KakaoCloud service updates - VM and Hadoop performance improvements, IAM security settings, and more


This year, KakaoCloud is continuing to move forward without pause to provide users with a more convenient and secure cloud environment. With the warm arrival of spring, we are sharing a roundup of major service updates from March.
If the recently announced user-centered console renewal was a major change to screen structure and experience (UX), this post focuses on service feature enhancements that strengthen the foundation. Along with work to improve system stability, review the details of this update, which further improves resource management efficiency and security.
🖥️ Infrastructure management efficiency and service scalability
-
GPU service integrated into Virtual Machine (VM): For more intuitive resource management, the previously separate GPU service has been integrated into the Virtual Machine service.
- Integrated environment provided: You can now select and manage general instances and GPU instances within the same workflow when creating a VM.
- Automatic notification policy conversion: As part of the service integration, Alert Center notification policies previously configured in the GPU service have been safely and automatically converted into Virtual Machine service policies. You can continue using the existing monitoring environment without separate reconfiguration.
-
Virtual Machine supports "start credits" for t1i instances: To improve workload processing efficiency, the start credit feature has been added to
t1i, a burstable instance type. Instances can now temporarily maintain high CPU utilization during boot, dramatically improving initial startup speed. -
Hadoop Eco expands node volume size up to 16 TB: To support large-scale data analysis, the maximum volume size per node (master, worker, task) in Hadoop Eco has been significantly increased from 5 TB to up to 16 TB. Analyze larger volumes of data without storage constraints.
-
Object Storage product name changed: To make it easier for users to recognize the storage services they are using, Object Storage product names have been changed as follows. Pricing remains the same, and changes will be applied sequentially starting with March billing statements.
- Data capacity: Hot Bucket → Standard Storage Class
- API calls: The Standard- prefix is added before existing request names (for example, Standard-PUT, Standard-GET, and so on)
🔑 Security enhancements
-
IAM security settings enhanced: To protect valuable organizational resources, various security settings have been added to Account settings and IAM service items in the console.
- Password reauthentication when deleting resources: When deleting a user account or project service account, a password reauthentication step has been added to prevent simple mistakes.
