Parallel training with Kubeflow MIG
This tutorial introduces how to implement parallel training models using MIG (Multi-Instance GPU) instances and the Training Operator in the Kubeflow environment provided by KakaoCloud.
- Estimated time: 10 minutes
- Recommended OS: macOS, Ubuntu
- Reference
- Note
- In private network environments, training file downloads may not work properly.
About this scenario
This tutorial describes how to implement a parallel training model using MIG (Multi-Instance GPU) settings in KakaoCloud’s Kubeflow notebooks and pipelines.
This allows for efficient GPU resource management, faster training, and familiarization with parallel model training techniques.
We use the Fashion MNIST dataset to walk through the process of applying MIG functionality and Training Operator in a Kubeflow environment to implement parallel model training.
Key topics:
- Optimize GPU resources using MIG configuration
- Set up distributed training using Training Operator in Kubeflow
- Train a prediction model using the Fashion MNIST dataset
- Improve training efficiency and resource management
Supported tools
| Tool | Version | Description | Supported frameworks |
|---|---|---|---|
| Training Operator | v1.9.0 | - Supports distributed training with various deep learning frameworks - Enables faster training with multiple GPU resources | - TensorFlow - PyTorch - Apache MXNet - XGBoost - Message passing interface (MPI) |
For details on Training Operators, refer to the Kubeflow > Training Operators documentation.
Before you start
1. Prepare training data
This tutorial uses the Fashion MNIST dataset, a benchmark dataset commonly used for testing computer vision algorithms.
Unlike MNIST, Fashion MNIST consists of small grayscale images categorized into clothing types such as sneakers, shirts, and sandals.
The dataset contains 70,000 images (28×28 pixels) across 10 categories and will be downloaded automatically during the exercise.

Fashion MNIST dataset
2. Set up Kubeflow environment
Before using Training Operator in Kubeflow, confirm that appropriate MIG settings and node pool specifications are configured.
If Kubeflow is not yet set up, refer to Set up Jupyter Notebook using Kubeflow to create a Kubeflow environment with a GPU node pool and launch a CPU image-based notebook.
Minimum requirements
- Node pool: At least
4 vCPUs,8 GB memory - MIG configuration: Minimum of three
1g.10gbinstances - GPU pipeline node pool: Must be configured
Getting started
Follow the steps below to implement a parallel training model using Kubeflow.
Step 1. Create TrainingJob for Fashion MNIST classification model
Create a TrainingJob using Kubeflow’s Training Operator to train a classification model based on the Fashion MNIST dataset.
-
Download the exercise file:
fashionmnist_pytorch_parallel_train_with_tj.ipynb -
Access the notebook instance you created and upload the file using the browser interface.
-
Once uploaded, the exercise content will be displayed in the notebook view.
-
Review the example and proceed with training the model.
Step 2. Check TrainingJob status on the dashboard
The Kubeflow dashboard provides a UI to check the specs, logs, and events of a TrainingJob.
-
Open the Kubeflow dashboard and go to the TrainingJob tab.
-
In the list, click
parallel-train-pytorch.
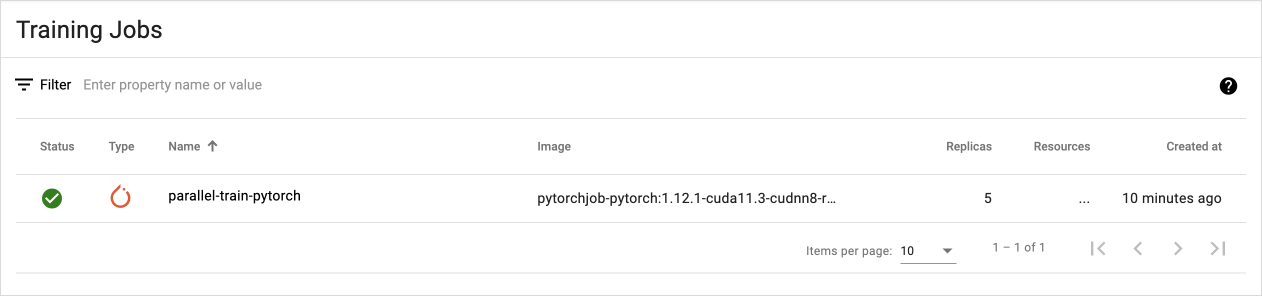
TrainingJob tab
- View the detailed status of the TrainingJob created in Step 1.
