Kafka 기반 실시간 데이터 파이프라인 구축하기


서비스에서 발생하는 로그, 사용자 이벤트, 트랜잭션 정보. 이런 데이터는 저장도 중요하지만, 빠르게 분석할 수 있어야 진짜 ‘의미 있는 흐름’이라고 할 수 있습니다.
이번에 소개해 드리는 Kafka 기반 실시간 데이터 파이프라인 튜토리얼 시리즈는, 바로 이 '데이터의 흐름'을 카카오클라우드에서 어떻게 구현할 수 있는지를 직접 따라 해볼 수 있는 실습형 튜토리얼입니다.
이 시리즈는 총 3편으로 구성되어 있으며, 실시간 메시지 수신부터 저장, 분석까지의 전 과정을 단계적으로 안내합니다.
Kafka와 Object Storage, Data Catalog, Data Query를 연결하여, 데이터가 흐르는 전체 구조를 이해하고 직접 구현해볼 수 있는 구조로 설계되었습니다.
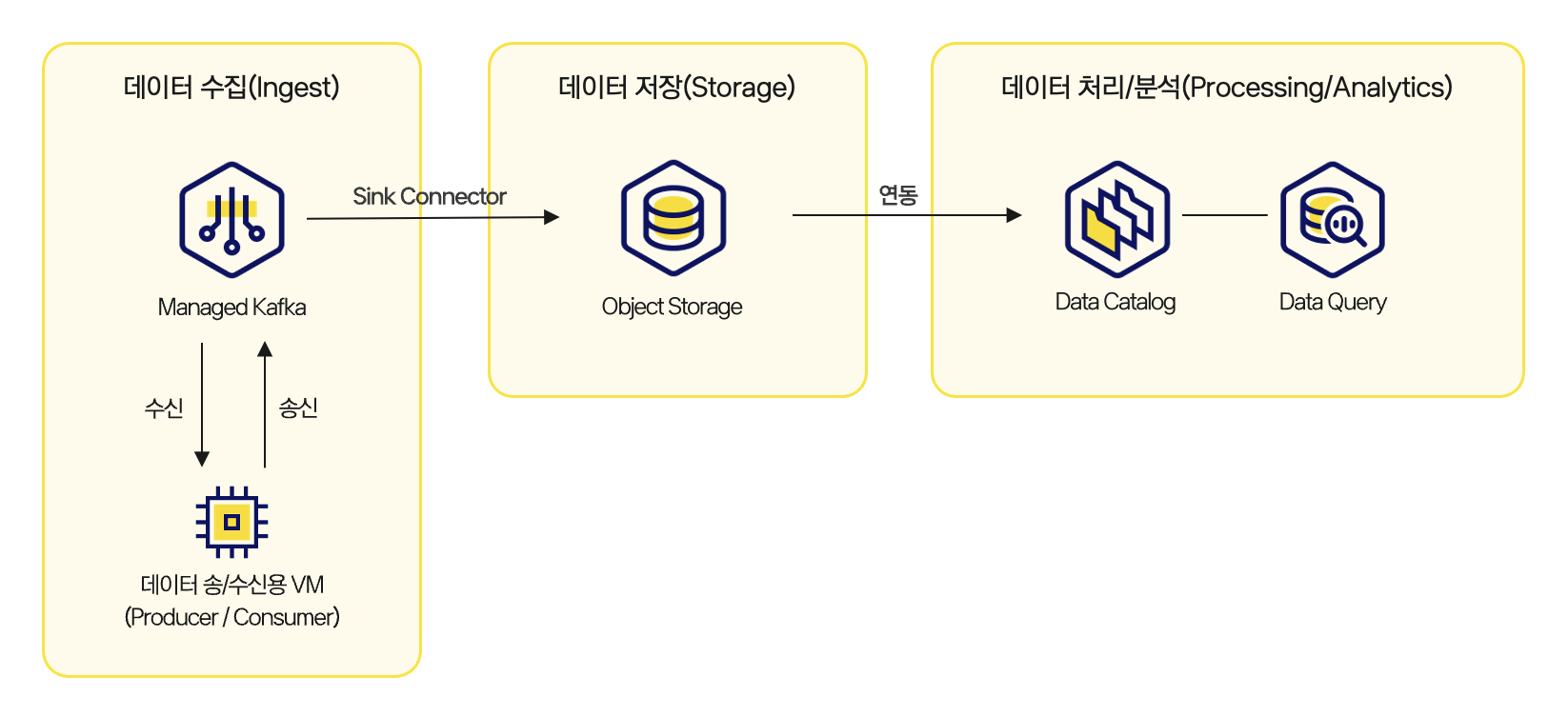 실시간 데이터 파이프라인 구축 아키텍처
실시간 데이터 파이프라인 구축 아키텍처
1편: Kafka 메시지를 수신하는 구조 만들기
첫 번째 튜토리얼에서 Kafka 클러스터를 생성하고, 토픽을 통해 메시지를 송수신하는 환경을 구성합니다. Kafka 토픽을 생성하고, 프로듀서(Producer)와 컨슈머(Consumer)를 구성한 뒤, 메시지를 송수신하며 실시간 데이터 수집 기반을 마련합니다.
이 과정은 이벤트 기반 시스템의 기본 구조를 이해하고, 메시지 흐름의 시작점을 만드는 데 초점을 맞추고 있습니다.
2편: 수신한 메시지를 Object Storage에 저장하기
두 번째 튜토리얼에서는 Kafka로 수신한 메시지를 주기적으로 수집하여 Object Storage에 저장하는 흐름을 다룹니다. 메시지를 일정 간격으로 모아 하나의 파일로 저장하고, 저장된 파일은 이후 분석을 위한 데이터 소스로 활용됩니다.
