Hadoop Eco adds features for operational efficiency in data lake architecture


When enterprises design cloud-based large-scale data lake architectures, we have reached a point where we must go beyond simply accumulating data and maximize operational efficiency. To secure efficiency, it is necessary to build a balanced set of core elements such as high-performance processing, flexible separation of compute resources, and robust data governance.
If this balance breaks down, complex problems can occur, such as real-time analytics queries being delayed by batch jobs or difficulty understanding the location and reliability of the data needed.
KakaoCloud Hadoop Eco (HDE) recently carried out a large-scale update to solve these problems and improve the processing power and operational management capabilities of analytics environments. Based on the release of the new HDE-2.3.0 version, this update includes major changes such as improved integration with Iceberg catalogs, a next-generation metastore, and the introduction of task nodes optimized for workloads.
In this post, we briefly introduce how these improvements can be used within HDE to improve analytics workflows.
🚀 New HDE-2.3.0 version and powerful components added
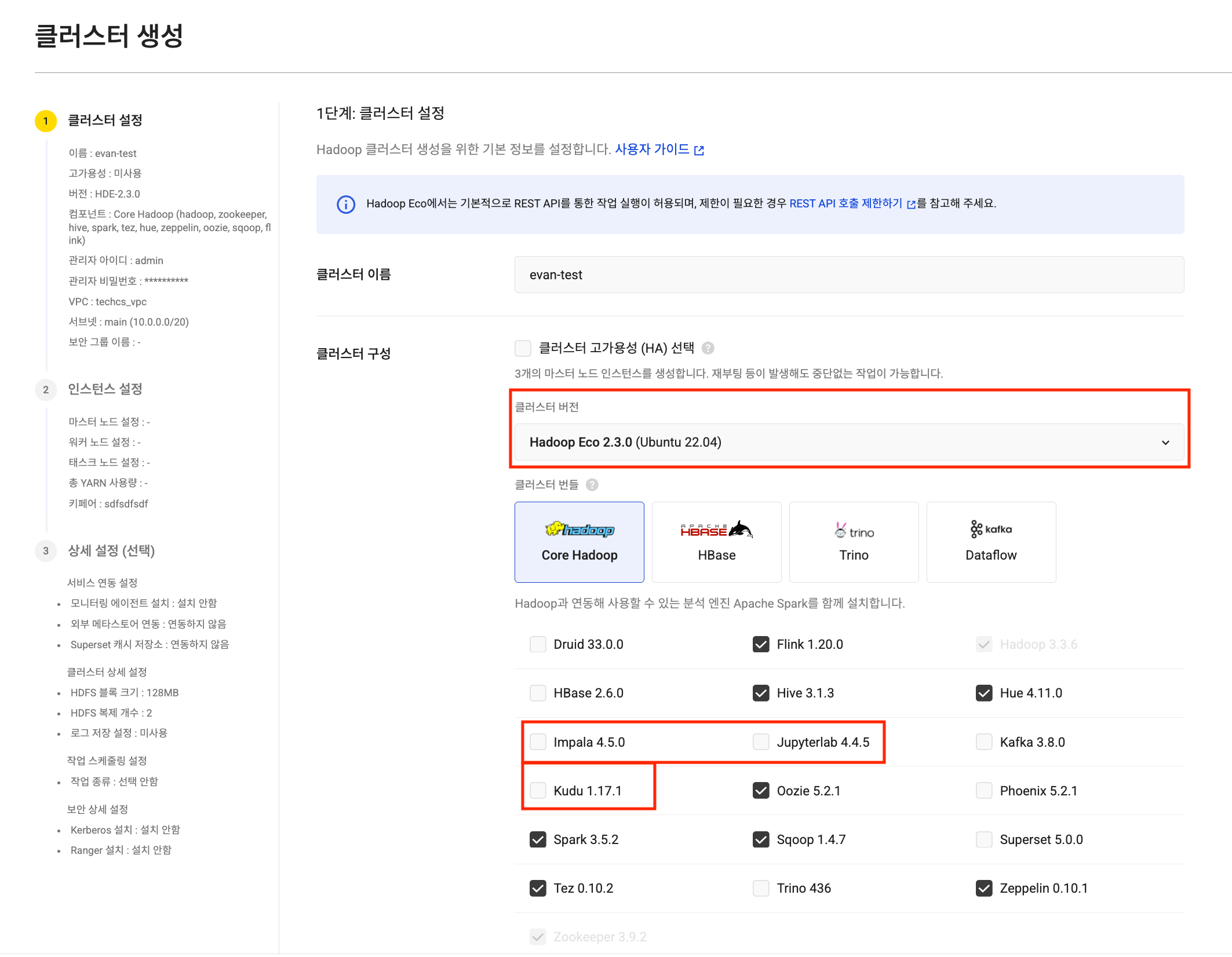
With this update, HDE-2.3.0 is newly provided, and JupyterLab, Impala, and Kudu components have been added to effectively support data analytics and processing workflows.
