3. Create model serving API
📈 This section explains how to create a model serving API as part of the traffic prediction model tutorial.
- Estimated time: 30 minutes
- Recommended OS: MacOS, Ubuntu
About this scenario
KServe is a serverless model inference (serving) project based on Kubernetes. It provides a standardized serving interface for various machine learning frameworks such as TensorFlow, PyTorch, Scikit-learn, and XGBoost.
In this tutorial, you will perform the process of serving a machine learning model using KServe. It explains how to create an InferenceService in the cluster and deploy the model using Python integrated with Model Registry.
Getting started
⚠️ This tutorial assumes that you have completed the previous traffic prediction tutorials (Parts 1 and 2).
Deploy model with KServe
KServe uses a custom resource called InferenceService to deploy models.
-
The example below shows a configuration for deploying a model using the Scikit-learn framework. Use it as a reference to create the
lb-isvc.yamlfile.Create InferenceService (lb-isvc.yaml)apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: lb-predictor
spec:
predictor:
model:
modelFormat:
name: sklearn
runtime: kserve-sklearnserver
args:
- '--model_name=lb-predictor'
storageUri: "pvc://model-pvc/lb-predictor"Field description
Field Description nameSpecifies the model service name (e.g., lb-predictor)modelFormatSpecifies the model framework format to use (e.g., sklearn)runtimeSpecifies the runtime name for model serving (e.g., kserve-sklearnserver)storageUriSpecifies the path to the model stored in the PVC (e.g., pvc://model-pvc/lb-predictor)For frameworks other than Scikit-learn, refer to the official documentation.
-
Access the Kubeflow dashboard and select the Endpoint menu on the left.
-
Click [+ New Endpoint] and paste the contents of the infsvc.yaml file above.
-
Check the deployment result. (This may take a few minutes depending on the environment)
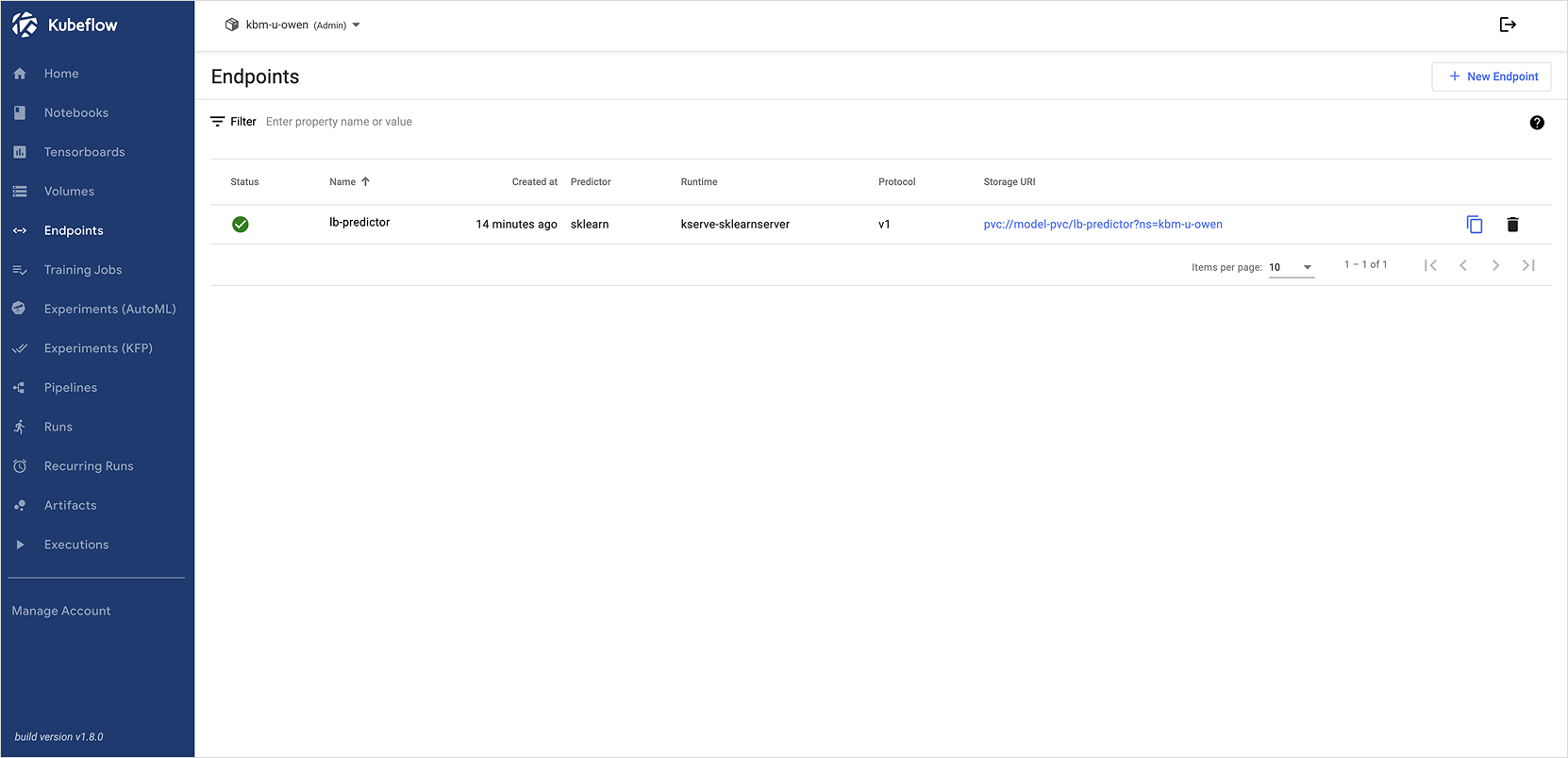
-
You can perform inference from the notebook terminal using the following command:
Inference commandcurl -X POST http://{ISVC_NAME}.{NAMESPACE}.svc.cluster.local/v1/models/{MODEL_NAME}:predict \
-H "Content-Type: application/json" \
-d '{"instances": [[0.1, 0.1, 0.1, 0.1]]}' # input dataISVC_NAME: Name of the created InferenceService (e.g.,lb-predictor)NAMESPACE: Your namespaceMODEL_NAME: Model name passed as argument (e.g.,lb-predictor)
-
When the command is executed, you will see output similar to the following:
Output{"predictions":[46.52174265571983]}The above URL is only accessible from inside the cluster. To access it externally, refer to the KServe documentation.
Deploy model with Model Registry
Model Registry is a component of Kubeflow that helps centrally manage versions, artifacts, and metadata of machine learning models. With its integration with KServe, it allows you to register and manage models easily and deploy them with minimal effort.
