Integrate with Object Storage
Integrate Object Storage with Swift
You can access Object Storage data in Hadoop Eco service through Swift.
When creating a Hadoop Eco cluster, you must set the keys in core-site.xml to access the data in Object Storage.
- Encrypted buckets are not supported. If using encrypted buckets, queries may fail.
- To access Object Storage, an access key is required. You can issue an access key from KakaoCloud console > Profile at the top-right > Credentials > IAM Access Key. For more information, refer to Access Key Issuance.
Add During Cluster Creation (Cluster Detailed Settings)
During cluster creation, add the following in the cluster’s detailed settings.
{
"configurations": [
{
"classification": "core-site",
"properties": {
"fs.swifta.service.kc.credential.id": "credential_id",
"fs.swifta.service.kc.credential.secret": "credential_secret"
}
}
]
}
Modify After Cluster Creation (Modify core-site.xml)
After creating the cluster, modify the /etc/hadoop/conf/core-site.xml file and add the access key information as shown below.
<configuration>
<property>
<name>fs.swifta.service.kc.credential.id</name>
<value>credential_id</value>
</property>
<property>
<name>fs.swifta.service.kc.credential.secret</name>
<value>credential_secret</value>
</property>
</configuration>
Sample usage
The schema for Object Storage is as follows:
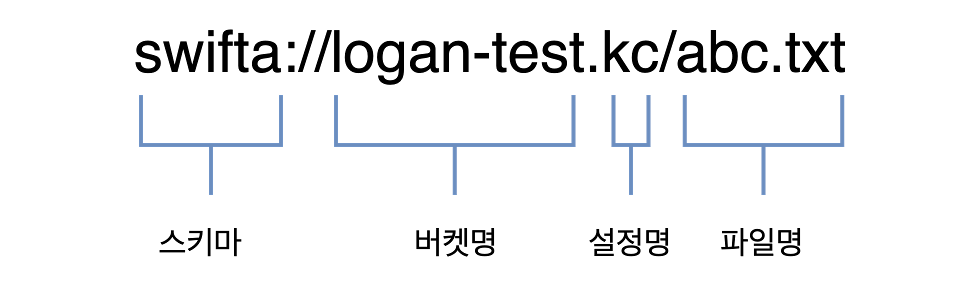 Object Storage Schema
Object Storage Schema
Hadoop
You can check the Object Storage data using fs commands like ls, mkdir, put, get in Hadoop.
$ hadoop fs -ls swifta://logan-test.kc/
Found 2 items
-rw-rw-rw- 1 ubuntu ubuntu 6 2021-07-14 02:30 swifta://logan-test.kc/abc.txt
drwxrwxrwx - ubuntu ubuntu 0 2021-07-14 04:12 swifta://logan-test.kc/user
Hive
When creating a table, specify LOCATION as Object Storage to access the data.
-- Create a table with LOCATION set to Object Storage
CREATE EXTERNAL TABLE tb_objectstorage (
col1 STRING
)
LOCATION 'swifta://logan-test.kc/tb_objectstorage'
;
-- Insert data
insert into table tb_objectstorage values ('a'), ('b'), ('c');
-- Query
select col1, count(*) from tb_objectstorage group by col1;
# Check with Hadoop commands
$ hadoop fs -ls swifta://logan-test.kc/tb_objectstorage
Found 1 items
-rw-rw-rw- 1 ubuntu ubuntu 16 2022-03-31 06:16 swifta://logan-test.kc/tb_objectstorage/000000_0.snappy
Spark
You can specify Object Storage as the location to read data in Spark.
$ ./bin/spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/04/01 05:54:58 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://hadoopmst-hadoop-single-1:4040
Spark context available as 'sc' (master = yarn, app id = application_1648703257814_0004).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> val peopleDF = spark.read.format("json").load("swifta://logan-test.kc/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [name: string]
scala> peopleDF.show()
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
Trino
You can view the Object Storage integrated table created using Hive in Trino.