 Create HDE cluster
Create HDE cluster
- JupyterLab: Provides a web-based programming and shell environment, offering a development environment where data exploration and analysis code can be executed immediately within cluster nodes.
- Impala: A powerful query engine that supports fast interactive queries against data stores such as Kudu based on Hive Metastore.
- Kudu: Serves as a columnar data store that supports low-latency reads and writes.
In addition, Druid, a core component of Dataflow-type clusters, has been upgraded to v33.0.0, and Superset has been upgraded to v5.0.0, further improving performance and stability.
⚙️ Securing cluster structure flexibility: introducing task nodes
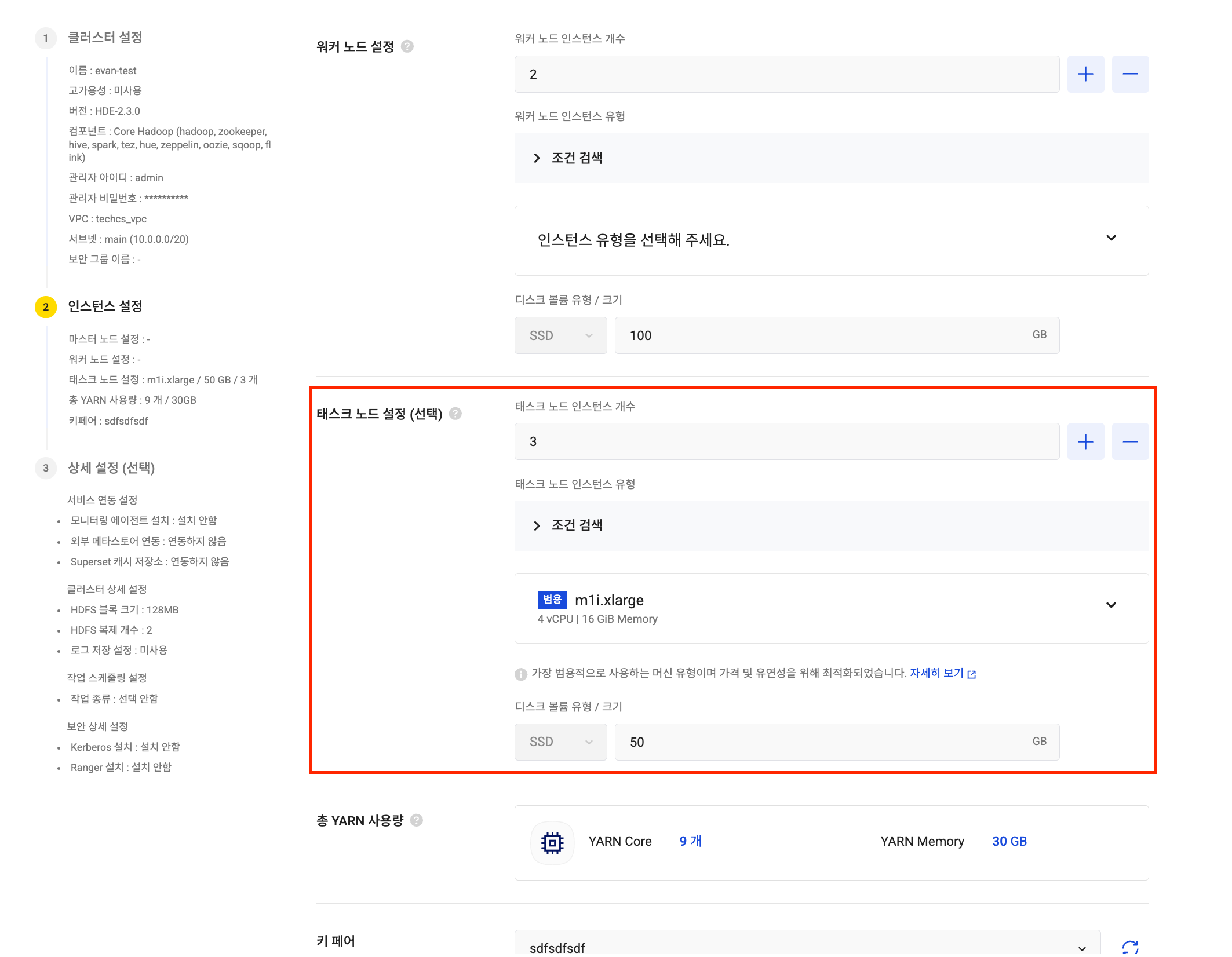
One of the tricky parts of cluster operations is separating batch processing and interactive processing resources to minimize mutual interference. In this update, the newly introduced task node effectively reduces operational burden.
 Task node settings
Task node settings
- Role separation: Task nodes are mainly used as dedicated compute resources for executing large-scale batch computation jobs (YARN Jobs). By separating their role from worker nodes, they ensure the stability of core data processing resources and effectively prevent performance degradation caused by resource contention.
- More accurate capacity planning: With the introduction of task nodes, the method for calculating YARN available resources has been changed to include the number and flavor of task nodes. This makes cluster capacity planning more accurate and predictable.
