Component list
The following explains how to use the components installed in a Hadoop Eco cluster.
Hive
Run the Hive CLI and enter queries.
hive
hive (default)> CREATE TABLE tbl (
> col1 STRING
> ) STORED AS ORC
> TBLPROPERTIES ("orc.compress"="SNAPPY");
OK
Time taken: 1.886 seconds
Hive - integrate with Zeppelin
-
Attach a public IP to the master node where Zeppelin is installed, then access the Zeppelin UI.
For how to access Zeppelin, refer to Zeppelin. -
How to run Hive in Zeppelin
- Select
Notebook > Create new notefrom the top menu and select the Hive interpreter in the popup. - You can enter the following in the Zeppelin notebook and run it.
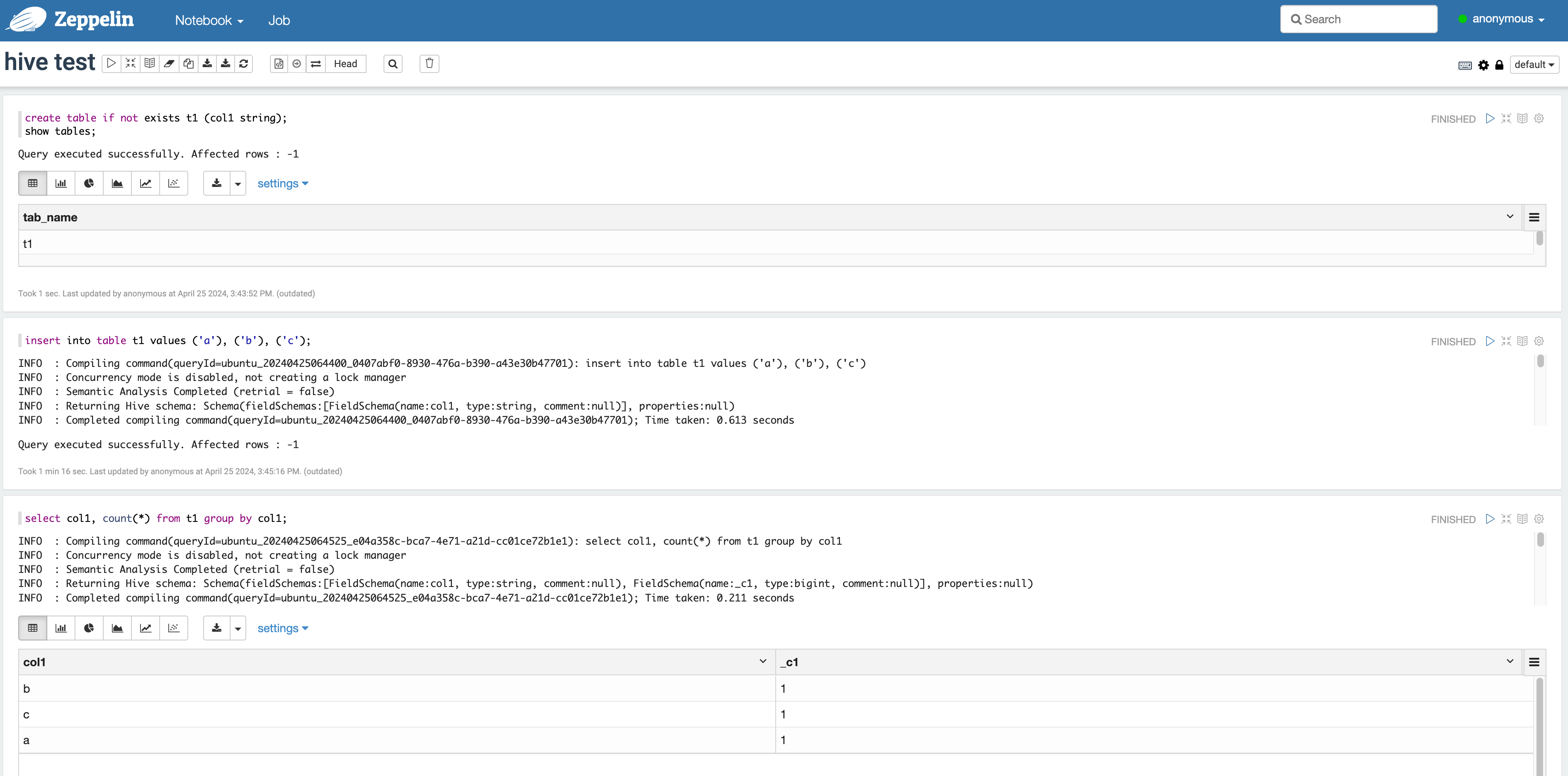 Check Trino-Zeppelin query result
Check Trino-Zeppelin query result - Select
Beeline
-
Run the Beeline CLI.
-
Choose between Direct access to HiveServer2 or Access via Zookeeper to connect to HiveServer2.
- Direct access to HiveServer2
- Access via Zookeeper
!connect jdbc:hive2://[server name]:10000/default;!connect jdbc:hive2://[master 1]:2181,[master 2]:2181,[master 3]:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kepbp_hiveserver2 -
Enter the query.
-
Before executing the query, be sure to enter the correct username. The default user in Hadoop Eco is Ubuntu.
-
If the query is executed as a user who cannot access HDFS, an error may occur.
Run query using Beeline CLI######################################
# Direct access to HiveServer2
######################################
beeline> !connect jdbc:hive2://10.182.50.137:10000/default;
Connecting to jdbc:hive2://10.182.50.137:10000/default;
Enter username for jdbc:hive2://10.182.50.137:10000/default:
Enter password for jdbc:hive2://10.182.50.137:10000/default:
Connected to: Apache Hive (version 2.3.2)
Driver: Hive JDBC (version 2.3.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://10.182.50.137:10000/default> show databases;
+----------------+
| database_name |
+----------------+
| db_1 |
| default |
+----------------+
2 rows selected (0.198 seconds)
#####################################
# Access via Zookeeper
#####################################
beeline> !connect jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kepbp_hiveserver2
Connecting to jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kepbp_hiveserver2
Enter username for jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/:
Enter password for jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/:
22/09/06 05:40:52 [main]: INFO jdbc.HiveConnection: Connected to hadoopmst-hadoop-ha-1:10000
Connected to: Apache Hive (version 2.3.9)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoopmst-hadoop-ha-1:2181,ha> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (2.164 seconds)
0: jdbc:hive2://hadoopmst-hadoop-ha-1:2181,ha>
#####################################
# User input (Enter username: )
#####################################
beeline> !connect jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default;
Connecting to jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default;