# View Hive table
hive (default)> desc formatted t2;
OK
col_name data_type comment
# col_name data_type comment
col1 string
# Detailed Table Information
Database: default
Owner: ubuntu
CreateTime: Thu Jul 14 00:14:27 UTC 2022
LastAccessTime: UNKNOWN
Retention: 0
Location: swifta://logan-test.kc/t2
Table Type: MANAGED_TABLE
Table Parameters:
STATS_GENERATED_VIA_STATS_TASK workaround for potential lack of HIVE-12730
numFiles 9
totalSize 165
transient_lastDdlTime 1657757711
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 8.039 seconds, Fetched: 28 row(s)
# Query and Insert Data in Trino
$ trino --server http://hadoopmst-trino-ha-3:8780 --catalog hive
trino> select col1, count(*) from default.t2 group by col1;
col1 | _col1
------+-------
b | 6
dd | 1
aa | 1
c | 6
a | 6
(5 rows)
Query 20220714_001621_00000_3xb9i, FINISHED, 3 nodes
Splits: 64 total, 64 done (100.00%)
6.18 [20 rows, 142B] [3 rows/s, 23B/s]
trino>
trino> insert into default.t2 values ('kk');
INSERT: 1 row
Query 20220714_001659_00001_3xb9i, FINISHED, 4 nodes
Splits: 37 total, 37 done (100.00%)
7.47 [0 rows, 0B] [0 rows/s, 0B/s]
Integrate Object Storage with S3
You can use S3 API to access Object Storage data in Hadoop Eco service.
Prepare for API integration
To use the S3 API to access Object Storage data, you need to first issue EC2 credentials.
Refer to the Object Storage-S3 documentation to issue the credentials.
HDE Creation Settings
HDE supports accessing S3 data through settings when creating Hadoop, Hive, or Trino.
During cluster creation, you can configure the basic settings for S3 connection in the cluster configuration settings as shown below.
| classification | properties |
|---|---|
| core-site | Settings to access S3 API from Hadoop and Hive. Enter the access key in fs.s3a.access.key and the secret key in fs.s3a.secret.key. |
| trino-catalog-hive | Trino's Hive connector settings. Enter the access key in hive.s3.aws-access-key and the secret key in hive.s3.aws-secret-key. |
{
"configurations":
[
{
"classification": "core-site",
"properties":
{
"fs.s3a.access.key": "<aws-access-key>",
"fs.s3a.secret.key": "<aws-secret-key>",
"fs.s3a.buckets.create.region": "kr-central-2",
"fs.s3a.endpoint.region": "kr-central-2",
"fs.s3a.endpoint": "objectstorage.kr-central-2.kakaocloud.com",
"s3service.s3-endpoint": "objectstorage.kr-central-2.kakaocloud.com",
"fs.s3a.signing-algorithm": "AWSS3V4SignerType"
}
},
{
"classification": "trino-catalog-hive",
"properties":
{
"hive.s3.aws-access-key": "<aws-access-key>",
"hive.s3.aws-secret-key": "<aws-secret-key>",
"hive.s3.endpoint": "https://objectstorage.kr-central-2.kakaocloud.com",
"hive.s3.path-style-access": "true",
"hive.s3.signer-type": "AWSS3V4SignerType"
}
}
]
}
Modify core-site.xml
After cluster creation, add the following content to the core-site.xml file located in the /etc/hadoop/conf path.