⚠️ Note when using task nodes: Task nodes can only be added when creating a cluster. Please carefully decide whether to add task nodes during the initial design stage, because they cannot be added after creation. However, reducing the number of nodes to 0 and increasing it again is possible.
🧊 Iceberg catalog integration, now with one click
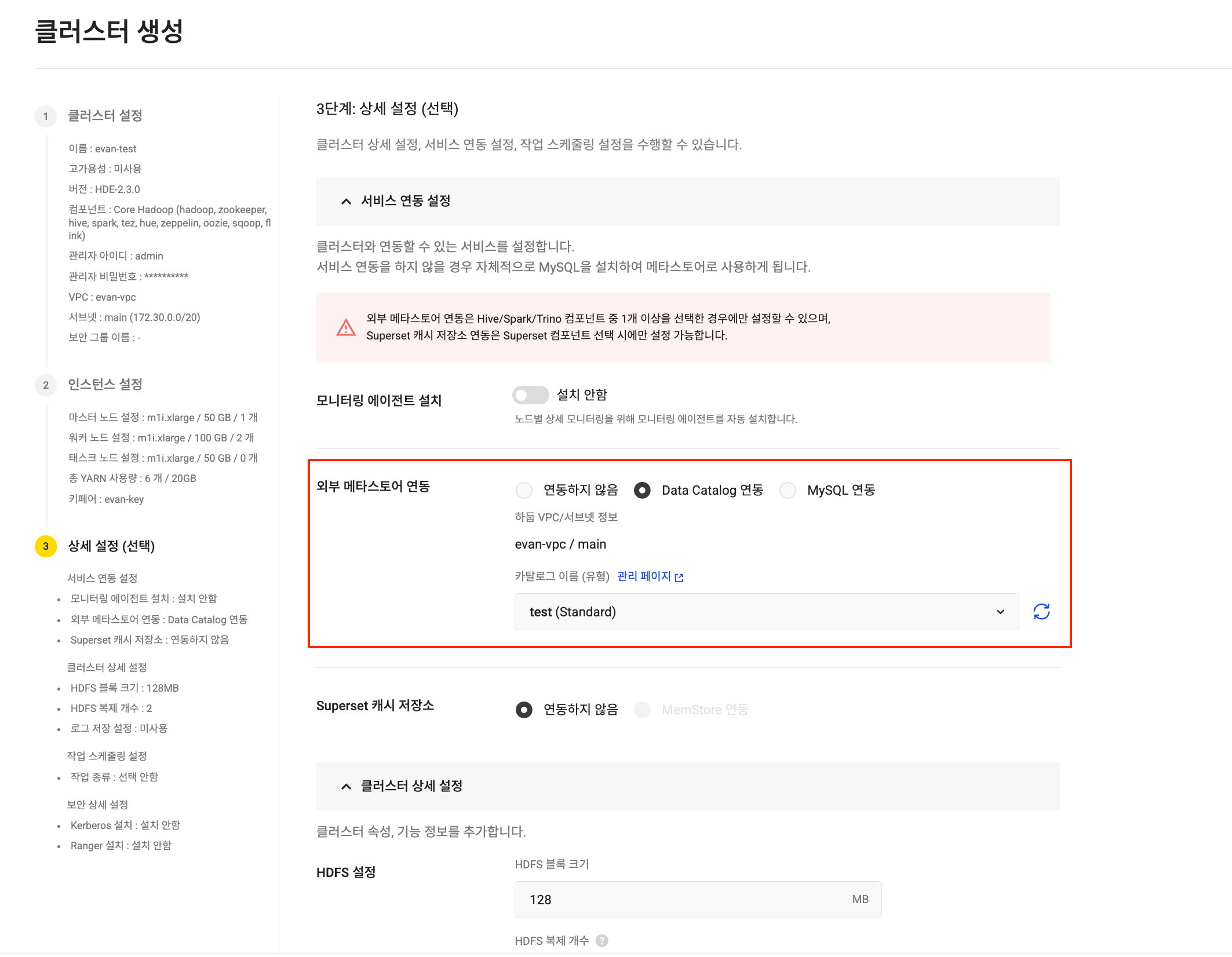
As KakaoCloud Data Catalog officially supports the Apache Iceberg format, Iceberg catalog integration when creating a Hadoop Eco cluster has been dramatically simplified.
 Iceberg catalog integration
Iceberg catalog integration
In the Hadoop Eco service with this improvement, the console now lets you directly select and connect a Data Catalog Iceberg catalog in the external metastore integration setting during cluster creation. This minimizes human error, shortens integration time, and lets you start analytics work immediately.
In addition, an option has been added so that users can choose whether to automatically retain data during the data retention period (90 days) after cluster deletion. This feature can be used to prevent unnecessary metadata retention costs and clarify governance.
This Hadoop Eco update is not just a feature expansion. It further strengthens the operational efficiency of data lake architecture around three axes: stable metadata governance, high-performance interactive analytics environments, and flexible compute resource management.
Operate analytics workflows more efficiently and systematically with KakaoCloud's new Hadoop Eco.
Thank you.