Enter username for jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default: ubuntu
Enter password for jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default:
Connected to: Apache Hive (version 2.3.9)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://bigdata-hadoop-master-1.kep.k> create table t2 (`value` string,`product_num` int) partitioned by (manufacture_date string) STORED AS ORC;
No rows affected (0.527 seconds)
0: jdbc:hive2://bigdata-hadoop-master-1.kep.k> insert into t2 partition(manufacture_date='2019-01-01') values('asdf', '123');
No rows affected (26.56 seconds)
0: jdbc:hive2://bigdata-hadoop-master-1.kep.k>
-
Access Hue
Hue is a user interface provided for Hadoop Eco clusters.
Select the quick link on the cluster details page to access it. Log in using the administrator credentials set at cluster creation.
Hue supports both Hive editor and browsers.
- Browser types: file browser, table browser, job browser
Hue access ports by cluster type
| Cluster availability | Access port |
|---|---|
| Standard (Single) | Port 8888 of master node 1 |
| HA | Port 8888 of master node 3 |

Hue user login
Access Oozie
Oozie is a workflow management tool provided for clusters of type Core Hadoop in Hadoop Eco.
Oozie access ports by cluster type
| Cluster availability | Access port |
|---|---|
| Standard (Single) | Port 11000 of master node 1 |
| HA | Port 11000 of master node 3 |
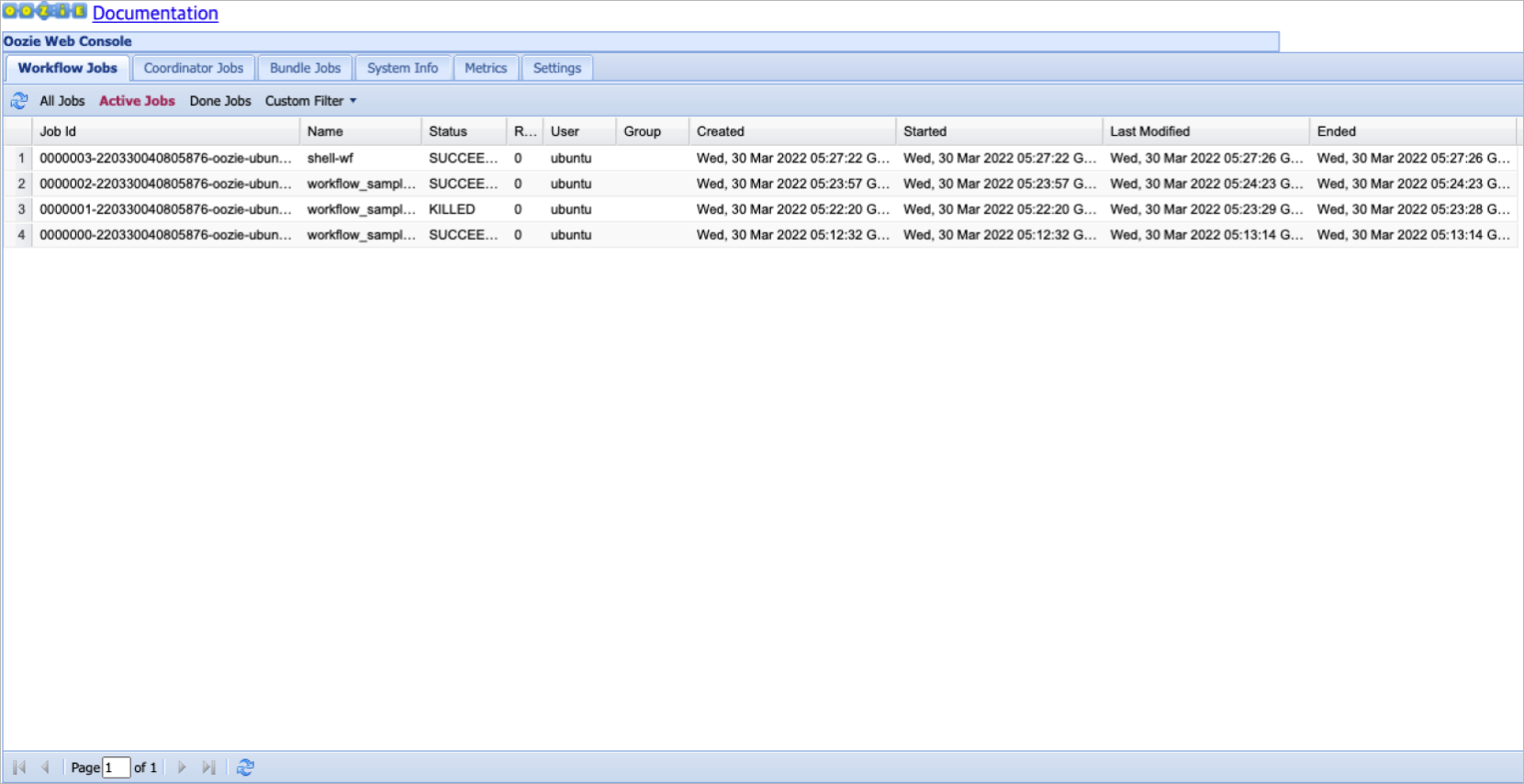
Oozie workflow list
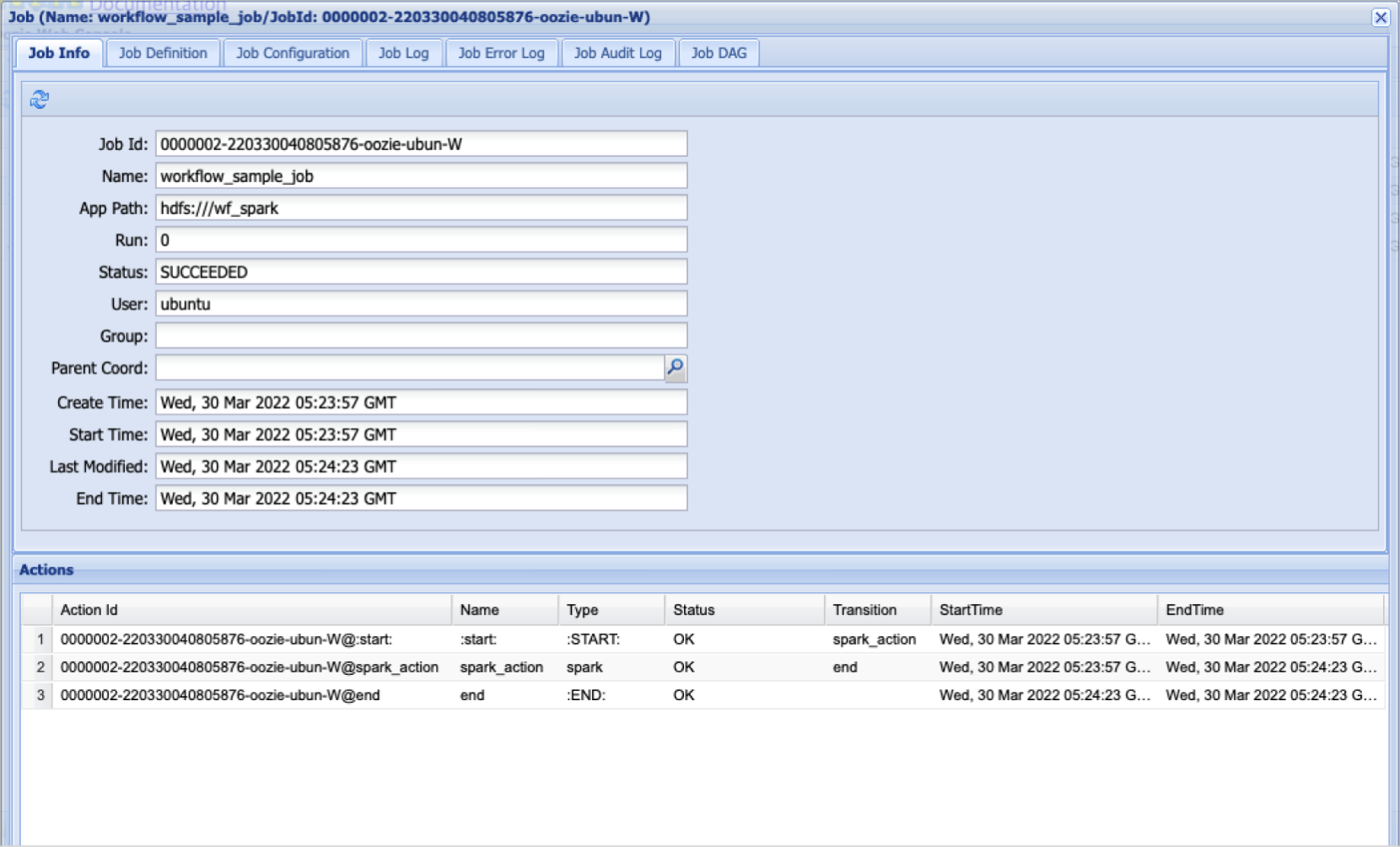
Oozie workflow job info
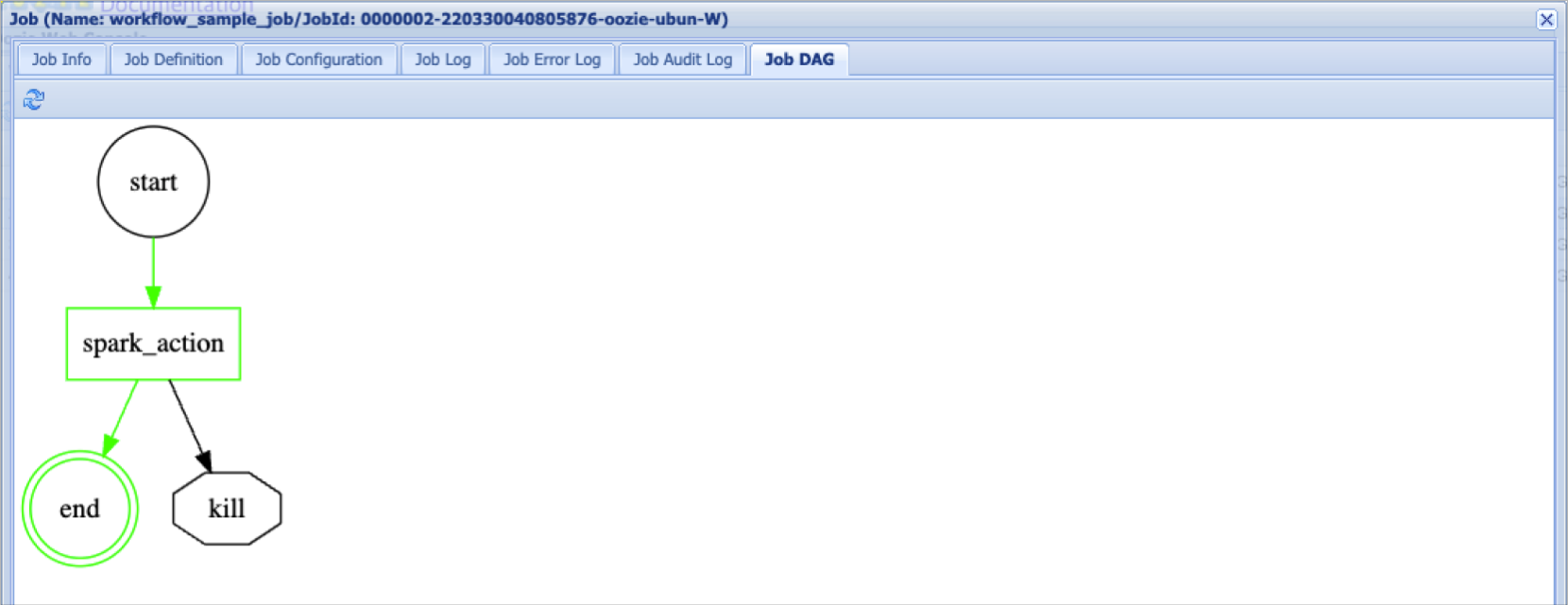
Oozie workflow job details
Zeppelin
Zeppelin is a user interface available in Hadoop Eco clusters of type Core Hadoop or Trino.
Access it via the quick link on the cluster details page.
Zeppelin access ports by high availability setting
| Cluster availability | Access port |
|---|---|
| Standard (Single) | Port 8180 of master node 1 |
| HA | Port 8180 of master node 3 |
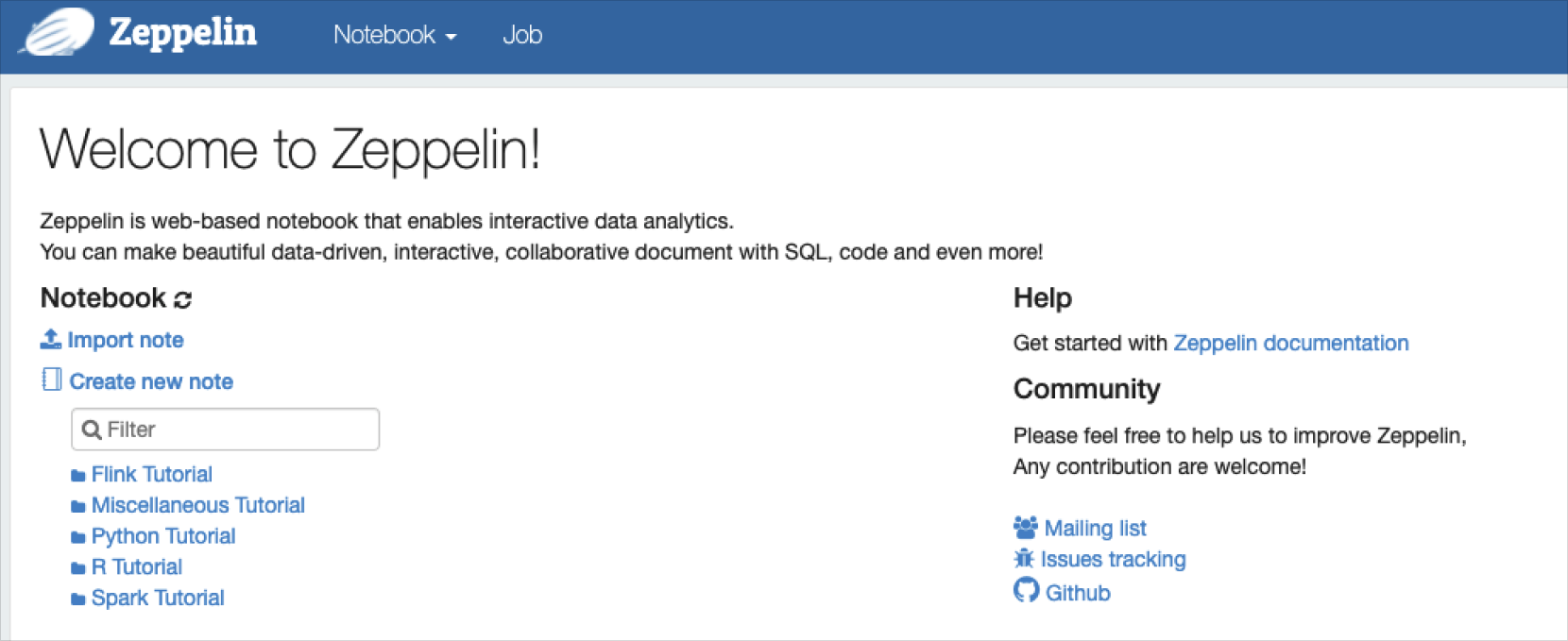
Zeppelin user interface
Interpreter
An interpreter is an environment that executes programming language source code directly.
Zeppelin provides interpreters for Spark, Hive, and Trino.
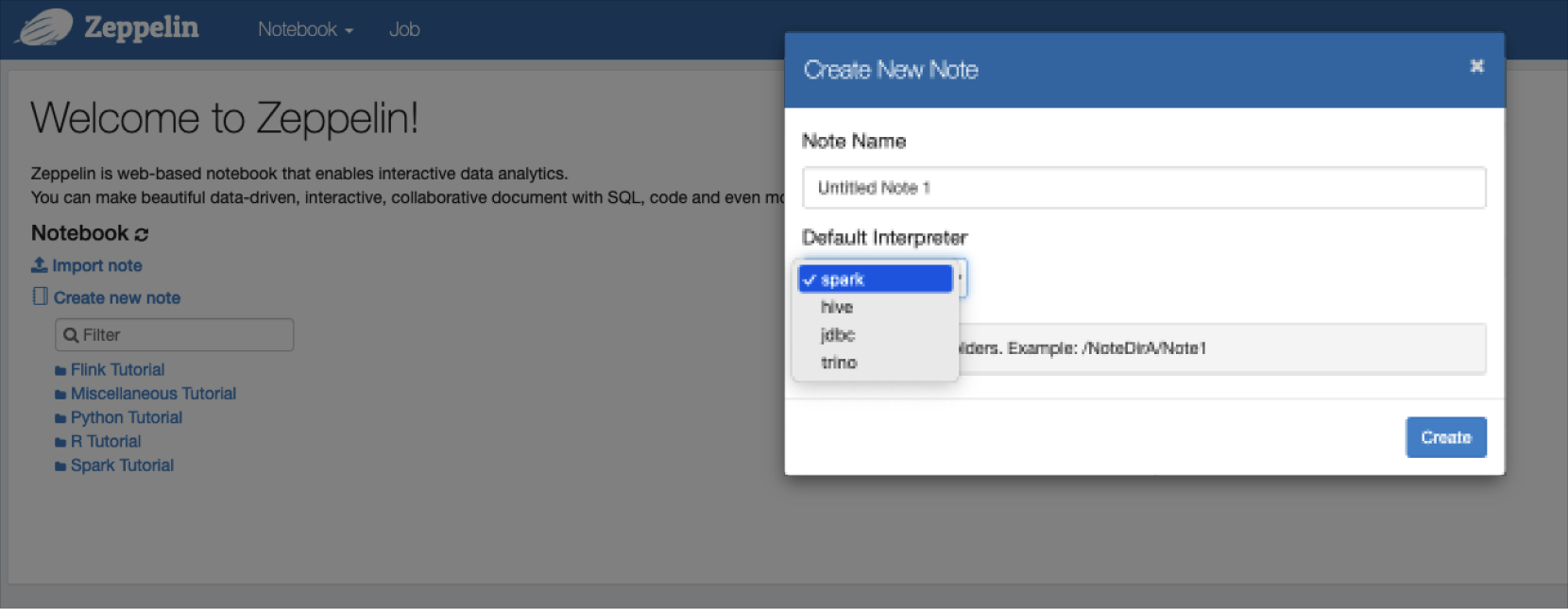
Using Zeppelin
Spark
-
Run the
spark-shellCLI on the master node and enter the test code.Run query using spark-shell CLIWelcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.2
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val count = sc.parallelize(1 to 90000000).filter { _ =>
| val x = math.random
| val y = math.random
| x*x + y*y < 1
| }.count()
count: Long = 70691442 -
Execute a Spark example file using the
spark-submitcommand on the master node.$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/spark/examples/jars/spark-examples_*.jar 100
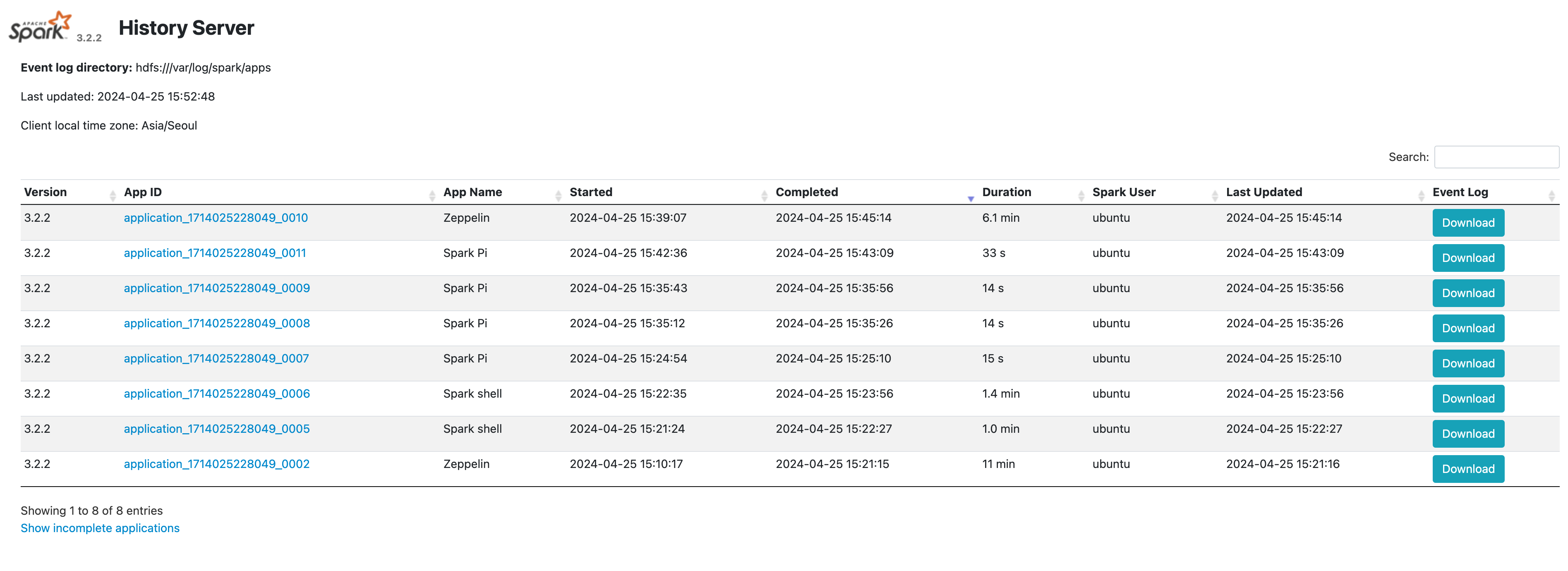
Access spark history server
-
Depending on the cluster’s high availability configuration, attach a public IP to the master node and access the spark history server.