<configuration>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
<property>
<name>fs.s3a.aws.credentials.provider</name>
<value>org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>ACCESS_KEY</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>SECRET_KEY</value>
</property>
<property>
<name>fs.s3a.buckets.create.region</name>
<value>kr-central-2</value>
</property>
<property>
<name>fs.s3a.endpoint.region</name>
<value>kr-central-2</value>
</property>
<property>
<name>fs.s3a.paging.maximum</name>
<value>1000</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>objectstorage.kr-central-2.kakaocloud.com</value>
</property>
<property>
<name>s3service.s3-endpoint</name>
<value>objectstorage.kr-central-2.kakaocloud.com</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.ssl.channel.mode</name>
<value>default_jsse_with_gcm</value>
</property>
<property>
<name>fs.s3a.signing-algorithm</name>
<value>AWSS3V4SignerType</value>
</property>
...
</configuration>
Modify hive-site.xml
After cluster creation, add the following content to the hive-site.xml file located in the /etc/hive/conf path.
<configuration>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
<property>
<name>fs.s3a.aws.credentials.provider</name>
<value>org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>ACCESS_KEY</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>SECRET_KEY</value>
</property>
<property>
<name>fs.s3a.buckets.create.region</name>
<value>kr-central-2</value>
</property>
<property>
<name>fs.s3a.endpoint.region</name>
<value>kr-central-2</value>
</property>
<property>
<name>fs.s3a.paging.maximum</name>
<value>1000</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>objectstorage.kr-central-2.kakaocloud.com</value>
</property>
<property>
<name>s3service.s3-endpoint</name>
<value>objectstorage.kr-central-2.kakaocloud.com</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.ssl.channel.mode</name>
<value>default_jsse_with_gcm</value>
</property>
<property>
<name>fs.s3a.signing-algorithm</name>
<value>AWSS3V4SignerType</value>
</property>
...
</configuration>
HDE Usage Example
After creating the cluster, you can use it in the following format.
Hadoop
Hadoop can use the s3a scheme to query Object Storage data. You can process Object Storage data using Hadoop fs commands.
ubuntu@host-172-16-2-139:~$ hadoop fs -ls s3a://logan-kr2-test/
Found 17 items
-rw-rw-rw- 1 ubuntu ubuntu 0 2024-02-27 06:42 s3a://logan-kr2-test/a.txt
-rw-rw-rw- 1 ubuntu ubuntu 6 2024-02-27 10:37 s3a://logan-kr2-test/b.txt
-rw-rw-rw- 1 ubuntu ubuntu 6 2024-02-28 01:49 s3a://logan-kr2-test/c.txt
Hive
Hive can be used to create tables and query data. When creating a table, specify the LOCATION as Object Storage to query the data.
Hive Session ID = 7b0d6f83-bf09-418d-b4db-b6d0b4c92409
hive> CREATE EXTERNAL TABLE IF NOT EXISTS orders_s3 (
> O_ORDERKEY BIGINT ,
> O_CUSTKEY BIGINT ,
> O_ORDERSTATUS STRING ,
> O_TOTALPRICE DECIMAL(15,2) ,
> O_ORDERDATE DATE ,
> O_ORDERPRIORITY STRING ,
> O_CLERK STRING ,
> O_SHIPPRIORITY BIGINT ,
> O_COMMENT STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> STORED AS TEXTFILE
> LOCATION 's3a://logan-kr2-test/tables/orders';
OK
Time taken: 2.232 seconds
hive> select * from orders_s3 limit 10;
OK
1 369001 O 186600.18 1996-01-02 5-LOW Clerk#000009506 0 nstructions sleep furiously among
2 780017 O 66219.63 1996-12-01 1-URGENT Clerk#000008792 0 foxes. pending accounts at the pending, silent asymptot
3 1233140 F 270741.97 1993-10-14 5-LOW Clerk#000009543 0 sly final accounts boost. carefully regular ideas cajole carefully. depos
4 1367761 O 41714.38 1995-10-11 5-LOW Clerk#000001234 0 sits. slyly regular warthogs cajole. regular, regular theodolites acro
5 444848 F 122444.33 1994-07-30 5-LOW Clerk#000009248 0 quickly. bold deposits sleep slyly. packages use slyly
6 556222 F 50883.96 1992-02-21 4-NOT SPECIFIED Clerk#000000580 0 ggle. special, final requests are against the furiously specia
7 391343 O 287534.80 1996-01-10 2-HIGH Clerk#000004697 0 ly special requests
32 1300570 O 129634.85 1995-07-16 2-HIGH Clerk#000006157 0 ise blithely bold, regular requests. quickly unusual dep
33 669580 F 126998.88 1993-10-27 3-MEDIUM Clerk#000004086 0 uriously. furiously final request
34 610001 O 55314.82 1998-07-21 3-MEDIUM Clerk#000002228 0 ly final packages. fluffily final deposits wake blithely ideas. spe
Time taken: 1.259 seconds, Fetched: 10 row(
Spark
You can query data using the s3a scheme in Spark as well.
