Kubeflow hyperparameter tuning
This tutorial provides a step-by-step guide on performing hyperparameter tuning on the MNIST dataset using Kubeflow and Katib on KakaoCloud.
- Estimated time: 10 minutes
- Recommended OS: MacOS, Ubuntu
- Reference docs:
- Note:
- In private network environments, training file downloads may not work properly.
About this scenario
Before performing hyperparameter tuning using Kubeflow and Katib, you will prepare the MNIST dataset and a minimal Kubeflow environment required for the exercise. This tutorial guides you in configuring optimal hyperparameter combinations to improve your model's performance.
Key topics include:
- Optimizing model performance through hyperparameter tuning
- Discovering the best hyperparameter combination using automated machine learning experiments
- Hands-on practice with the MNIST dataset for hyperparameter tuning
Supported tools
| Tool | Version | Description |
|---|---|---|
| Katib | 0.18.0 | - An open-source project for improving model performance by tuning hyperparameters. - Enables testing a wide range of hyperparameter combinations. |
For more details about Katib, refer to the Kubeflow > Katib official documentation.
Before you start
1. Prepare training data
This exercise uses the MNIST dataset. The dataset will be automatically downloaded during the tutorial steps, so no manual download is necessary.
 MNIST image dataset
MNIST image dataset
The MNIST dataset contains grayscale images of handwritten digits (0 through 9) and is widely used in the field of computer vision. It consists of 70,000 images, each 28x28 pixels.
2. Set up Kubeflow environment
Before using Katib in Kubeflow, ensure that your environment meets the proper MIG and GPU node pool requirements. If you haven’t set up Kubeflow yet, refer to Deploy Jupyter Notebooks on Kubeflow and create an environment with a GPU pipeline node pool.
Minimum requirements
- MIG setup: At least 3 instances of 1g.10gb
- GPU pipeline node pool is required
- Node pool size: 100GB or more
Getting started
The following steps walk through hyperparameter tuning on the MNIST dataset using Katib.
Step 1. Create new experiment with example YAML
- Log in to the Kubeflow dashboard.
- Select the Experiments (AutoML) tab on the left panel.
- Click the [NEW EXPERIMENT] button on the top right.