Cluster availability Access port Standard (Single) Port 18082 on master node 1 HA Port 18082 on master node 3 -
Check job information via the history server.
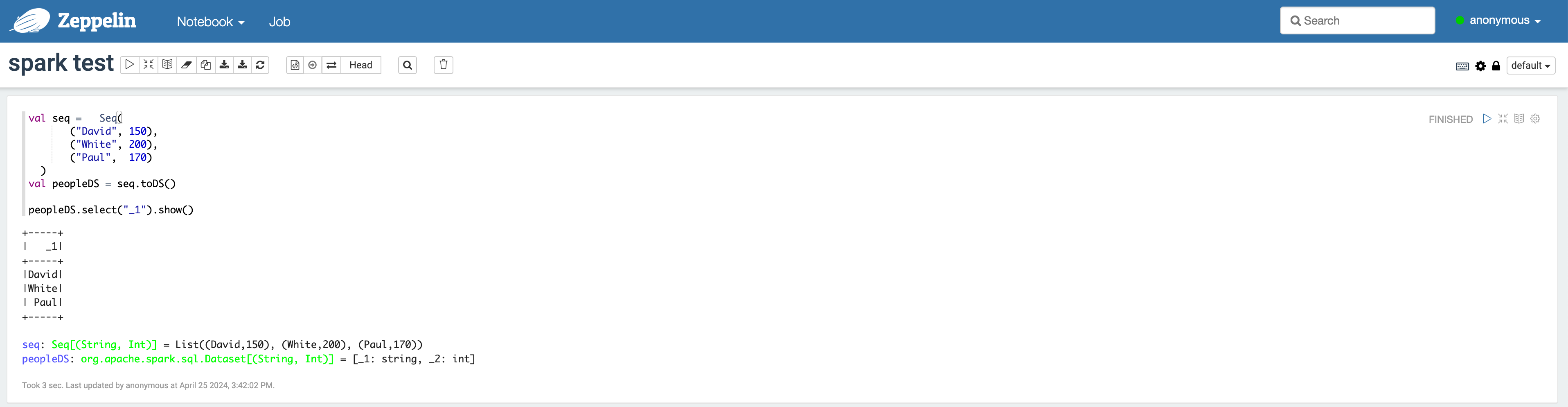
Integrate spark with Zeppelin
-
Attach a public IP to the master node where Zeppelin is installed, then access the Zeppelin UI.
For access instructions, refer to Zeppelin. -
Run spark-shell in Zeppelin
- From the top menu, select
Notebook > Create new note, and select thesparkinterpreter in the popup. - Enter the code in the Zeppelin notebook as shown below.
Check Trino-Zeppelin query result - From the top menu, select
-
Run pyspark in Zeppelin
- From the top menu, select
Notebook > Create new note, and select thesparkinterpreter in the popup. - Enter the code in the Zeppelin notebook as shown below.
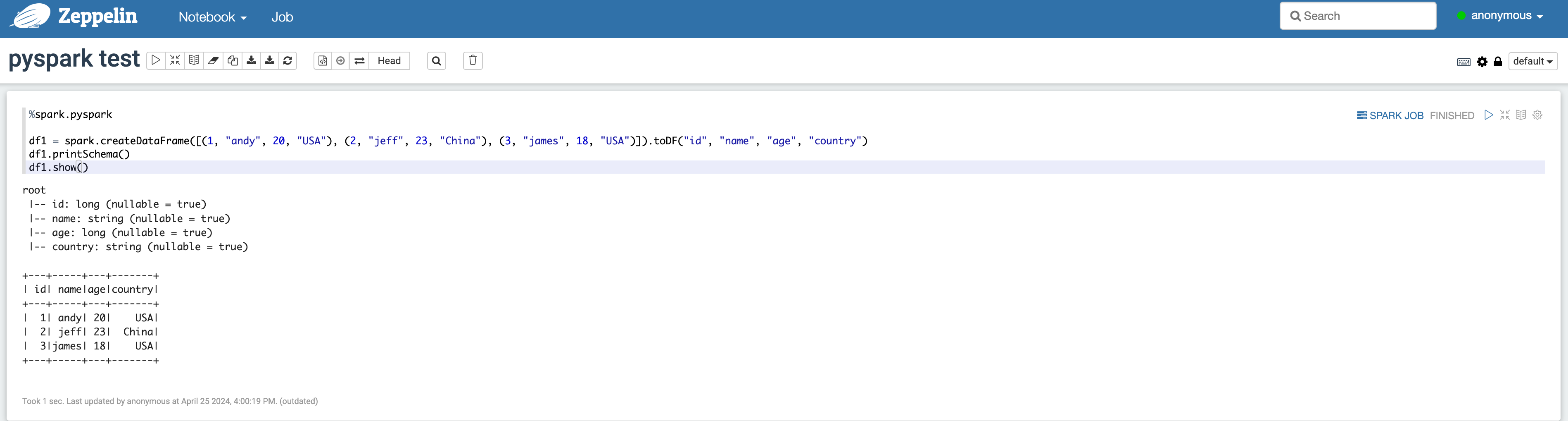
Check Trino-Zeppelin query result - From the top menu, select
-
Run spark-submit in Zeppelin
- From the top menu, select
Notebook > Create new note, and select thesparkinterpreter in the popup. - Enter the code in the Zeppelin notebook as shown below.
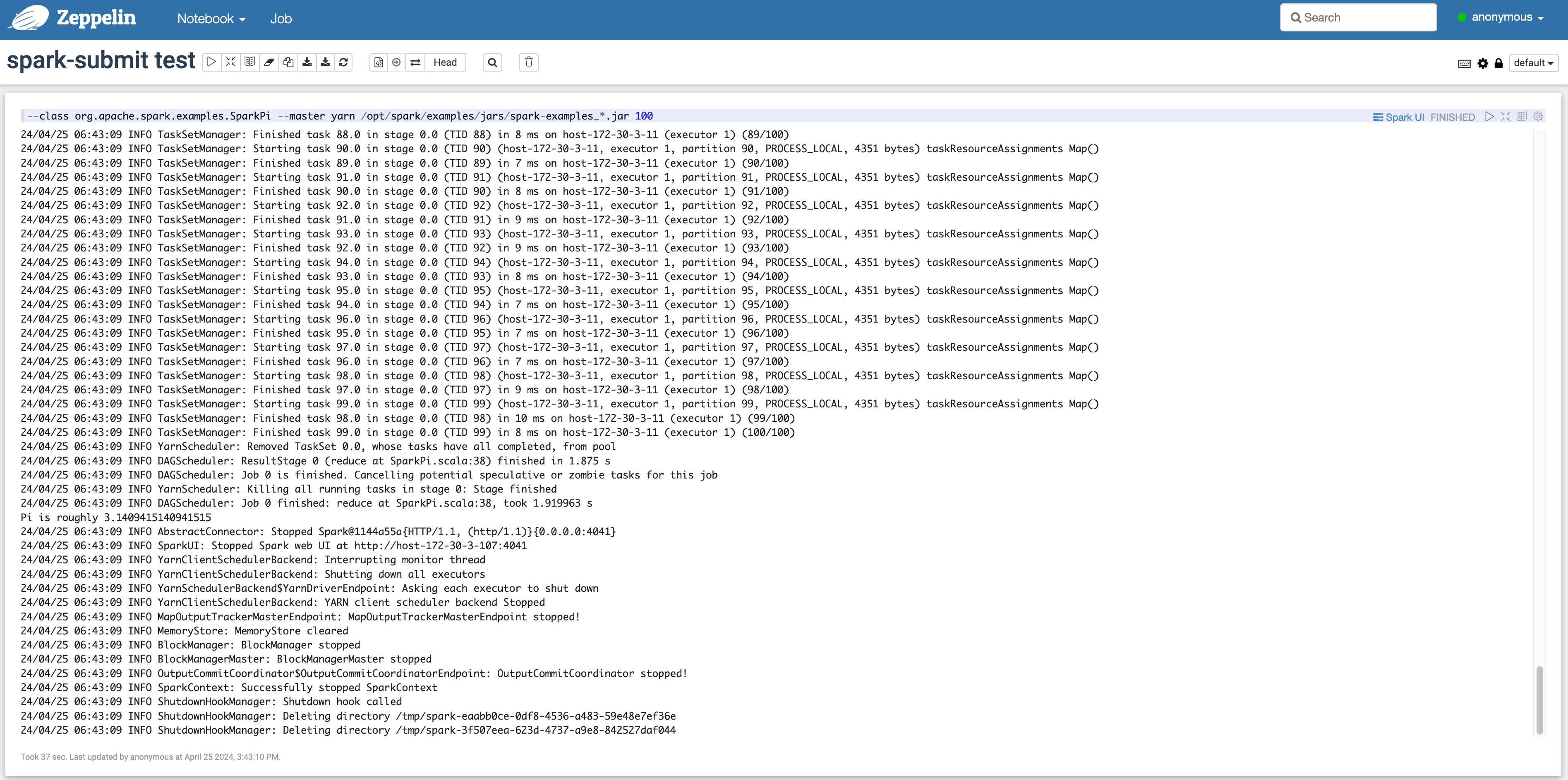
Check Trino-Zeppelin query result - From the top menu, select
Tez
Tez is a component that replaces the MapReduce engine in Hive to perform distributed data processing based on Yarn.
You can check information about Tez applications through the Tez Web UI.
-
To access the Tez Web UI, attach a public IP to either master node 1 or master node 3 depending on the cluster’s high availability configuration.
-
Then, add the hostname and public IP of master node 1 or 3 to the user's
/etc/hostsfile.
Once all settings are complete, you can access the UI as shown below.Cluster availability Access port Standard (Single) Port 9999 on master node 1 HA Port 9999 on master node 3 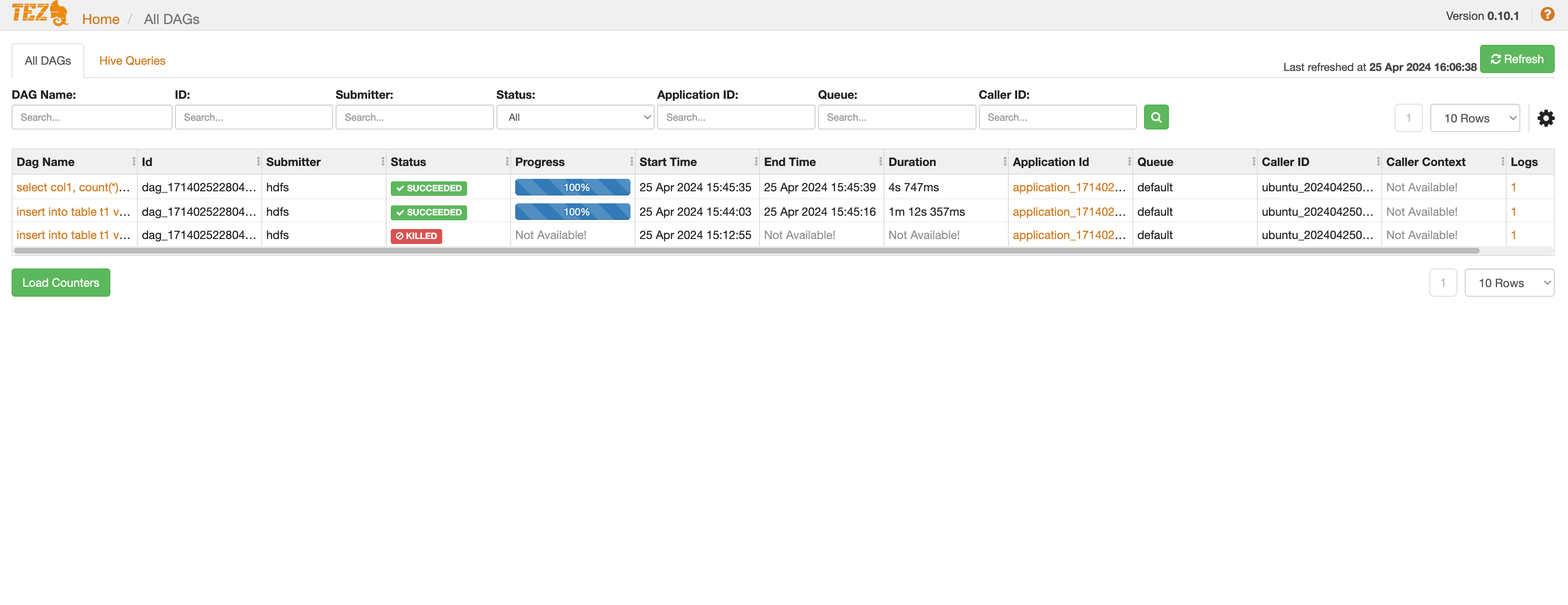
Check Trino-Zeppelin query result
Trino
-
Launch the Trino CLI. Enter the server information based on the location where the Trino coordinator is installed.
Cluster availability Access port Standard (Single) Port 8780 on master node 1 HA Port 8780 on master node 3 -
Enter the following queries.
Run query using Trino CLI$ trino --server http://hadoopmst-trino-ha-3:8780
trino> SHOW CATALOGS;
Catalog
---------
hive
system
(2 rows)
Query 20220701_064104_00014_9rp8f, FINISHED, 2 nodes
Splits: 12 total, 12 done (100.00%)
0.23 [0 rows, 0B] [0 rows/s, 0B/s]
trino> SHOW SCHEMAS FROM hive;
Schema
--------------------
default
information_schema
(2 rows)
Query 20220701_064108_00015_9rp8f, FINISHED, 3 nodes
Splits: 12 total, 12 done (100.00%)
0.23 [2 rows, 35B] [8 rows/s, 155B/s]
trino> select * from hive.default.t1;
col1
------
a
b
c
(3 rows)
Query 20220701_064113_00016_9rp8f, FINISHED, 1 node
Splits: 5 total, 5 done (100.00%)
0.23 [3 rows, 16B] [13 rows/s, 71B/s]
Access Trino web UI
-
Access the Trino web UI via port 8780 on the server where the Trino coordinator is installed.