ubuntu@host-172-16-2-240:~$ spark-shell
Spark context Web UI available at http://host-172-16-2-240:4040
Spark context available as 'sc' (master = yarn, app id = application_1710847013809_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.2
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val df = spark.read.option("delimiter", "|").csv("s3a://logan-kr2-test/tables/orders/orders.tbl")
24/03/19 11:19:57 INFO FileSourceScanExec: Planning scan with bin packing, max size: 134217728 bytes, open cost is considered as scanning 4194304 bytes.
df: org.apache.spark.sql.DataFrame = [_c0: string, _c1: string ... 7 more fields]
scala> df.groupBy("_c2").count().show()
24/03/19 11:20:26 INFO CodeGenerator: Code generated in 14.482648 ms
+---+-------+
|_c2| count|
+---+-------+
| F|7309184|
| O|7307464|
| P| 383352|
+---+-------+
Trino
You can query tables created using Hive and access them in Trino.
ubuntu@host-172-16-2-139:~$ trino --server http://$(hostname -f):8780 --catalog hive
trino> use default;
USE
trino:default> select * from orders_s3 limit 10;
o_orderkey | o_custkey | o_orderstatus | o_totalprice | o_orderdate | o_orderpriority | o_clerk | o_shippriority | o_comment
------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+--------------------------------------------------------------------------
36027108 | 332566 | O | 170328.01 | 1997-09-27 | 4-NOT SPECIFIED | Clerk#000004309 | 0 | eposits. final accounts engage furiously
36027109 | 416335 | F | 321250.69 | 1992-12-30 | 2-HIGH | Clerk#000004984 | 0 | . fluffily silent pinto beans about the regular packages can sle
36027110 | 1338967 | O | 190473.00 | 1995-08-28 | 5-LOW | Clerk#000002158 | 0 | ronic, even theodolites! instructions sleep ruthlessly after the fluff
36027111 | 1011007 | O | 202525.53 | 1996-07-15 | 4-NOT SPECIFIED | Clerk#000004496 | 0 | ites are fluffily final packages. carefully special requests against the
36027136 | 1467476 | O | 257089.22 | 1995-11-13 | 3-MEDIUM | Clerk#000008929 | 0 | kly regular deposits wake furiously after the exp
36027137 | 866210 | O | 80077.87 | 1997-04-27 | 5-LOW | Clerk#000003500 | 0 | gular, special packages lose quickly stealthily s
36027138 | 889922 | F | 129606.13 | 1992-09-30 | 3-MEDIUM | Clerk#000008527 | 0 | fully. bold, even accounts across
36027139 | 409189 | F | 371514.75 | 1994-09-23 | 5-LOW | Clerk#000001269 | 0 | ccounts. ironic, bold deposits detect cl
36027140 | 1223315 | P | 105565.01 | 1995-04-04 | 4-NOT SPECIFIED | Clerk#000004118 | 0 | ns. regular packages are carefully slyly final acc
36027141 | 1244056 | O | 64842.84 | 1998-07-28 | 2-HIGH | Clerk#000009156 | 0 | d accounts; foxes w
(10 rows)