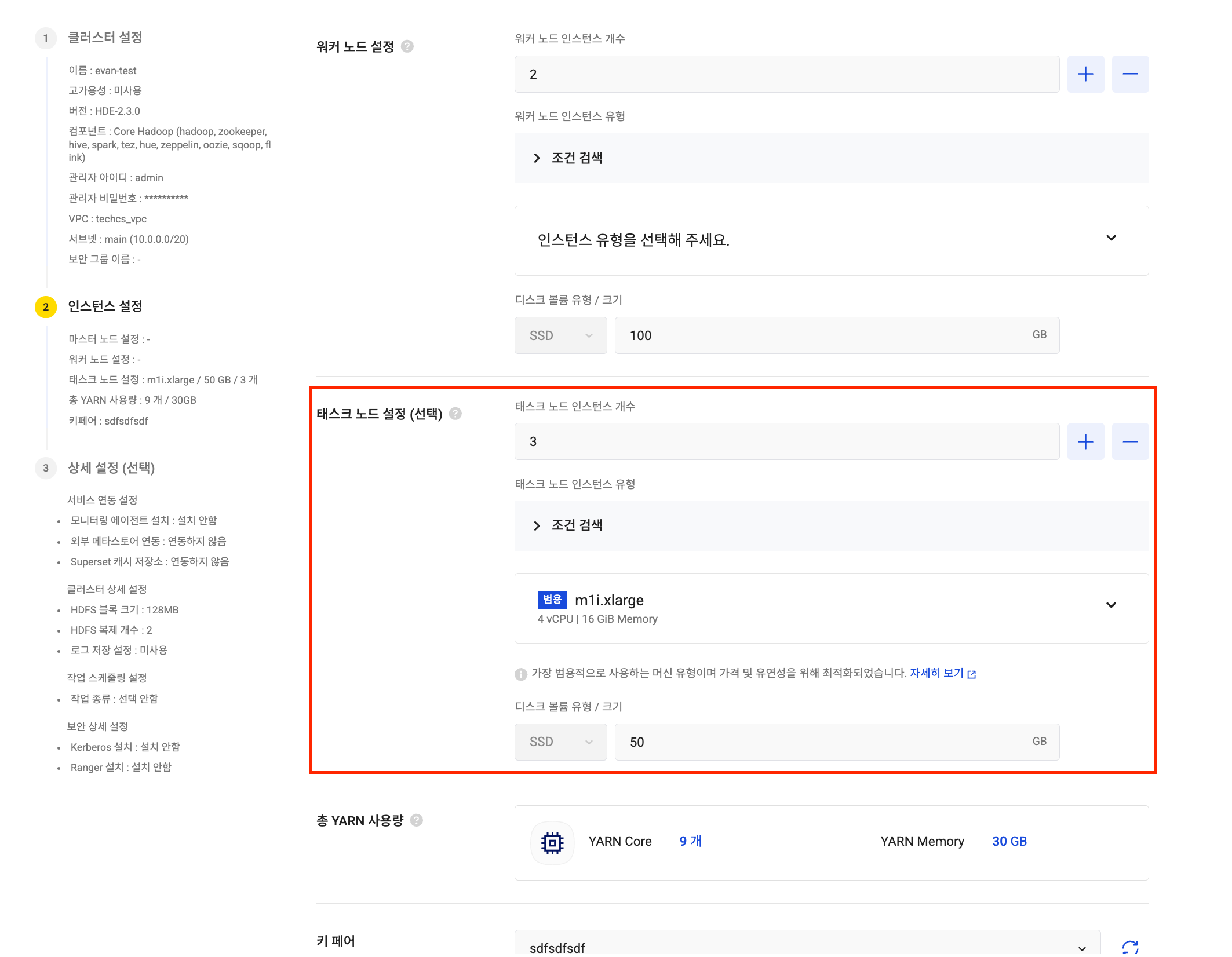 태스크 노드 설정
태스크 노드 