Cluster availability Access port Standard (Single) Port 8780 on master node 1 HA Port 8780 on master node 3 -
View Trino query history and statistics.
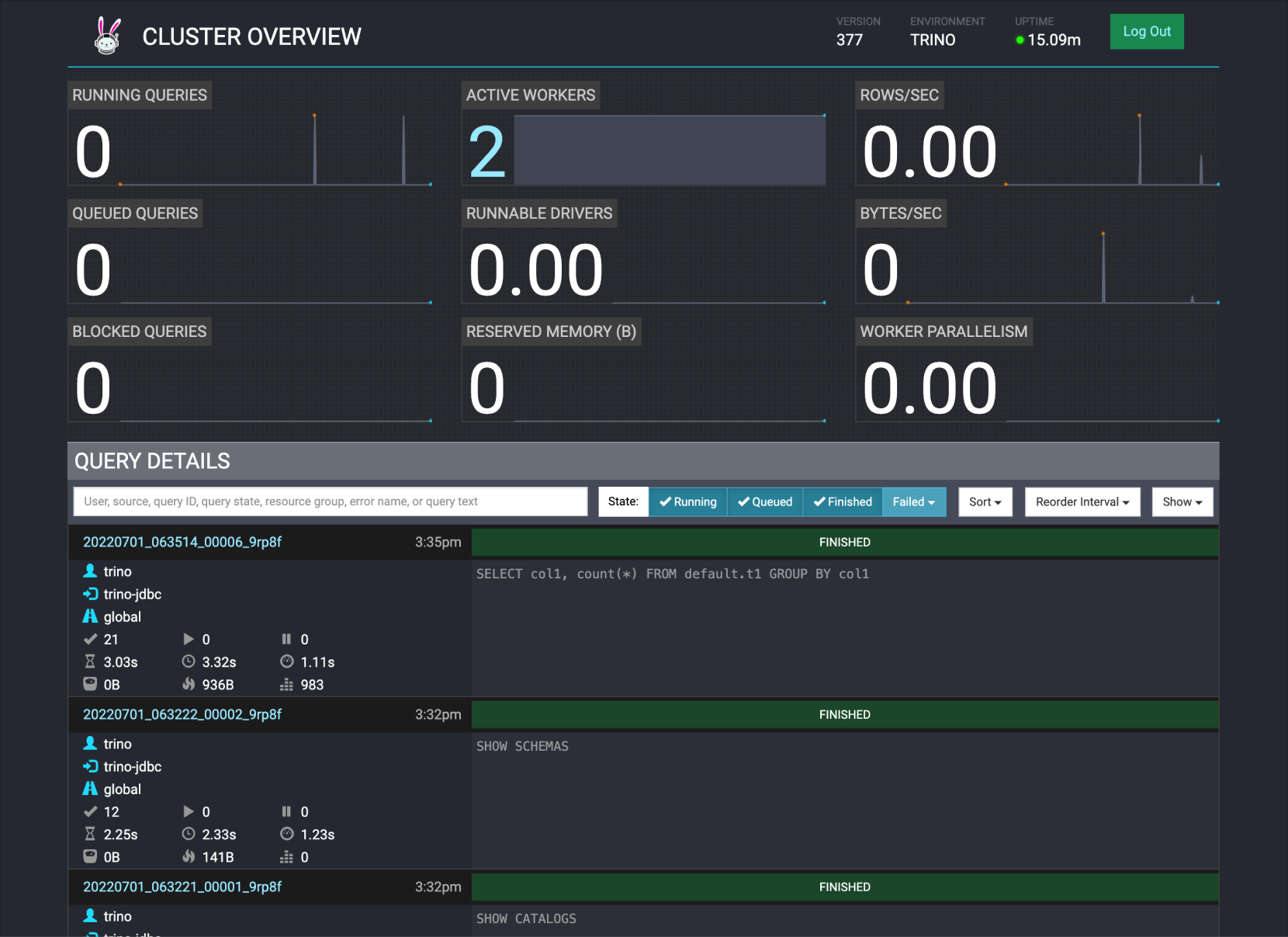
Trino web interface
Integrate Trino with Zeppelin
-
In Zeppelin, select
Trinoas the interpreter.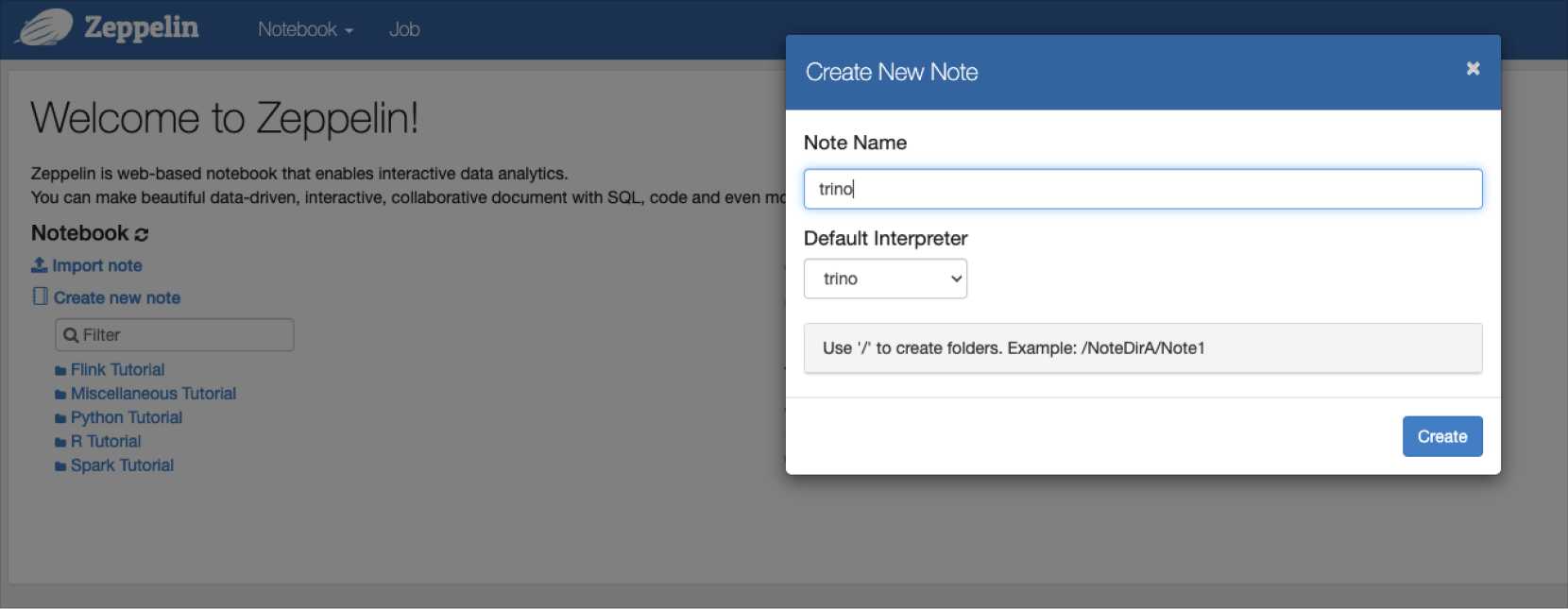
Trino-Zeppelin integration -
Enter the desired query for Trino and view the results.
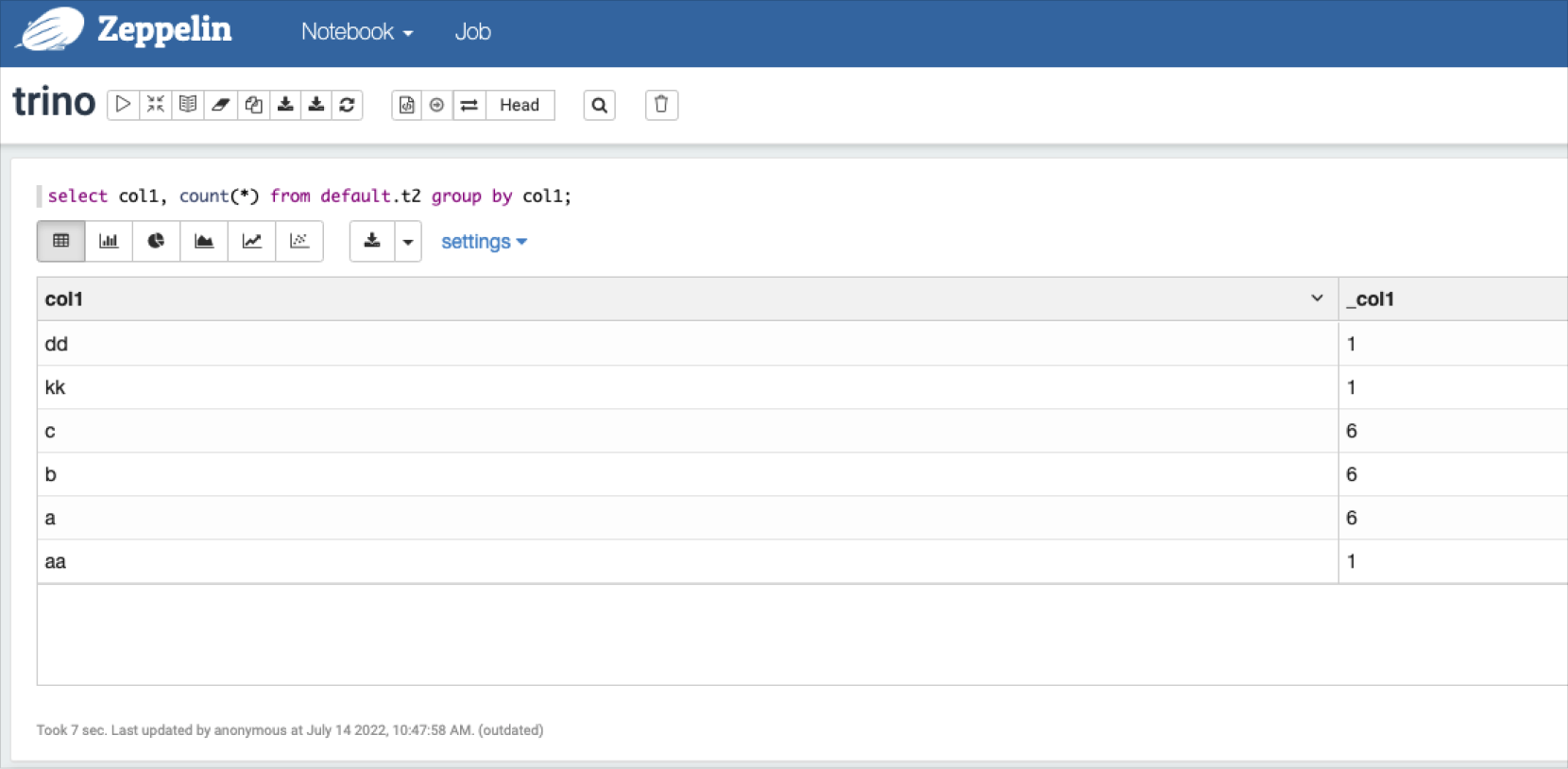
Trino-Zeppelin query result
Kafka
Apache Kafka is a large-scale real-time data streaming platform provided when the Hadoop Eco cluster type is set to Dataflow.
Kafka installed on a Hadoop Eco cluster can be operated using terminal commands. For further details beyond the examples below, refer to the official Kafka documentation.
-
Create topic
Create topic$ /opt/kafka/bin/kafka-topics.sh --create --topic my-topic --bootstrap-server $(hostname):9092 -
Write events to topic
Write events to topic$ echo '{"time":'$(date +%s)', "id": 1, "msg": "first event"}' | /opt/kafka/bin/kafka-console-producer.sh --topic my-topic --bootstrap-server $(hostname):9092
$ echo '{"time":'$(date +%s)', "id": 2, "msg": "second event"}' | /opt/kafka/bin/kafka-console-producer.sh --topic my-topic --bootstrap-server $(hostname):9092
$ echo '{"time":'$(date +%s)', "id": 3, "msg": "third event"}' | /opt/kafka/bin/kafka-console-producer.sh --topic my-topic --bootstrap-server $(hostname):9092 -
Check events
Check events$ /opt/kafka/bin/kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server $(hostname):9092
{"time":1692604787, "id": 1, "msg": "first event"}
{"time":1692604792, "id": 2, "msg": "second event"}
{"time":1692604796, "id": 3, "msg": "third event"}
Druid
Apache Druid is a real-time analytics database designed for fast, partitioned analysis of large datasets, and is available when the Hadoop Eco cluster type is set to Dataflow.
Druid supports various types of data sources and is well suited for building data pipelines.
Access the Druid UI from the cluster detail page via the quick link provided by the router.
UI access ports differ based on the Hadoop Eco cluster type.
