Key Concepts
Data source
Data Query allows you to import and analyze data sources from KakaoCloud services such as Data Catalog, MySQL, and PostgreSQL.
- All catalogs created by the user in Data Catalog are automatically loaded without requiring a separate connection.
- For MySQL and PostgreSQL, you can retrieve data from your desired database by creating a data source.
Query result storage location
All executed query result data is automatically saved in the Object Storage bucket set by the user.
- Users can analyze and utilize query result data stored in the Object Storage bucket.
- Query result storage paths can be set individually per user within a project to utilize query result data.
- Query execution result data is stored as
.metadataand.csvfiles.
Database
You can load and select all databases from Data Catalog, MySQL, and PostgreSQL data sources.
- Automatically loads all database information linked to the selected catalog.
- Loads all databases associated with the MySQL instance group.
- Loads all databases associated with the PostgreSQL instance group.
Table
Loads all tables from the selected database in Data Catalog, MySQL, or PostgreSQL.
- You can check the list of all tables in the selected database.
- You can check detailed column information for each table.
- Table data preview helps with query writing.
- You can generate the table's DDL to understand the structure in advance and assist with query writing.
Query editor
Users can load data sources, enter queries, and execute them on the query editor screen.
- The query editor allows running queries and analyzing results for all connected data sources.
- You can preview query results, and all query result data can be checked in the configured Object Storage bucket.
Execution flow chart
The execution flow chart visually shows the process of analyzing data with the executed query. Users can easily use it for execution plans and result analysis.
- Real-time status monitoring: You can check the progress and performance metrics of each stage of query execution in real time.
- Parallel processing visualization: Intuitively shows data distribution and parallel task structure to provide efficient data processing.
- Detailed execution information: Provides detailed information such as data throughput and query execution time at each stage at a glance.
Query execution lifecycle
Query execution has the lifecycle shown below, allowing you to check the status of the query process.
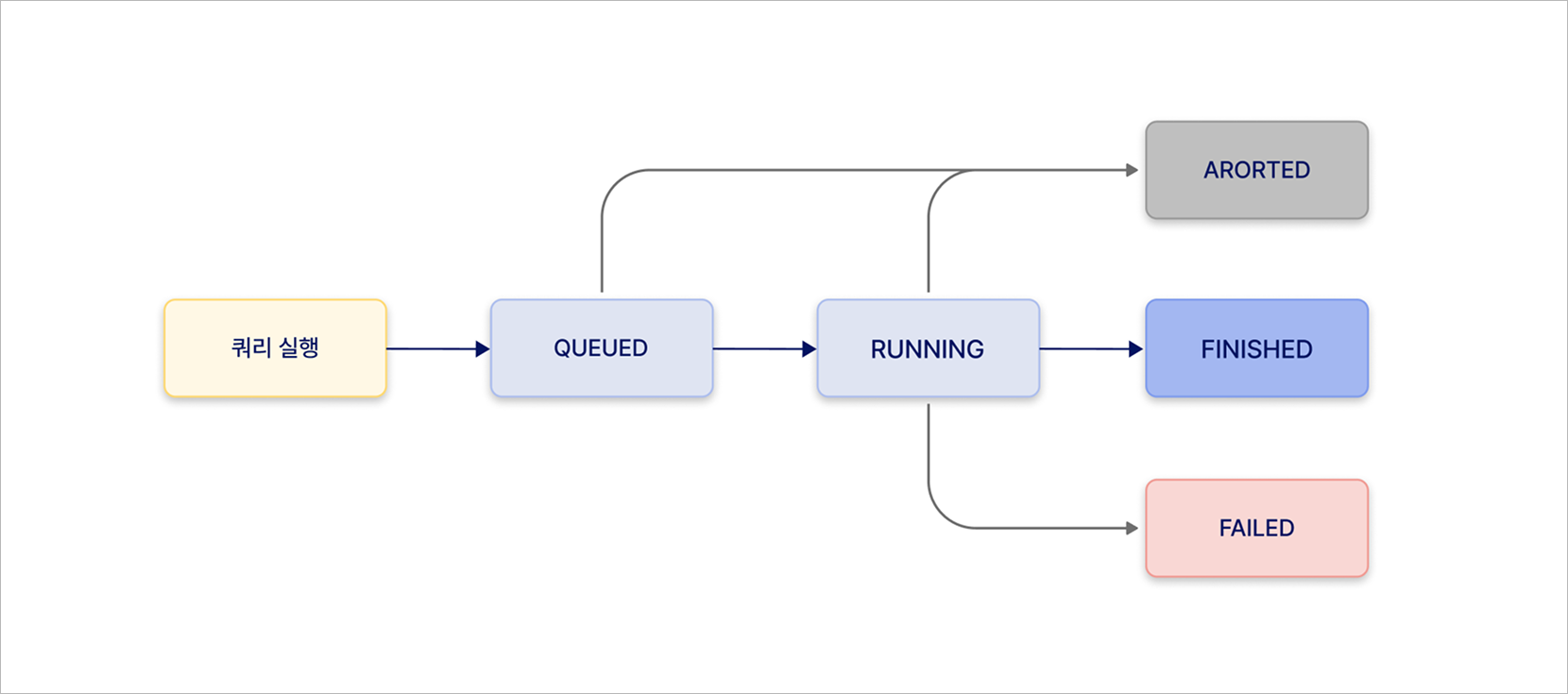 Query lifecycle
Query lifecycle
Query execution status
| Status | Description |
|---|---|
| Waiting | The task is in the queue, waiting for query execution |
| Running | The query is currently running |
| Success | The query completed successfully - When query result reuse is used, shown as Success - Query result reused |
| Canceled | The user stopped the query |
| Failed | The query execution did not complete due to an error |
Data types
Supported data types
When writing queries, refer to the supported data types for each Data Catalog, MySQL, or PostgreSQL source type.