설정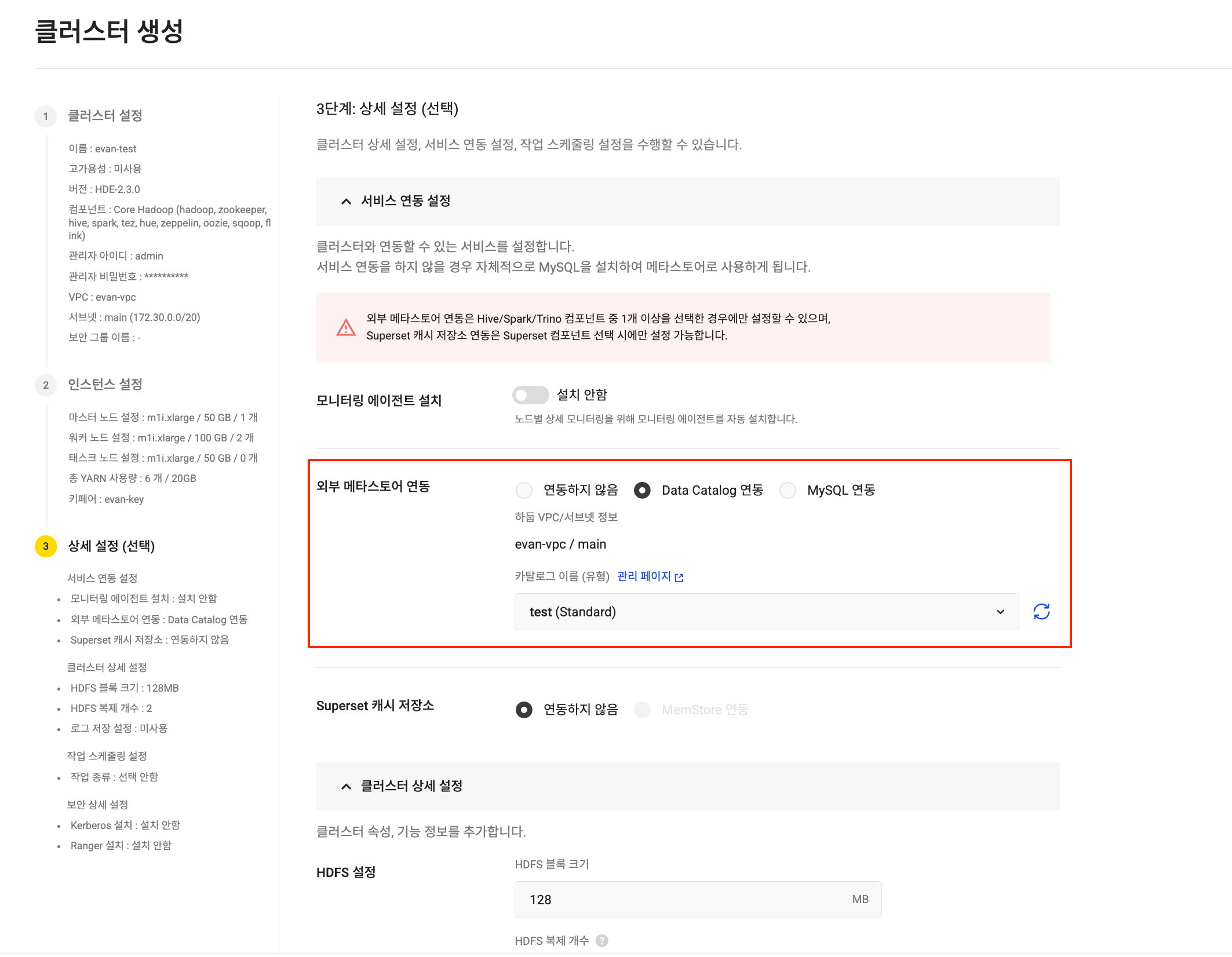 Iceberg 카탈로그 연동
Iceberg 카탈로그 연동