Druid UI access ports by cluster type
| Cluster availability | Access port |
|---|---|
| Standard (Single) | Port 3008 on master node 1 |
| HA | Port 3008 on master node 3 |
Explore Druid UI
-
Ingestion jobs list
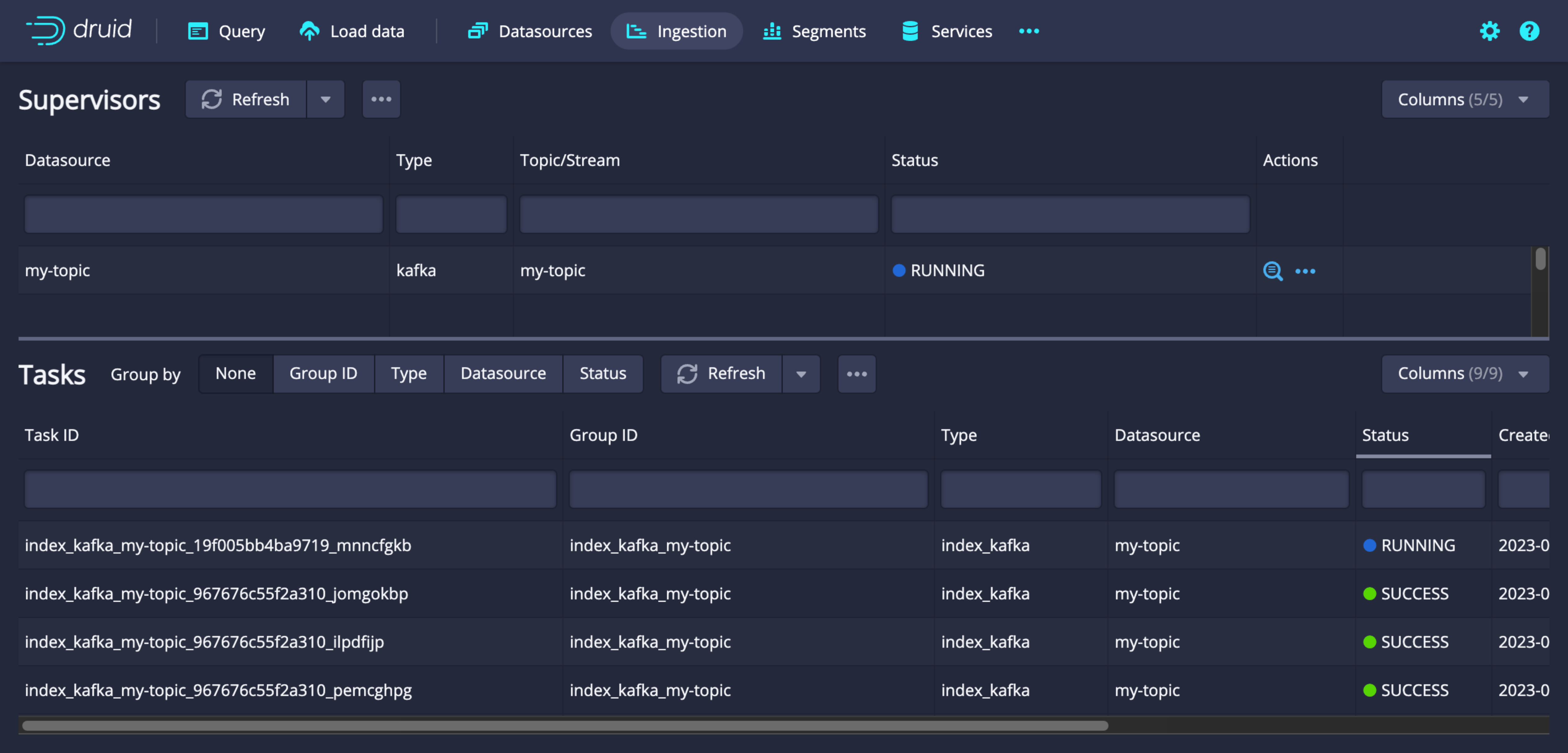
-
Datasource list
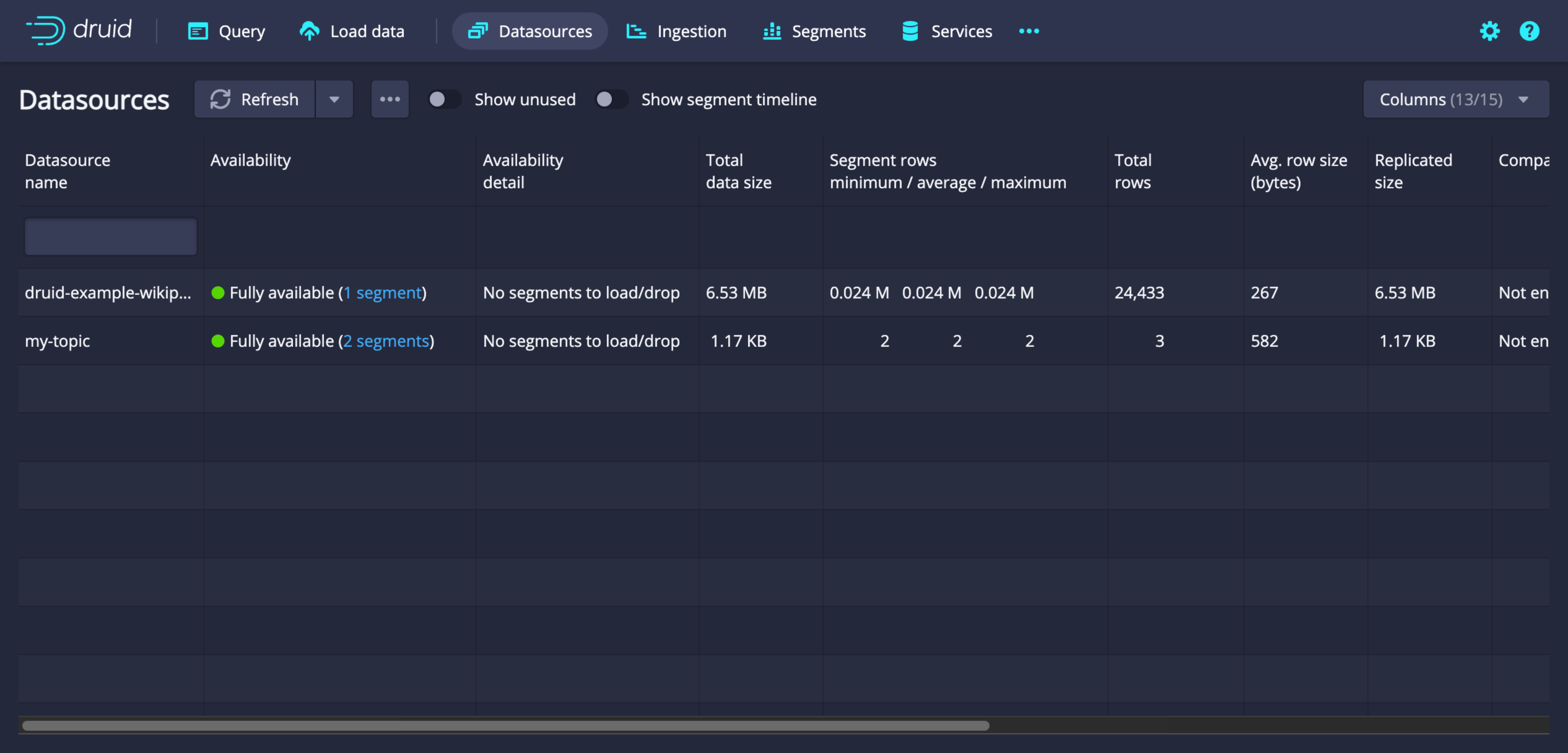
-
Query
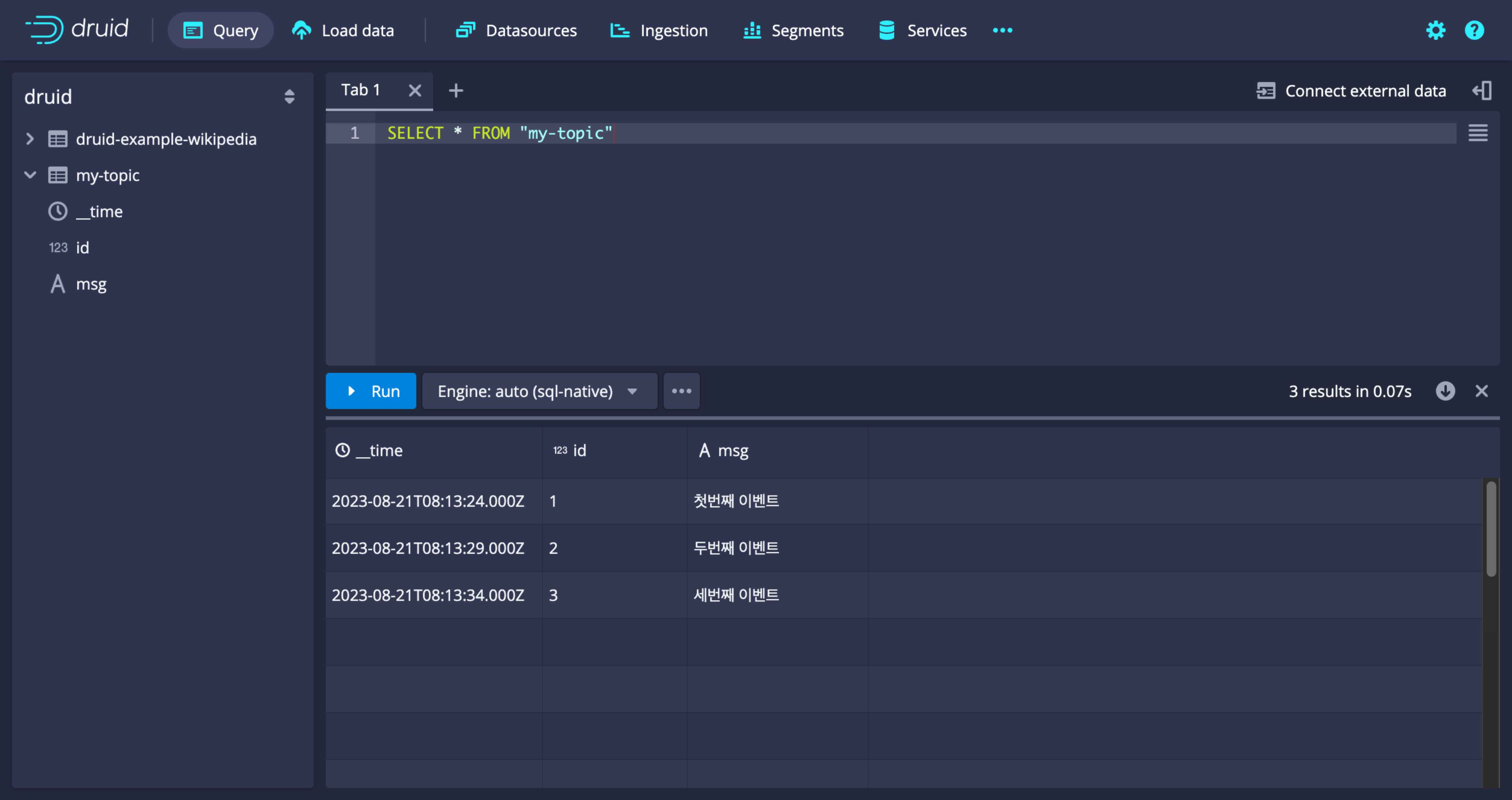
Load data from Kafka
-
In the Druid UI, go to the Load data tab and select Streaming. From the list of available data sources, choose Apache Kafka.
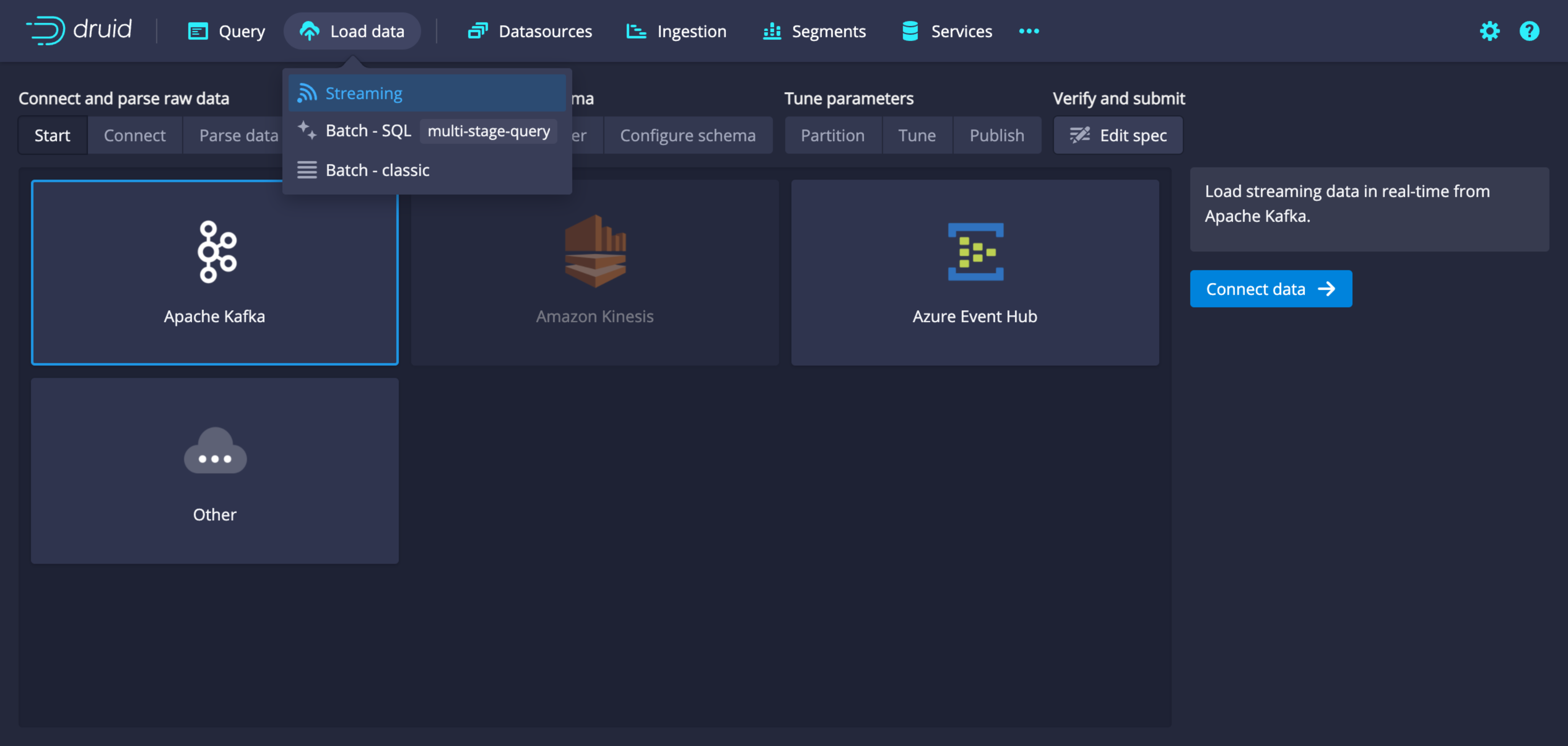
-
In the Bootstrap servers field, enter the Kafka host and port in the format
<hostname>:<port>. In the Topic field, enter the name of the topic you want to ingest.