Data types used in queries are automatically mapped according to the data source type.
Unsupported types are not listed in the table.
Data Catalog types
Standard (Apache Hive Metastore) types
| Hive | Data Query |
|---|---|
| VARCHAR | BOOLEAN, TINYINT, SMALLINT, INTEGER, BIGINT, REAL, DOUBLE, TIMESTAMP, DATE, CHAR, VARCHAR |
| VARBINARY | VARCHAR |
| TINYINT | VARCHAR, SMALLINT, INTEGER, BIGINT, DOUBLE, DECIMAL |
| TIMESTAMP | VARCHAR, DATE |
| SMALLINT | VARCHAR, INTEGER, BIGINT, DOUBLE, DECIMAL |
| REAL | DOUBLE, DECIMAL |
| INTEGER | VARCHAR, BIGINT, DOUBLE, DECIMAL |
| DOUBLE | FLOAT, DECIMAL |
| DECIMAL | DOUBLE, REAL, VARCHAR, TINYINT, SMALLINT, INTEGER, BIGINT, DECIMAL |
| DATE | VARCHAR |
| CHAR | VARCHAR, CHAR |
| BOOLEAN | VARCHAR |
| BIGINT | VARCHAR, DOUBLE, DECIMAL |
Iceberg (Apache Iceberg) types
| Iceberg | Data Query |
|---|---|
| BOOLEAN | BOOLEAN, VARCHAR |
| INT | INTEGER, BIGINT, DOUBLE, DECIMAL, VARCHAR |
| LONG | BIGINT, DOUBLE, DECIMAL, VARCHAR |
| BIGINT | BIGINT, DOUBLE, DECIMAL, VARCHAR |
| FLOAT | DOUBLE, DECIMAL, VARCHAR |
| DOUBLE | DOUBLE, DECIMAL, VARCHAR |
| DECIMAL | DECIMAL, DOUBLE, REAL, BIGINT, INTEGER, SMALLINT, TINYINT, VARCHAR |
| DATE | DATE, TIMESTAMP, VARCHAR |
| TIME | TIME, VARCHAR |
| TIMESTAMP | TIMESTAMP, DATE, VARCHAR |
| STRING | VARCHAR |
| BINARY | VARCHAR |
| UUID | VARCHAR |
| FIXED | VARCHAR |
MySQL types
| MySQL | Data Query |
|---|---|
| BIT | BOOLEAN |
| BOOLEAN | TINYINT |
| TINYINT | TINYINT |
| TINYINT UNSIGNED | SMALLINT |
| SMALLINT | VARCHAR, SMALLINT |
| SMALLINT UNSIGNED | INTEGER |
| INTEGER | INTEGER |
| INTEGER UNSIGNED | BIGINT |
| BIGINT | BIGINT |
| BIGINT UNSIGNED | DECIMAL(20, 0) |
| DOUBLE PRECISION | DECIMAL(20, 0) |
| FLOAT | REAL |
| REAL | REAL |
| DECIMAL(p, s) | DECIMAL(p, s) |
| CHAR(n) | CHAR(n) |
| VARCHAR(n) | VARCHAR(n) |
| TINYTEXT | VARCHAR(255) |
| TEXT | VARCHAR(65535) |
| MEDIUMTEXT | VARCHAR(16777215) |
| LONGTEXT | VARCHAR |
| ENUM(n) | VARCHAR(n) |
| BINARY, VARBINARY, TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB | VARBINARY |
| JSON | JSON |
| DATE | DATE |
| TIME(n) | TIME(n) |
| DATETIME(n) | TIMESTAMP(n) |
| TIMESTAMP(n) | TIMESTAMP(n) WITH TIME ZONE |
PostgreSQL types
| PostgreSQL | Data Query |
|---|---|
| BIT | BOOLEAN |
| BOOLEAN | BOOLEAN |
| SMALLINT | SMALLINT |
| INTEGER | INTEGER |
| BIGINT | BIGINT |
| REAL | REAL |
| DOUBLE | DOUBLE |
| NUMERIC(p, s) | DECIMAL(p, s) |
| CHAR(n) | CHAR(n) |
| VARCHAR(n) | VARCHAR(n) |
| ENUM(n) | VARCHAR(n) |
| BYTEA | VARBINARY |
| DATE | DATE |
| TIME(n) | TIME(n) |
| TIMESTAMP(n) | TIMESTAMP(n) |
| TIMESTAMP(n) | TIMESTAMP(n) WITH TIME ZONE |
| MONEY | VARCHAR |
| UUID | UUID |
| JSON | JSON |
| JSONB | JSON |
| HSTORE | MAP(VARCHAR, VARCHAR) |
| ARRAY | Disabled, ARRAY, or JSON |
Event collection
You can check automatically collected events on Data Query user activity using the Cloud Trail service.
- Check Data Query events (Data Query events are collected per project.)
- For more details on Cloud Trail, refer to KakaoCloud’s Cloud Trail documentation.