Set up Oozie scheduling
Set up Oozie scheduling
Oozie is a workflow management tool available when the Hadoop Eco cluster type is set to Core Hadoop.
With Oozie, you can view bundles, workflows, coordinator lists, details, and logs. You can access Oozie from the quick link on the cluster detail page. Below is how to configure Oozie scheduling.
| Cluster type | Access port |
|---|---|
| Standard (Single) | Port 11000 on master node 1 |
| HA | Port 11000 on master node 3 |
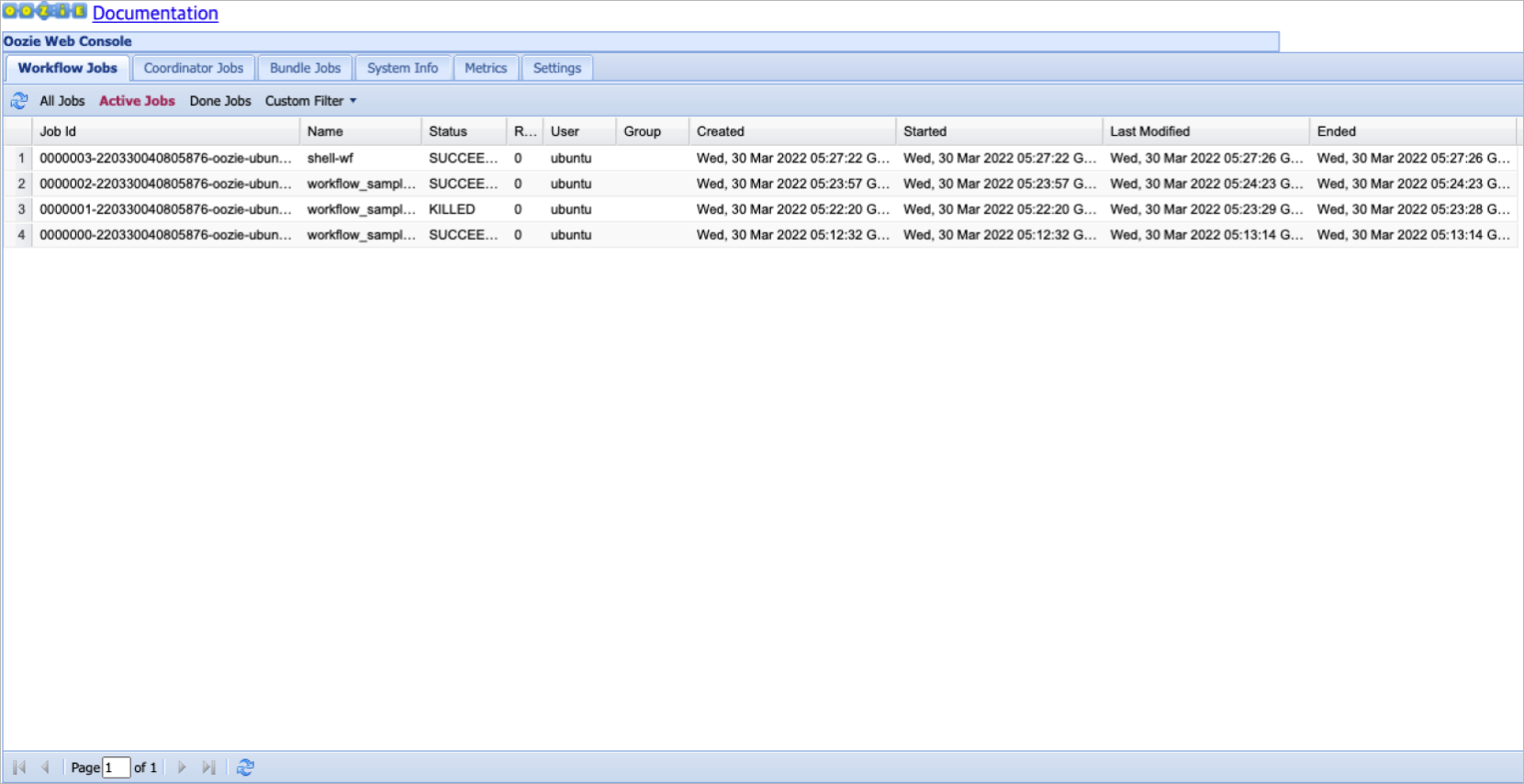
Oozie workflow list
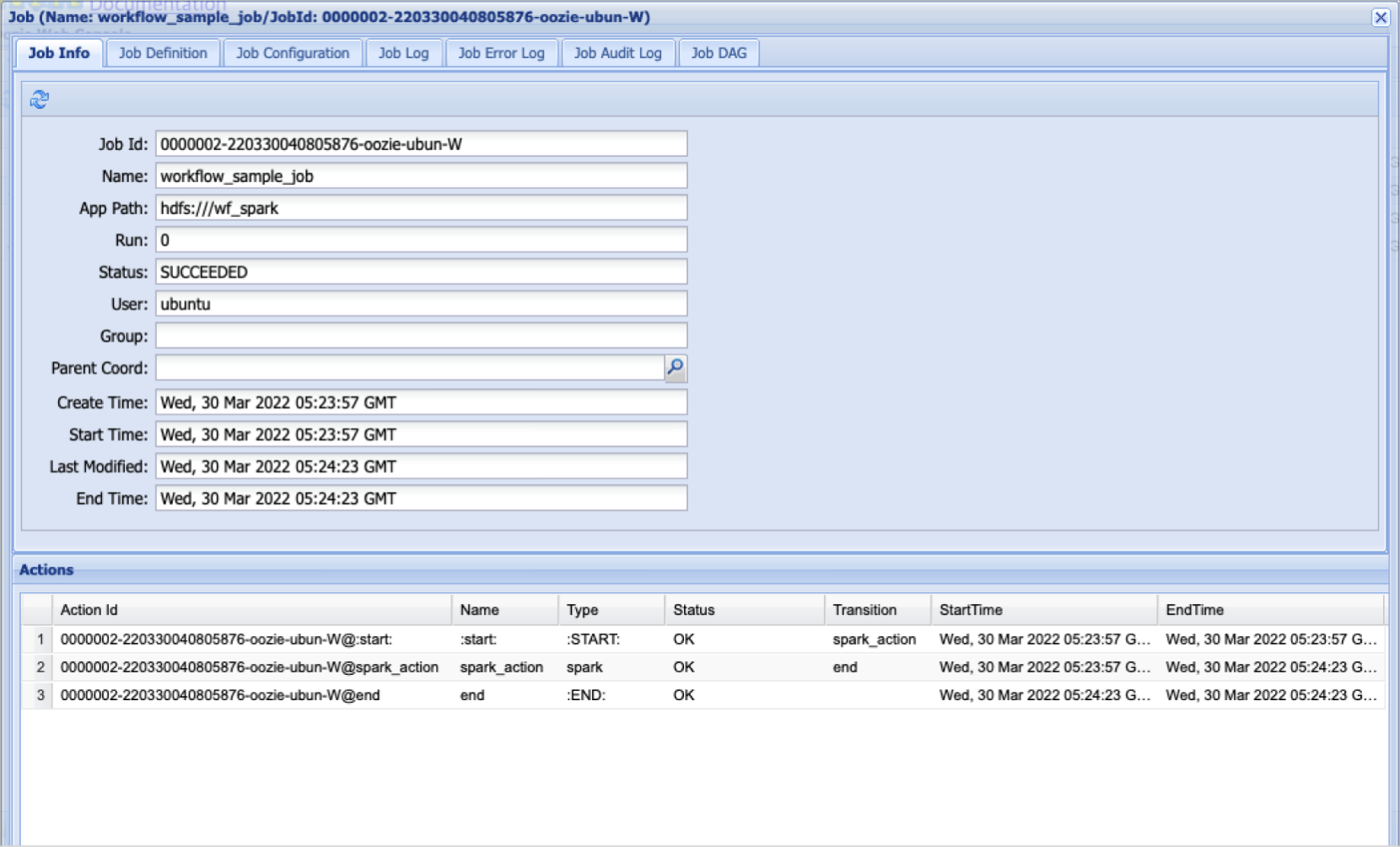
Oozie workflow job details
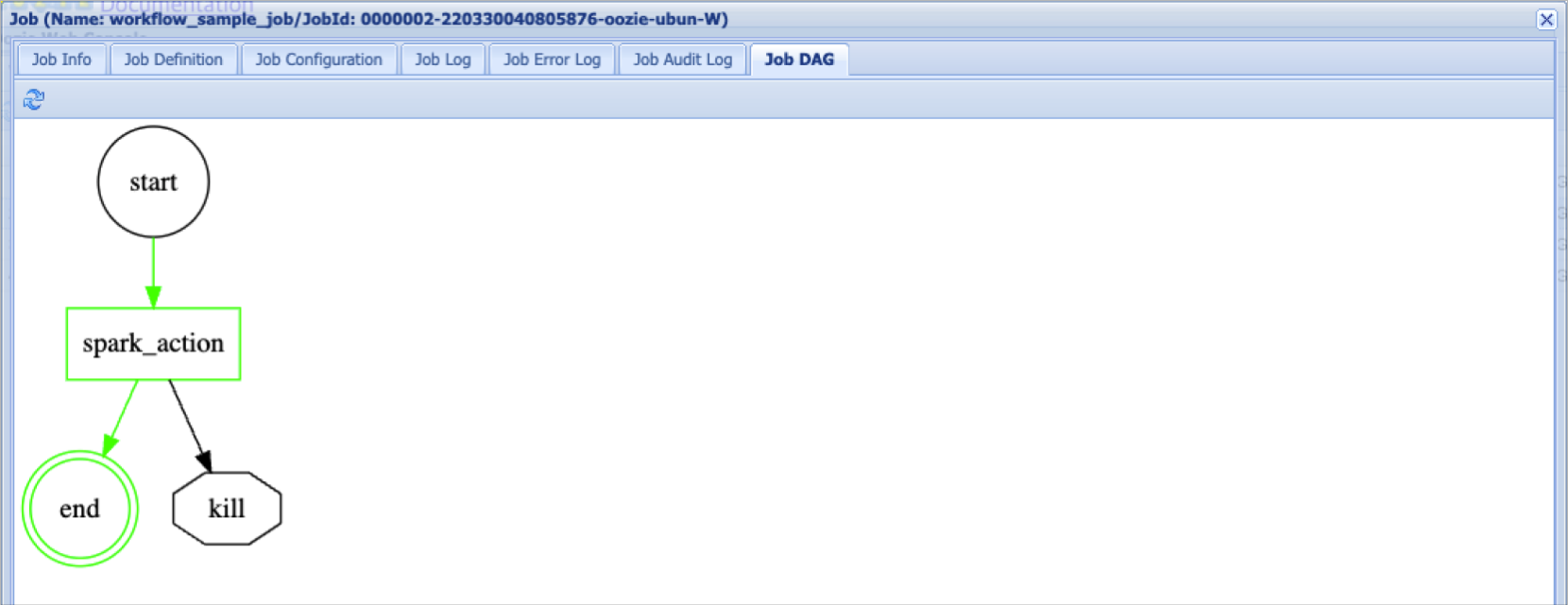
Oozie workflow job content
Prepare
To run an Oozie workflow, you need a workflow.xml file and supplementary execution files.
Upload these files to HDFS and specify the path in the wf.properties file to execute. A Hive job structure is shown below.
$ hadoop fs -ls hdfs:///wf_hive/
Found 3 items
-rw-r--r-- 2 ubuntu hadoop 22762 2022-03-30 05:11 hdfs:///wf_hive/hive-site.xml
-rw-r--r-- 2 ubuntu hadoop 168 2022-03-30 05:11 hdfs:///wf_hive/sample.hql
-rw-r--r-- 2 ubuntu hadoop 978 2022-03-30 05:11 hdfs:///wf_hive/workflow.xml
$ oozie job -run -config wf.properties
... [SLF4J log output] ...
job: 0000000-220330040805876-oozie-ubun-W
$ oozie job -info 0000000-220330040805876-oozie-ubun-W
... [SLF4J log output] ...