- Immediate session and token expiration option: When changing a password, all currently logged-in sessions and issued access tokens can be invalidated immediately. This helps respond quickly to security incidents in emergency situations where account leakage is suspected.
- Expanded Cloud Trail audit logs: 17 new event types have been added so that security policy and account management history can be tracked in more detail.
🛠️ Improved developer convenience
- New OpenAPI support for MySQL: OpenAPI support for developers has been expanded further. With this update, MySQL OpenAPI has been newly added, allowing KakaoCloud MySQL to be controlled directly by API and used for management automation. For detailed OpenAPI updates, see OpenAPI Changelogs.
That is all for this update. In addition to the feature improvements introduced here, detailed changes for each service and previous update history can be found in the service-specific release notes in the technical documentation.
KakaoCloud will continue doing its best to provide stable infrastructure and user-centered features.
If you have any questions about using the service, please contact KakaoCloud Support anytime.


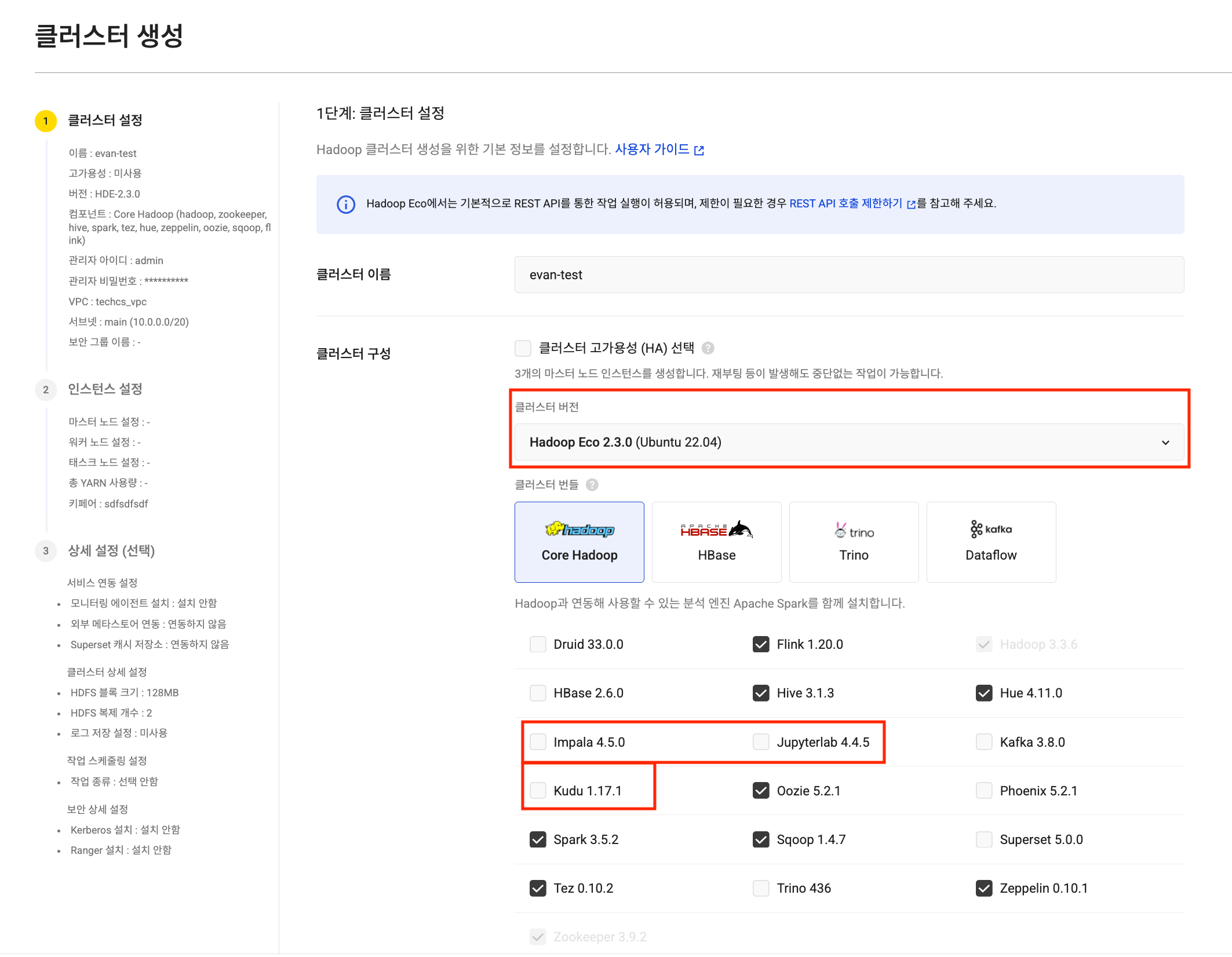 Create HDE cluster
Create HDE cluster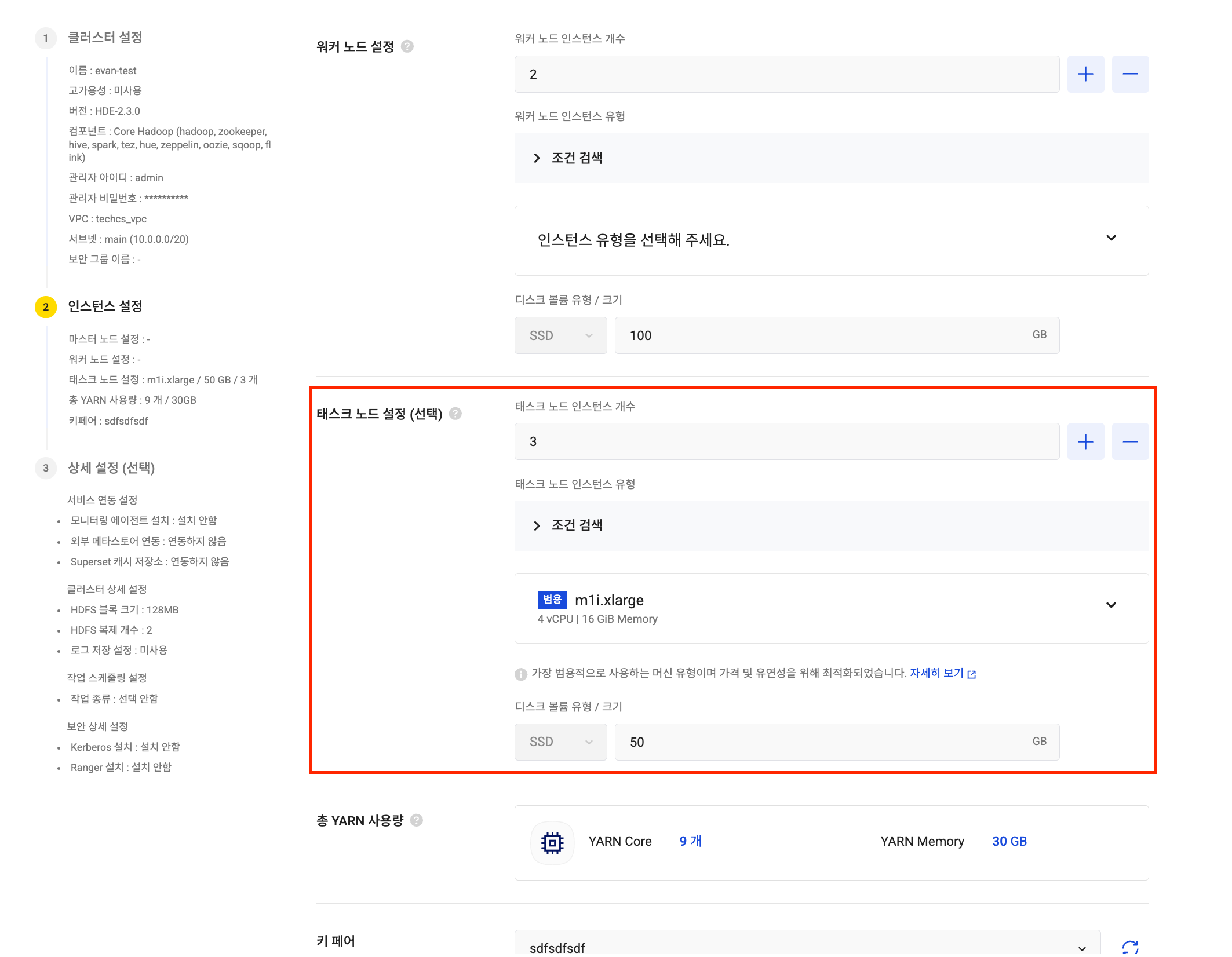 Task node settings
Task node settings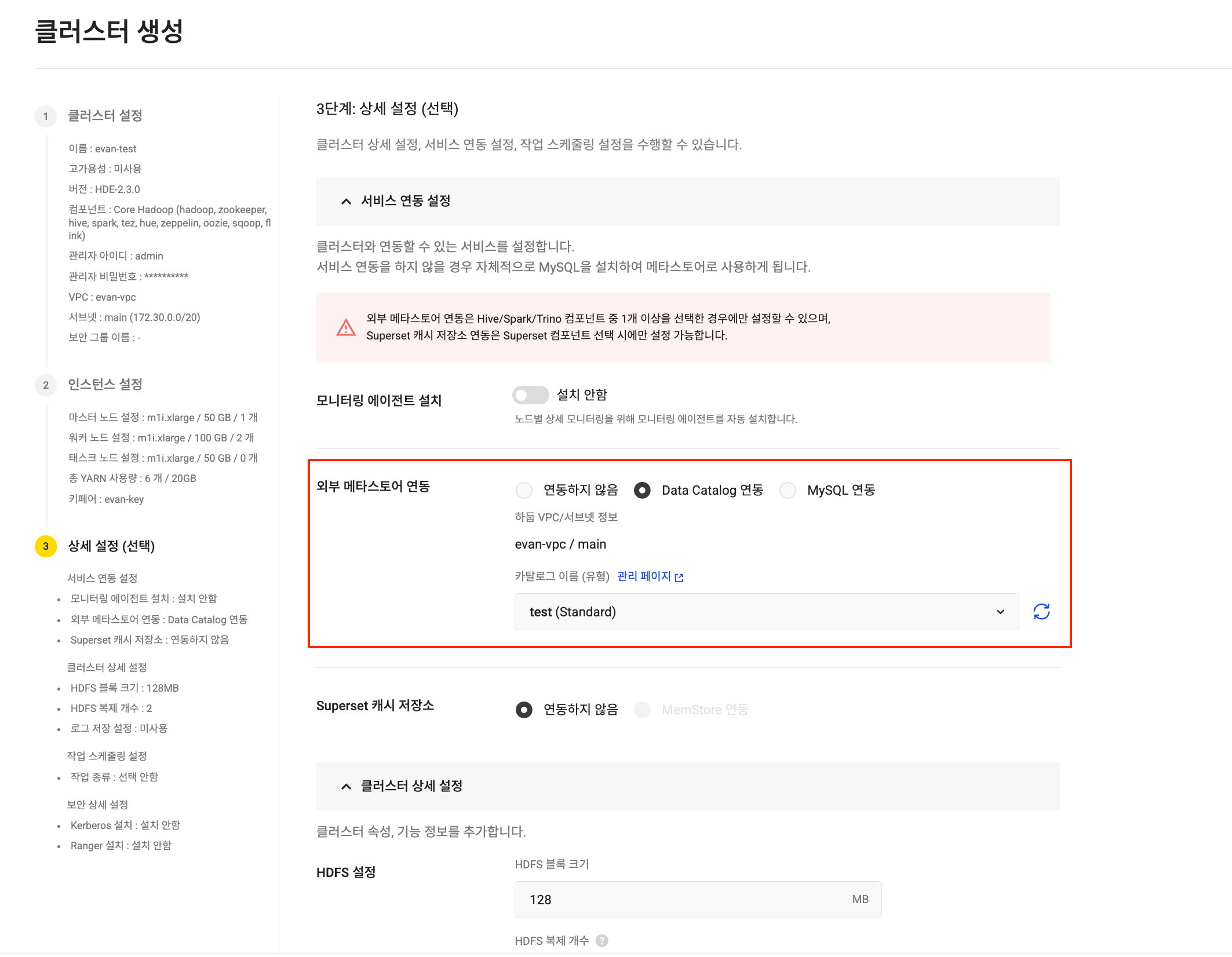 Iceberg catalog integration
Iceberg catalog integration