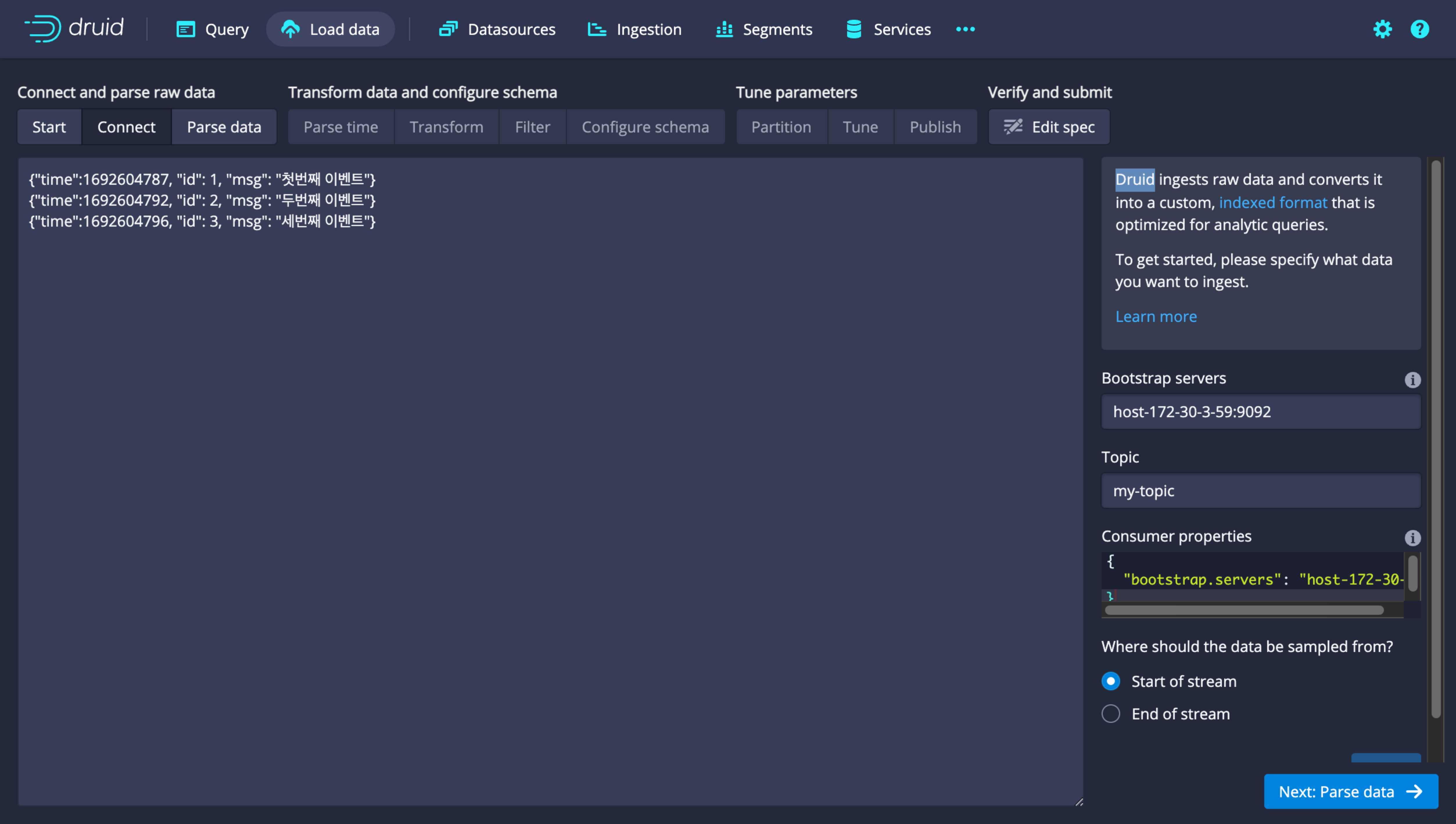
-
After selecting the topic, choose the desired data shape and schema on the next pages. On the final page, review the ingestion spec and submit the ingestion.
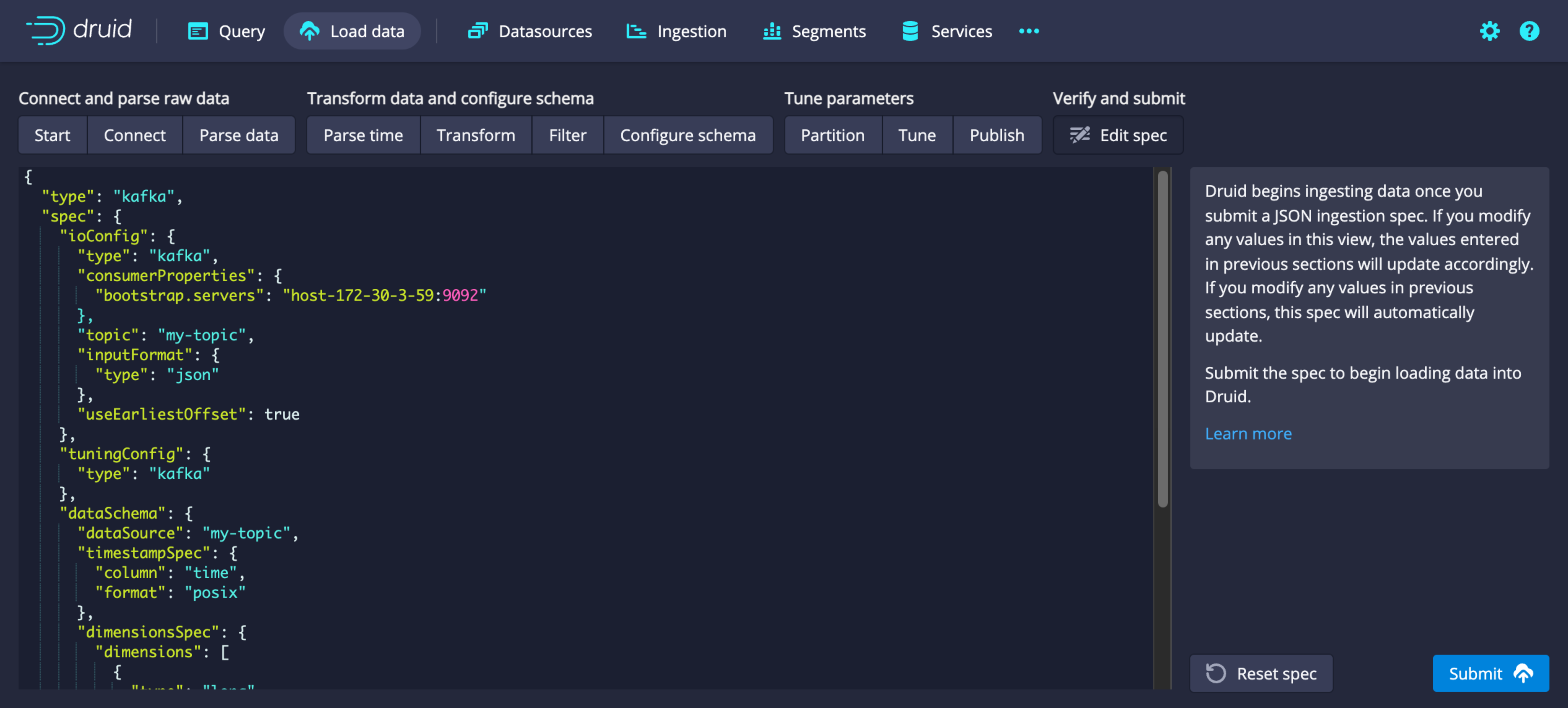
-
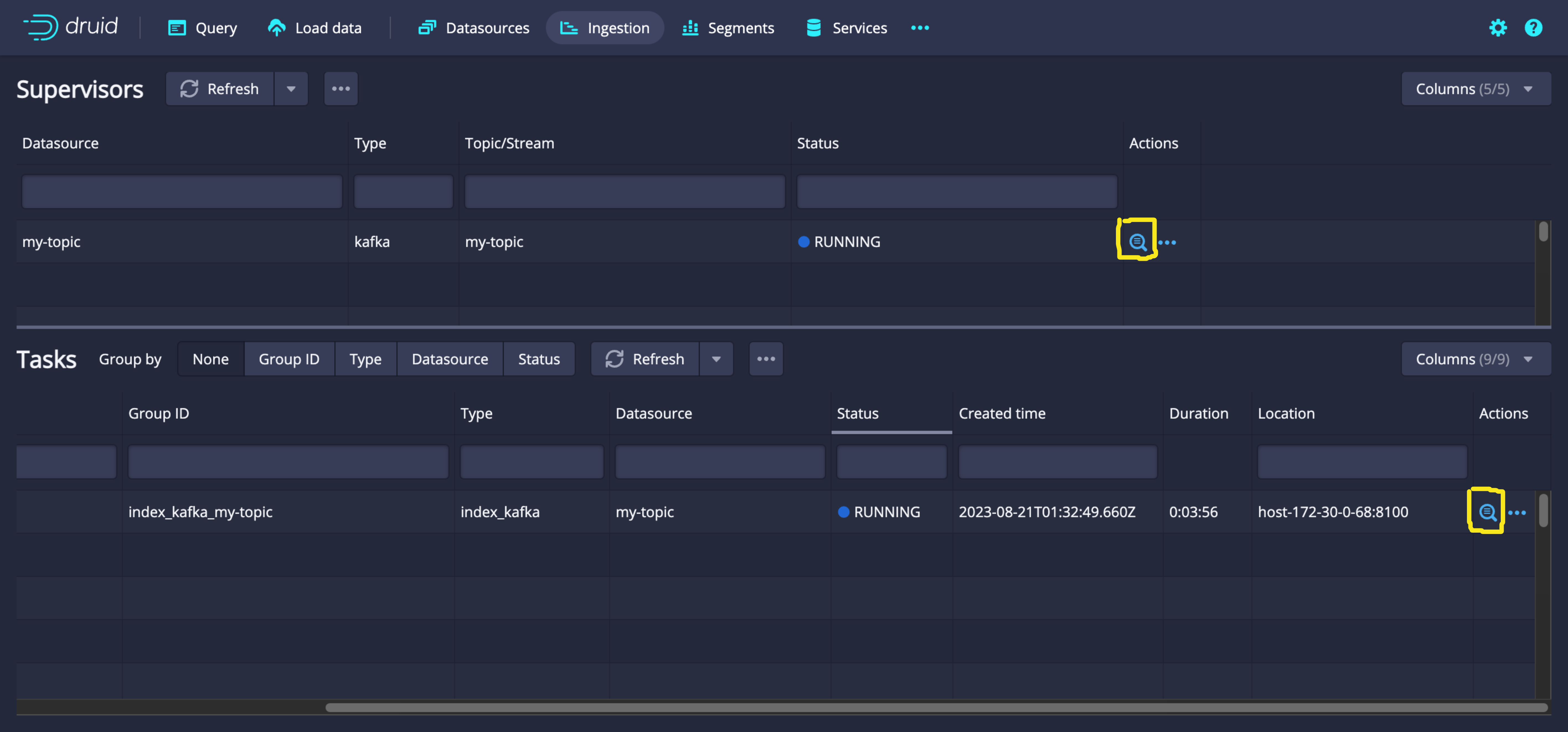
In the ingestion page, check the status of the created supervisor. Select the magnifying glass icon in the Actions column to view detailed logs and payload information.
Superset
Apache Superset is a data visualization and exploration platform available when the Hadoop Eco cluster type is set to Dataflow.
Superset supports various data sources (MySQL, SQLite, Hive, Druid, ...) and provides tools for query building, charting, dashboards, and more.
Access the Superset UI through the Superset link provided on the cluster detail page.
Superset UI access ports vary by Hadoop Eco cluster type.