Job ID : 0000000-220330040805876-oozie-ubun-W
------------------------------------------------------------------------------------------------------------------------------------
Workflow Name : workflow_sample_job
App Path : hdfs:///wf_hive
Status : SUCCEEDED
Run : 0
User : ubuntu
Group : -
Created : 2022-03-30 05:12 GMT
Started : 2022-03-30 05:12 GMT
Last Modified : 2022-03-30 05:13 GMT
Ended : 2022-03-30 05:13 GMT
CoordAction ID: -
Actions
------------------------------------------------------------------------------------------------------------------------------------
ID Status Ext ID Ext Status Err Code
------------------------------------------------------------------------------------------------------------------------------------
0000000-220330040805876-oozie-ubun-W@:start: OK - OK -
0000000-220330040805876-oozie-ubun-W@hive_action OK application_1648613240828_0002SUCCEEDED -
0000000-220330040805876-oozie-ubun-W@end OK - OK -
Run Oozie workflow
You can run an Oozie workflow to configure scheduling.
-
Prepare workflow.xml and related execution files.
-
Create a folder in HDFS and upload the related files.
Upload files to HDFShadoop fs -put -
Set the execution path in the wf.properties file to the uploaded HDFS path.
- Configure
oozie.wf.application.path
- Configure
-
Run the Oozie job.
Run Oozie joboozie job -run -config wf.properties -
Check the result.
Check Oozie resultoozie job -info [workflow id]
Hive job example
In Standard (Single) and High Availability (HA) configurations, only the resource manager and name node values differ in the workflow.
- Standard (Single)
- High Availability (HA)
<workflow-app xmlns="uri:oozie:workflow:1.0" name="workflow_sample_job">
<start to="hive_action" />
<action name="hive_action">
<hive xmlns="uri:oozie:hive-action:1.0">
<resource-manager>hadoopmst-hadoop-single-1:8050</resource-manager>
<name-node>hdfs://hadoopmst-hadoop-single-1</name-node>
<job-xml>hive-site.xml</job-xml>
<configuration>
<property>
<name>hive.tez.container.size</name>
<value>2048</value>
</property>
<property>
<name>hive.tez.java.opts</name>
<value>-Xmx1600m</value>
</property>
</configuration>
<script>sample.hql</script>
</hive>
<ok to="end" />
<error to="kill" />
</action>
<kill name="kill">
<message>Error!!</message>
</kill>
<end name="end" />
</workflow-app>
$ cat sample.hql
create table if not exists t1 (col1 string);
insert into table t1 values ('a'), ('b'), ('c');
select col1, count(*) from t1 group by col1;
show tables;
show databases;
oozie.use.system.libpath=true
oozie.wf.application.path=hdfs:///wf_hive
user.name=ubuntu
<workflow-app xmlns="uri:oozie:workflow:1.0" name="workflow_sample_job">
<start to="hive_action" />
<action name="hive_action">
<hive xmlns="uri:oozie:hive-action:1.0">
<resource-manager>yarn-cluster:8050</resource-manager>
<name-node>hdfs://hadoop-ha</name-node>
<job-xml>hive-site.xml</job-xml>
<configuration>
<property>
<name>hive.tez.container.size</name>
<value>2048</value>
</property>
<property>
<name>hive.tez.java.opts</name>
<value>-Xmx1600m</value>
</property>
</configuration>
<script>sample.hql</script>
</hive>
<ok to="end" />
<error to="kill" />
</action>
<kill name="kill">
<message>Error!!</message>
</kill>
<end name="end" />
</workflow-app>
$ cat sample.hql
create table if not exists t1 (col1 string);
insert into table t1 values ('a'), ('b'), ('c');
select col1, count(*) from t1 group by col1;
show tables;
show databases;
oozie.use.system.libpath=true
oozie.wf.application.path=hdfs:///wf_hive
user.name=ubuntu
Spark job example
In Standard (Single) and High Availability (HA) configurations, the resource manager and name node values differ, along with the values passed via spark-opts.