The example below shows the full process of deploying a model registered in the Model Registry with KServe.
-
Run the following command in the notebook to install the required packages for Model Registry and KServe:
Install required libraries!pip install model-registry==0.2.7a1 kserve==0.13.1 --quiet -
Import the modules and create a Model Registry client. Replace [USER_NAME] with your username.
Client setupfrom model_registry import ModelRegistry
registry = ModelRegistry(
server_address="http://model-registry-service.kubeflow.svc.cluster.local",
port=8080,
author="[USER_NAME]",
is_secure=False
) -
Register the model file saved in the PVC path to the registry. Provide the model name, version, and format at registration.
Register modelmodel_name = "lb-predictor"
model_path = f"pvc://model-pvc/lb-predictor/model.joblib" # use PVC path
model_version = "1.0.0"
rm = registry.register_model(
model_name,
model_path,
model_format_name="joblib",
model_format_version="1",
version=model_version,
metadata= {"metadata": "test"}
) -
Based on the registered model information, create a KServe
InferenceService.KServe deploymentfrom kubernetes import client
import kserve
model = registry.get_registered_model(model_name)
print("Registered Model:", model, "with ID", model.id)
version = registry.get_model_version(model_name, model_version)
print("Model Version:", version, "with ID", version.id)
art = registry.get_model_artifact(model_name, model_version)
print("Model Artifact:", art, "with ID", art.id)
isvc = kserve.V1beta1InferenceService(
api_version=kserve.constants.KSERVE_GROUP + "/v1beta1",
kind=kserve.constants.KSERVE_KIND,
metadata=client.V1ObjectMeta(
name=model_name,
labels={
"modelregistry/registered-model-id": model.id,
"modelregistry/model-version-id": version.id,
},
),
spec=kserve.V1beta1InferenceServiceSpec(
predictor=kserve.V1beta1PredictorSpec(
sklearn=kserve.V1beta1SKLearnSpec(
args=['--model_name=lb-predictor'],
storage_uri=art.uri
)
)
),
)
ks_client = kserve.KServeClient()
ks_client.create(isvc) -
After deployment is complete, you can test inference inside the cluster with the following commands:
Inference testimport requests
import json
isvc_name = "lb-predictor" # name of the InferenceService
model_name = "lb-predictor" # model name
namespace = "{NAMESPACE}" # your namespace (e.g., kbm-u-XX)
url = f"http://{isvc_name}.{namespace}.svc.cluster.local/v1/models/{model_name}:predict"
# request payload (input)
payload = {
"instances": [[0.1, 0.1, 0.1, 0.1]]
}
# HTTP request headers
headers = {
"Content-Type": "application/json"
}
# send POST request
response = requests.post(url, data=json.dumps(payload), headers=headers)
# print response
print("Status Code:", response.status_code)
print("Response:", response.json())OutputStatus Code: 200
Response: {'predictions': [65.98312040830406]}