이 과정에서는 스트리밍과 배치의 경계, 그리고 파일 포맷과 구조를 어떻게 설계해야 하는지도 함께 고민해볼 수 있습니다.
👉 Kafka 데이터의 Object Storage 적재 튜토리얼 보기
3편: Data Catalog와 Data Query를 통한 실시간 분석
마지막 튜토리얼에서는 Object Storage에 저장된 데이터를 Data Catalog에 등록하고, Data Query를 통해 SQL 기반 분석을 수행할 수 있는 환경을 구성합니다. Catalog에 등록된 테이블은 파티션 기반으로 관리되며, 정기적인 동기화 설정을 통해 새로운 데이터를 자동으로 반영할 수 있습니다.
Kafka로 수집한 실시간 데이터를 별도의 복잡한 파이프라인 없이 바로 분석할 수 있는 구조로 전환하는 것이 이 단계에서 가장 중요한 부분입니다.
👉 Data Catalog와 Data Query를 이용한 Kafka 메시지 분석 튜토리얼 보기
이번 실시간 데이터 파이프라인 튜토리얼 시리즈는 단순한 코드 예제가 아니라, 운영 환경에서 그대로 활용할 수 있는 아키텍처와 설정을 바탕으로 작성되었습니다. Kafka 메시지를 수신하고, Object Storage에 저장하고, Data Catalog와 Data Query로 분석까지 연결하는 전 과정을 직접 따라 해보며, 실시간 서비스, 모니터링 시스템, 이벤트 기반 통계 파이프라인 설계에 필요한 감을 빠르게 익힐 수 있습니다.
Kafka 기반 실시간 데이터 파이프라인을 처음 설계하시거나, 기존 파이프라인을 카카오클라우드에서 확장하고자 하신다면 이 튜토리얼이 좋은 레퍼런스가 될 것입니다.
🖥️ 지금 바로 실습해 보세요!
Kakfa 기반 실시간 데이터 파이프라인 튜토리얼 시리즈 한눈에 보기


 카카오클라우드 CDC 파이프라인 아키텍처
카카오클라우드 CDC 파이프라인 아키텍처