Superset UI access ports by cluster type
| Cluster availability | Access port |
|---|---|
| Standard (Single) | Port 4000 on master node 1 |
| HA | Port 4000 on master node 3 |
Explore Superset UI
-
Dashboard list
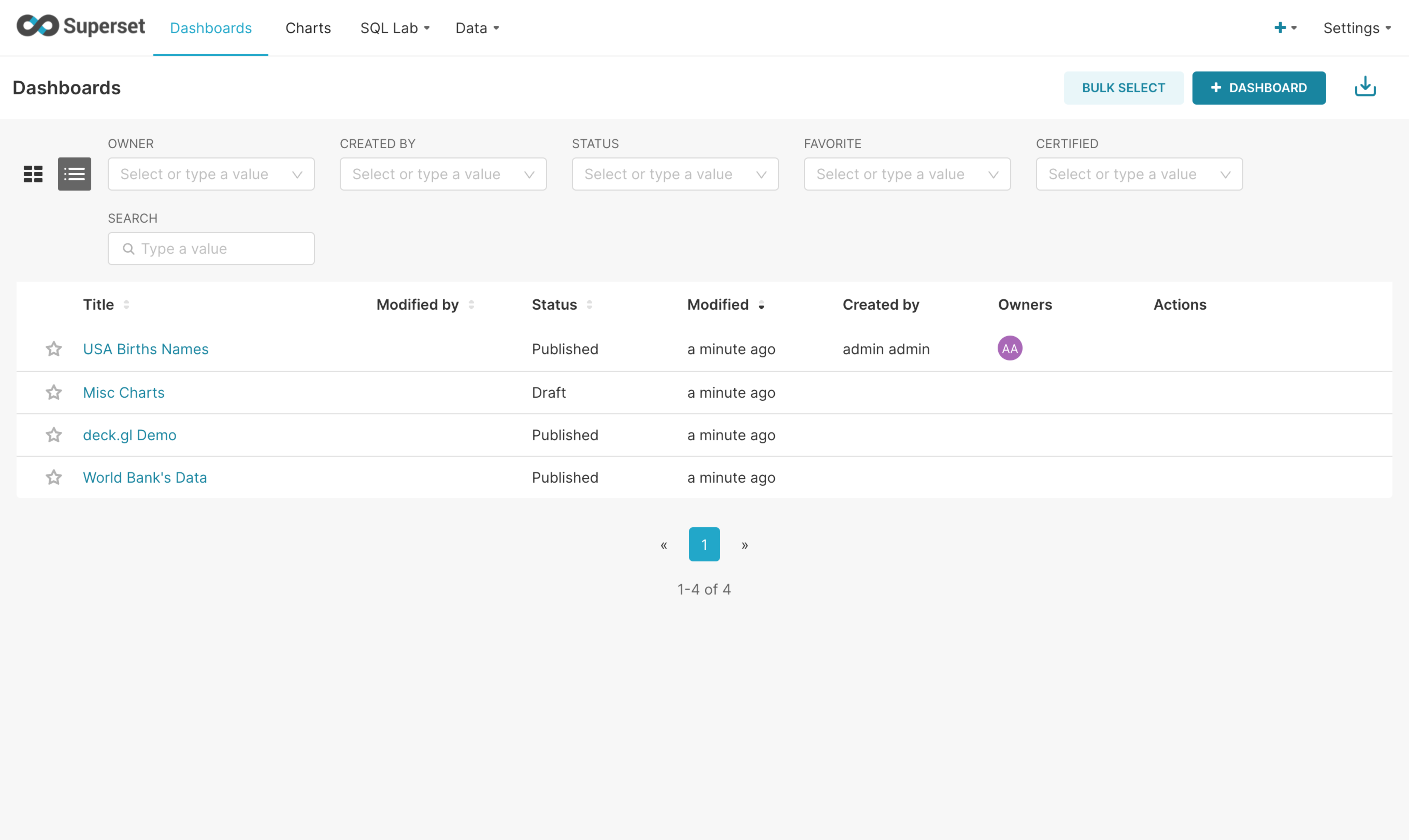
-
Dashboard: You can create and save dashboards, export them as images, or generate shareable links.
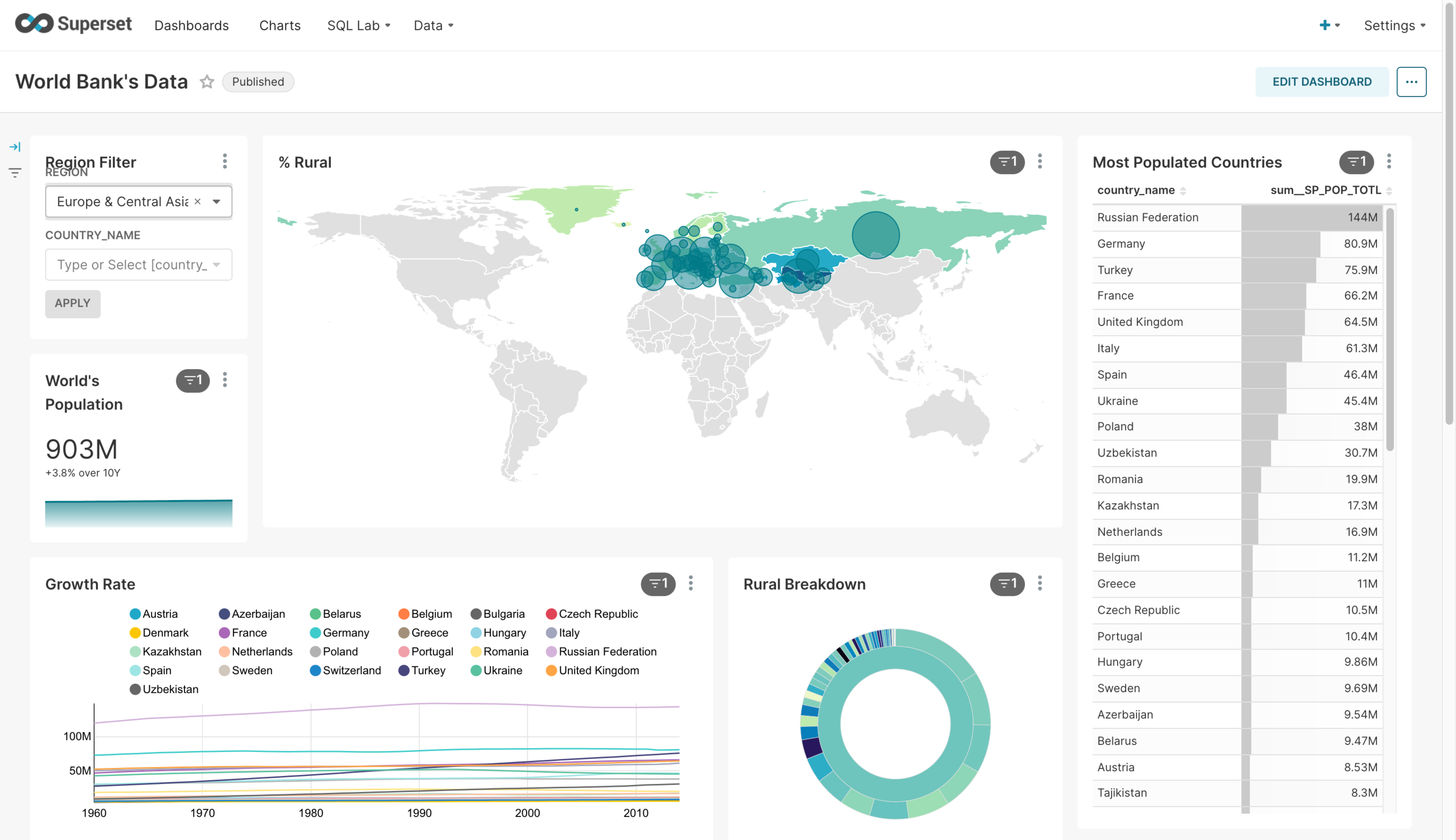
-
Charts: Create and save charts using registered physical datasets or virtual datasets based on queries from connected databases.
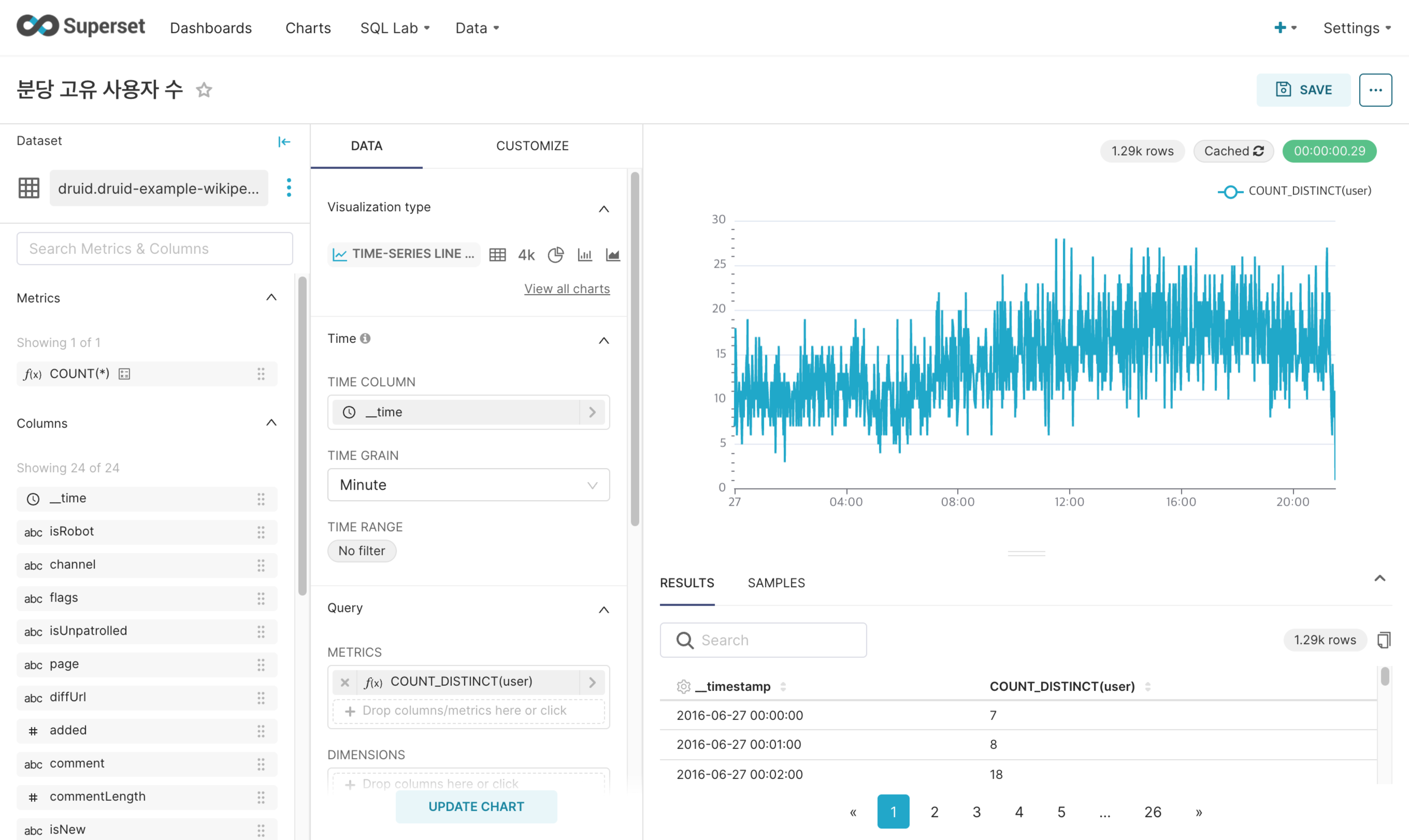
-
SQL Lab: Run queries on data from connected databases and check the results.
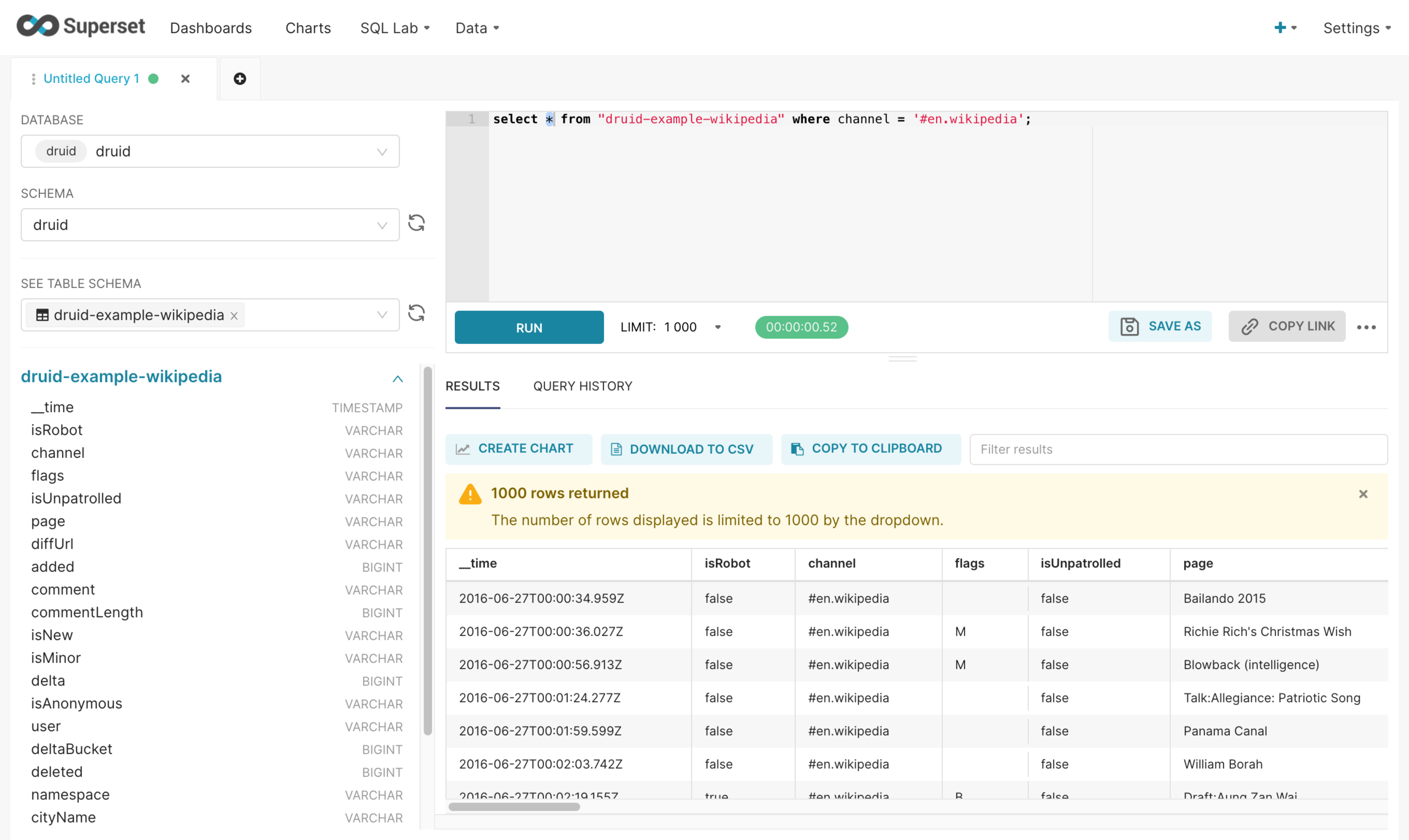
-
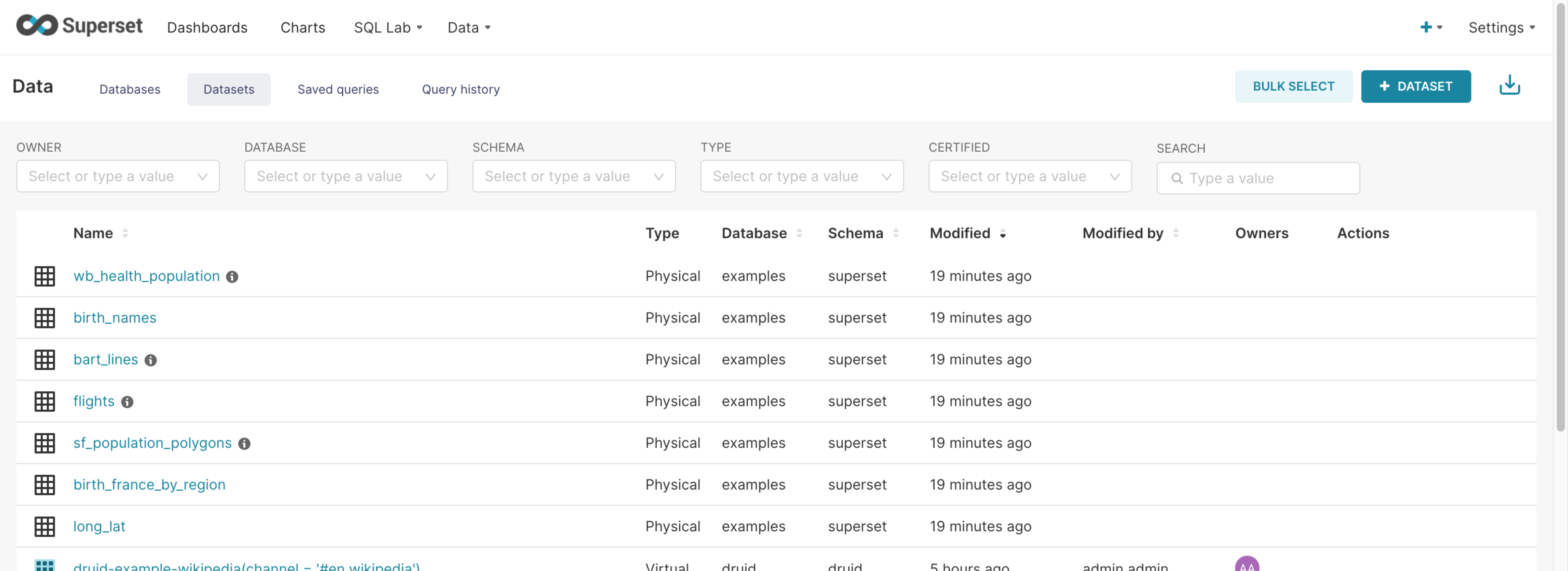
Data: Manage connected databases, created datasets, saved queries, and query history.