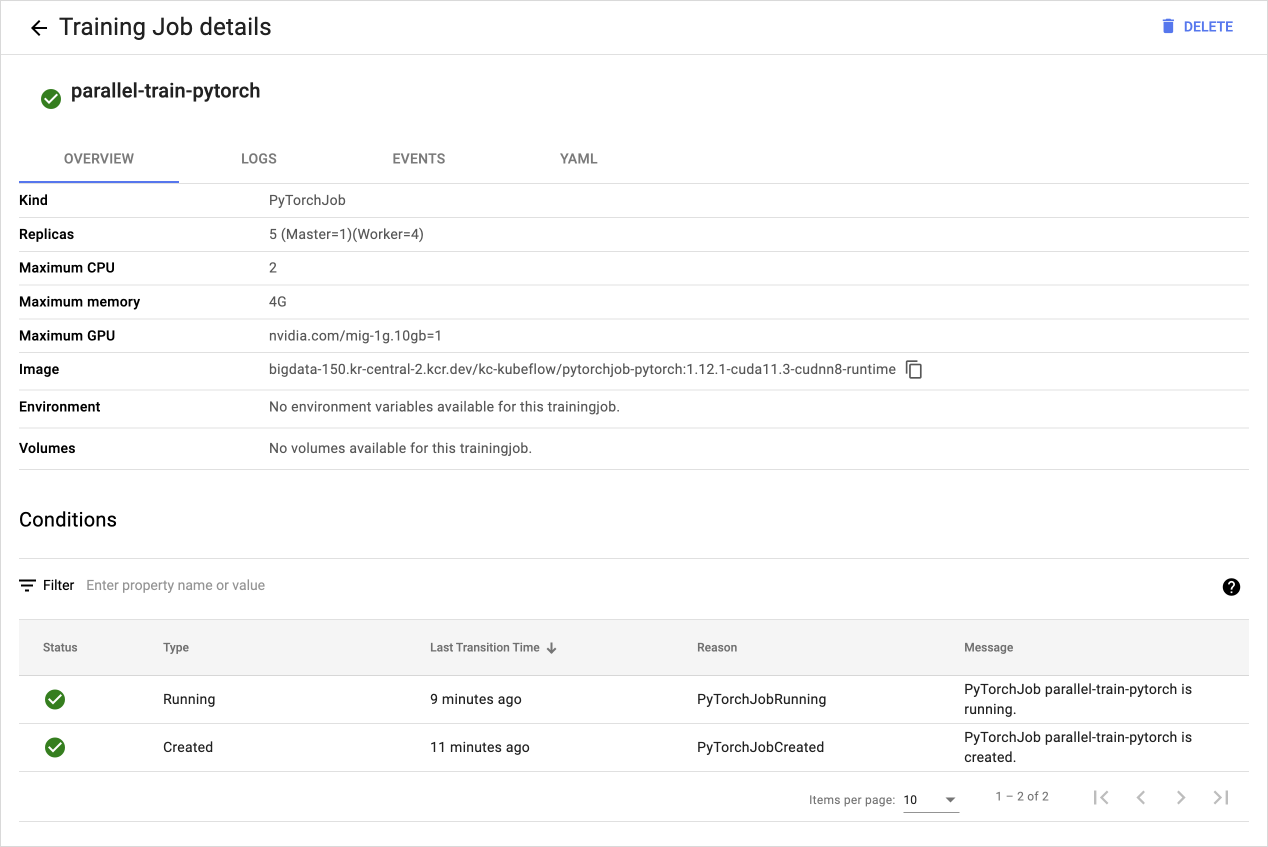
TrainingJob details
Step 3. Check MIG instance status
You can check the usage status of MIG instances via the KakaoCloud console.
This allows you to monitor GPU resource allocation and usage during parallel training and evaluate resource efficiency.
-
Go to the KakaoCloud console and select the Kubeflow menu.
-
Select the Kubeflow project you want to inspect.
-
In the GPU status tab, view the current usage of MIG instances used during the exercise.
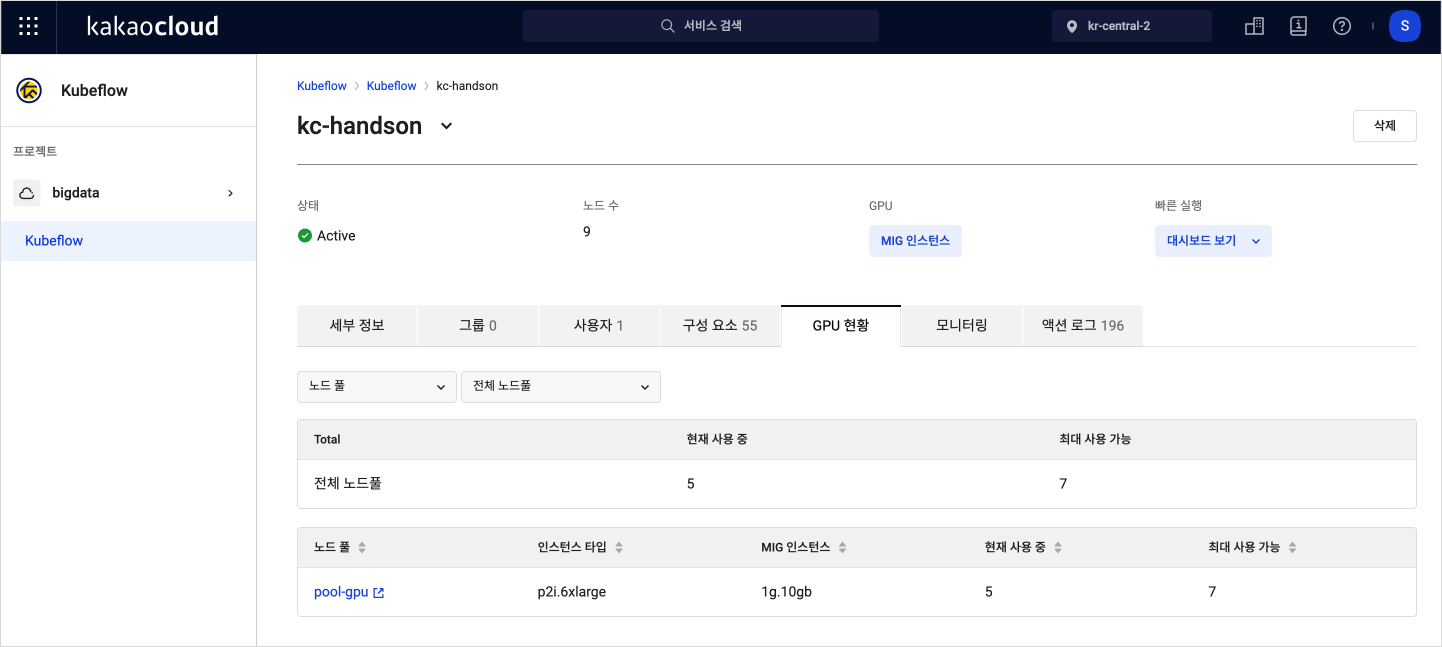
GPU status tab