Please be careful when configuring these parts.
- Standard (Single)
- High Availability (HA)
<workflow-app xmlns="uri:oozie:workflow:1.0" name="workflow_sample_job">
<start to="spark_action" />
<action name="spark_action">
<spark xmlns="uri:oozie:spark-action:1.0">
<resource-manager>hadoopmst-hadoop-single-1:8050</resource-manager>
<name-node>hdfs://hadoopmst-hadoop-single-1</name-node>
<master>yarn-client</master>
<name>Spark Example</name>
<class>org.apache.spark.examples.SparkPi</class>
<jar>/opt/spark/examples/jars/spark-examples_2.11-2.4.6.jar</jar>
<spark-opts>--executor-memory 2G --conf spark.hadoop.yarn.resourcemanager.address=hadoopmst-hadoop-single-1:8050 --conf spark.yarn.stagingDir=hdfs://hadoopmst-hadoop-single-1/user/ubuntu --conf spark.yarn.appMasterEnv.HADOOP_CONF_DIR=/etc/hadoop/conf --conf spark.io.compression.codec=snappy</spark-opts>
<arg>100</arg>
</spark>
<ok to="end" />
<error to="kill" />
</action>
<kill name="kill">
<message>Error!!</message>
</kill>
<end name="end" />
</workflow-app>
oozie.use.system.libpath=true
oozie.wf.application.path=hdfs:///wf_spark
user.name=ubuntu
<workflow-app xmlns="uri:oozie:workflow:1.0" name="workflow_sample_job">
<start to="spark_action" />
<action name="spark_action">
<spark xmlns="uri:oozie:spark-action:1.0">
<resource-manager>yarn-cluster:8050</resource-manager>
<name-node>hdfs://hadoop-ha</name-node>
<master>yarn-client</master>
<name>Spark Example</name>
<class>org.apache.spark.examples.SparkPi</class>
<jar>/opt/spark/examples/jars/spark-examples_2.11-2.4.6.jar</jar>
<spark-opts>--executor-memory 2G --conf spark.hadoop.yarn.resourcemanager.address=yarn-cluster:8050 --conf spark.yarn.stagingDir=hdfs://hadoop-ha/user/ubuntu --conf spark.yarn.appMasterEnv.HADOOP_CONF_DIR=/etc/hadoop/conf --conf spark.io.compression.codec=snappy</spark-opts>
<arg>100</arg>
</spark>
<ok to="end" />
<error to="kill" />
</action>
<kill name="kill">
<message>Error!!</message>
</kill>
<end name="end" />
</workflow-app>
oozie.use.system.libpath=true
oozie.wf.application.path=hdfs:///wf_spark
user.name=ubuntu
Shell job example
In Standard (Single) and High Availability (HA) configurations, only the resource manager and name node values differ. All other settings are the same.
- Standard (Single)
- High Availability (HA)
<workflow-app xmlns='uri:oozie:workflow:1.0' name='shell-wf'>
<start to='shell1' />
<action name='shell1'>
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>hadoopmst-hadoop-single-1:8050</resource-manager>
<name-node>hdfs://hadoopmst-hadoop-single-1</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>default</value>
</property>
</configuration>
<exec>echo.sh</exec>
<argument>A</argument>
<argument>B</argument>
<file>echo.sh#echo.sh</file>
</shell>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Script failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name='end' />
</workflow-app>
oozie.use.system.libpath=true
oozie.wf.application.path=hdfs:///wf_shell
user.name=ubuntu
<workflow-app xmlns='uri:oozie:workflow:1.0' name='shell-wf'>
<start to='shell1' />
<action name='shell1'>
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>yarn-cluster:8050</resource-manager>
<name-node>hdfs://hadoop-ha</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>default</value>
</property>
</configuration>
<exec>echo.sh</exec>
<argument>A</argument>
<argument>B</argument>
<file>echo.sh#echo.sh</file>
</shell>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Script failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name='end' />
</workflow-app>
oozie.use.system.libpath=true
oozie.wf.application.path=hdfs:///wf_shell
user.name=ubuntu