Run superset commands
Superset commands can be executed in the terminal as shown below.
# Set environment variables
$ export $(cat /opt/superset/.env)
# Example: run superset command
$ /opt/superset/superset-venv/bin/superset --help
Loaded your LOCAL configuration at [/opt/superset/superset_config.py]
Usage: superset [OPTIONS] COMMAND [ARGS]...
This is a management script for the Superset application.
Options:
--version Show the flask version
--help Show this message and exit.
Commands:
compute-thumbnails Compute thumbnails
db Perform database migrations.
export-dashboards Export dashboards to ZIP file
export-datasources Export datasources to ZIP file
fab FAB flask group commands
import-dashboards Import dashboards from ZIP file
import-datasources Import datasources from ZIP file
import-directory Imports configs from a given directory
init Inits the Superset application
load-examples Loads a set of Slices and Dashboards and a...
load-test-users Loads admin, alpha, and gamma user for...
re-encrypt-secrets
routes Show the routes for the app.
run Run a development server.
set-database-uri Updates a database connection URI
shell Run a shell in the app context.
superset This is a management script for the Superset...
sync-tags Rebuilds special tags (owner, type, favorited...
update-api-docs Regenerate the openapi.json file in docs
update-datasources-cache Refresh sqllab datasources cache
version Prints the current version number
Flink on Yarn Session
Apache Flink is an open-source, unified stream and batch processing framework developed by the Apache Software Foundation.
Below is how to run Flink in Yarn session mode.
Run flink
When running Flink in session mode, you can control the resources available to Flink using the options below.
| Option | Description |
|---|---|
| -jm | JobManager memory size |
| -tm | TaskManager memory size |
| -s | Number of CPU cores |
| -n | Number of TaskManagers |
| -nm | Application name |
| -d | Run in background |
yarn-session.sh \
-jm 2048 \
-tm 2048 \
-s 2 \
-n 3 \
-nm yarn-session-jobs
Flink interface
Once Flink is running, it launches on a Yarn node and its Web UI can be accessed at the following address:
2022-07-07 23:15:33,775 INFO org.apache.flink.shaded.curator4.org.apache.curator.framework.state.ConnectionStateManager [] - State change: CONNECTED
2022-07-07 23:15:33,800 INFO org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] - Starting DefaultLeaderRetrievalService with ZookeeperLeaderRetrievalDriver{connectionInformationPath='/leader/rest_server/connection_info'}.
JobManager Web Interface: http://hadoopwrk-logan-Standard(Single)-2:8082
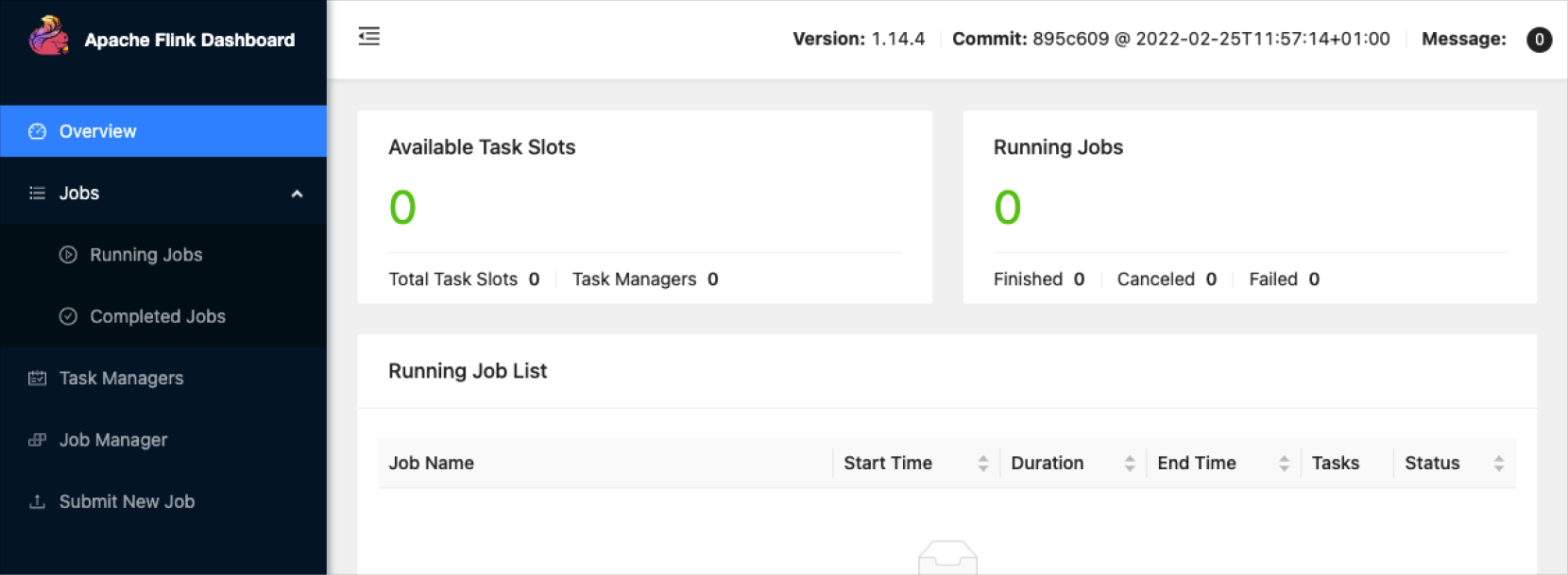
Flink web interface
Run flink job
After starting Flink on Yarn session mode, user jobs can be submitted and monitored via the web interface.
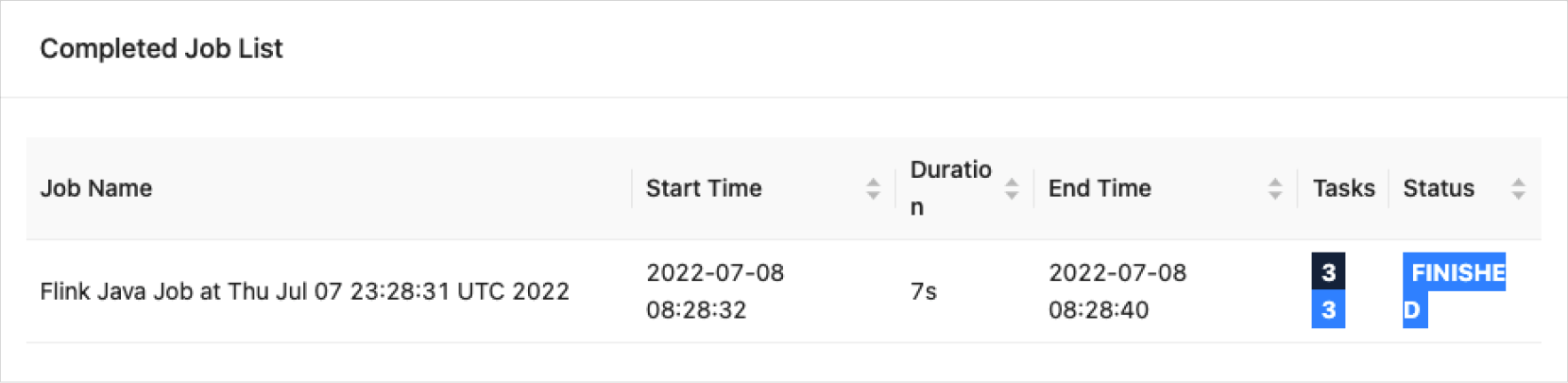
Flink job execution
$ flink run /opt/flink/examples/batch/WordCount.jar
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 43aee6d7d947b1ce848e01c094801ab4
Program execution finished
Job with JobID 43aee6d7d947b1ce848e01c094801ab4 has finished.
Job Runtime: 7983 ms
Accumulator Results:
- 4e3b3f0ae1b13d861a25c3798bc15c04 (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
Kakao HBase Tools
HBase Tools is an open-source project developed by Kakao.
In the KakaoCloud console, go to the Hadoop Eco menu.
In the cluster list, select the [More options] icon next to the cluster you want to delete > select Delete cluster.
In the confirmation popup, verify the target cluster and enter permanent delete, then select [Delete].
For more details, refer to the Kakao Tech Blog.
| Module | Description |
|---|---|
| hbase-manager Module | Region assignment management, splits, merges, and major compactions - Region Assignment Management - Advanced Split - Advanced Merge - Advanced Major Compaction |
| hbase-table-stat Module | Performance monitoring - Table Metrics Monitoring |
| hbase-snapshot Module | Backup and restore HBase data - Table Snapshot Management |
Run Kakao HBase Tools
Pass the Zookeeper host information to retrieve HBase data.
# hbase-manager
java -jar /opt/hbase/lib/tools/hbase-manager-1.2-1.5.7.jar <command> <zookeeper host name> <table name>
# hbase-snapshot
java -jar /opt/hbase/lib/tools/hbase-snapshot-1.2-1.5.7.jar <zookeeper host name> <table name>
# hbase-table-stat
java -jar /opt/hbase/lib/tools/hbase-table-stat-1.2-1.5.7.jar <zookeeper host name> <table name>
hbase-manager
Admin tool for managing HBase.

hbase-manager
hbase-table-stat
Tool for checking current table status.
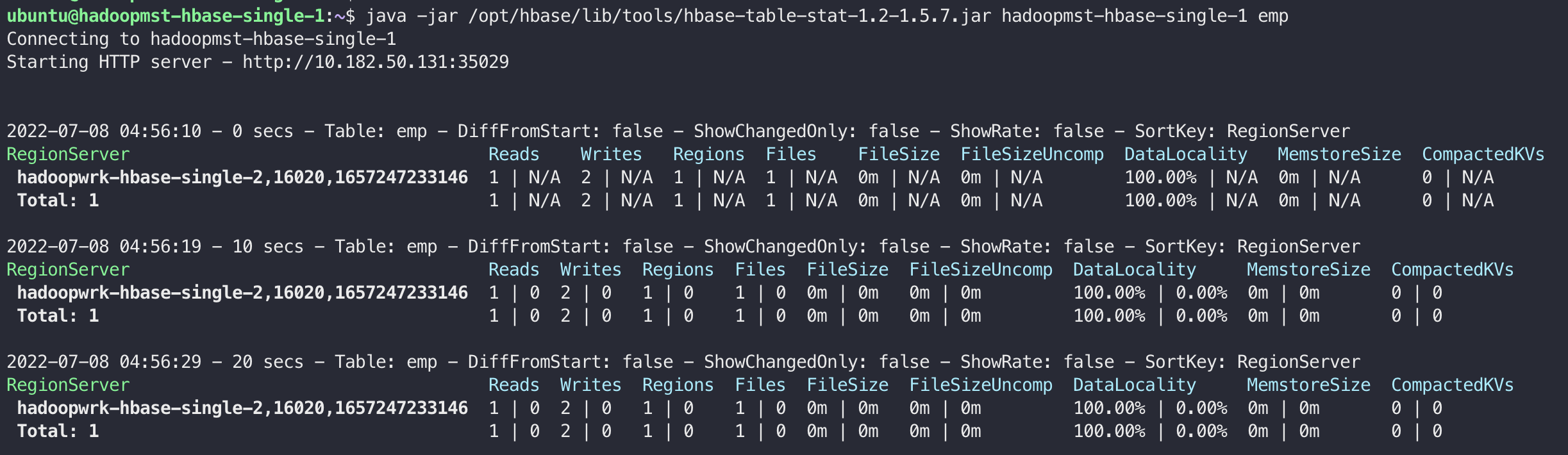
hbase-table-stat
hbase-snapshot
Tool for generating table data snapshots.

hbase-snapshot