- In the Create an experiment screen, click [Edit and submit YAML], paste the example YAML below, and click [CREATE].
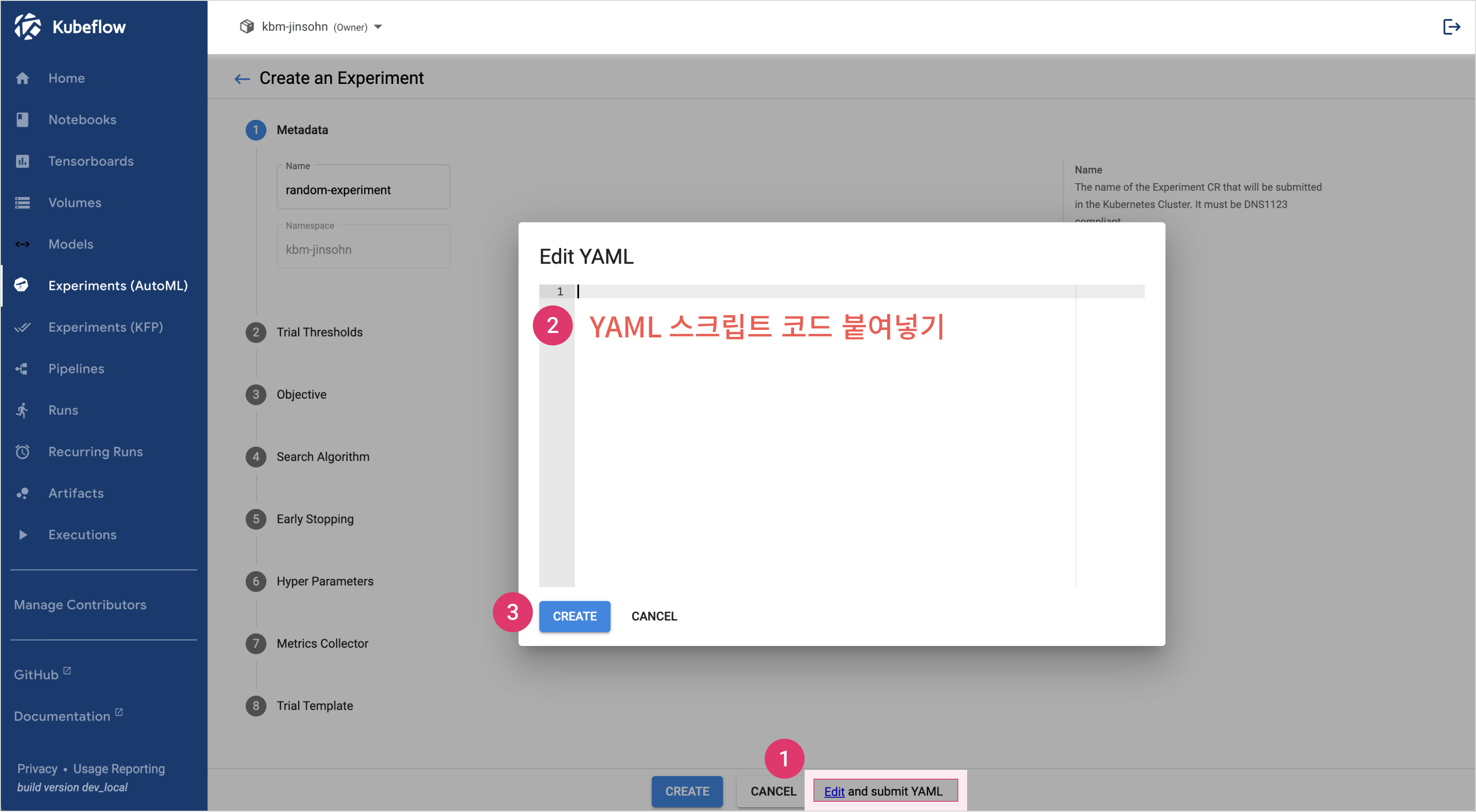
YAML script example
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
namespace: kubeflow
name: test-automl2
spec:
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy
additionalMetricNames:
- loss
metricsCollectorSpec:
source:
filter:
metricsFormat:
- "{metricName: ([\\w|-]+), metricValue: ((-?\\d+)(\\.\\d+)?)}"
fileSystemPath:
path: "/katib/mnist.log"
kind: File
collector:
kind: File
algorithm:
algorithmName: random
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
parameters:
- name: lr
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.03"
- name: momentum
parameterType: double
feasibleSpace:
min: "0.3"
max: "0.7"
trialTemplate:
retain: true
primaryContainerName: training-container
trialParameters:
- name: learningRate
description: Learning rate for the training model
reference: lr
- name: momentum
description: Momentum for the training model
reference: momentum
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
metadata:
annotations:
sidecar.istio.io/inject: 'false'
spec:
containers:
- name: training-container
image: image: mlops.kr-central-2.kcr.dev/kc-kubeflow-registry/katib-pytorch-mnist-gpu:v0.18.0.kbm.1a
command:
- "python3"
- "/opt/pytorch-mnist/mnist.py"
- "--epochs=1"
- "--log-path=/katib/mnist.log"
- "--lr=${trialParameters.learningRate}"
- "--momentum=${trialParameters.momentum}"
resources:
requests:
cpu: '1'
memory: 2Gi
limits:
nvidia.com/mig-1g.10gb: 1
restartPolicy: Never
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kakaoi.io/kke-nodepool
operator: In
values:
- ${GPU_PIPELINE_NODEPOOL_NAME}
| 환경변수 | 설명 |
|---|---|
| GPU_PIPELINE_NODEPOOL_NAME🖌︎ | Insert your GPU pipeline node pool name, e.g. "gpu-node" |
This YAML defines the configuration of the Katib experiment, including its objective, optimization metric, algorithm, hyperparameter search space, and trial template.
Step 2. Verify created experiment
-
After running the experiment, go to the Experiments (AutoML) tab in the Kubeflow dashboard to check the results.
-
If the experiment ran successfully, click on it to view detailed information and the optimal hyperparameter values.
For more information on Katib, see the Kubeflow > Katib official documentation.