컴포넌트 목록
Hadoop Eco 서비스에서 클러스터에 설치된 컴포넌트를 사용하는 방법은 다음과 같습니다.
Hive
Hive CLI를 실행한 후, 쿼리를 입력합니다.
hive
hive (default)> CREATE TABLE tbl (
> col1 STRING
> ) STORED AS ORC
> TBLPROPERTIES ("orc.compress"="SNAPPY");
OK
Time taken: 1.886 seconds
Hive - Zeppelin 연동하기
-
Zeppelin이 설치된 마스터 노드에 퍼블릭 IP를 부착한 후 Zeppelin UI에 접속합니다.
Zeppelin 접근 방법은 Zeppelin을 참고하시기 바랍니다. -
Zeppelin에서 Hive 실행 방법
- 상단의 메뉴에서 Notebook > Create new note를 클릭하여 나타나는 팝업에서 hive Interpreter를 선택합니다.
- Zeppelin notebook에 아래와 같이 입력하여 실행할 수 있습니다.
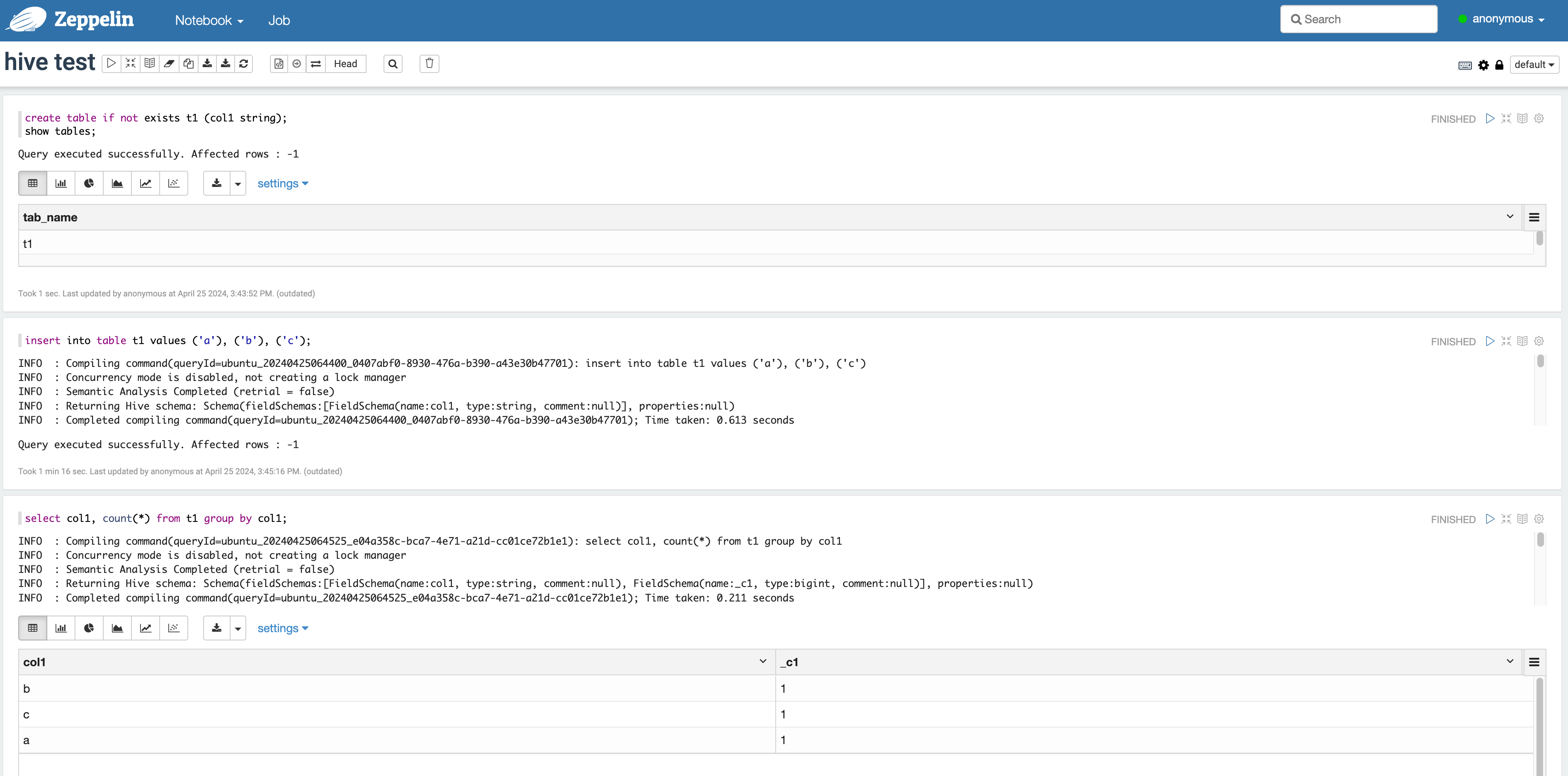 Trino-Zeppelin 쿼리 결과 확인
Trino-Zeppelin 쿼리 결과 확인
Beeline
-
Beeline CLI를 실행합니다.
-
HiveServer2에 직접 접근과 Zookeeper를 이용한 접근 중 선택하여 HiveServer2에 접속합니다.
- HiveServer2에 직접 접근
- Zookeeper를 이용한 접근
!connect jdbc:hive2://[서버명]:10000/default;!connect jdbc:hive2://[마스터 1]:2181,[마스터 2]:2181,[마스터3]:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kepbp_hiveserver2 -
쿼리를 입력합니다.
-
쿼리를 실행하기 전 접근 사용자명을 정확하게 입력하여야 합니다. Hadoop Eco의 기본 사용자는 Ubuntu입니다.
-
HDFS에 접근할 수 없는 사용자로 실행한 경우, 쿼리 실행 시 오류가 발생할 수 있습니다.
Beeline CLI를 이용한 쿼리 실행######################################
# hiveserver2 직접 접근
######################################
beeline> !connect jdbc:hive2://10.182.50.137:10000/default;
Connecting to jdbc:hive2://10.182.50.137:10000/default;
Enter username for jdbc:hive2://10.182.50.137:10000/default:
Enter password for jdbc:hive2://10.182.50.137:10000/default:
Connected to: Apache Hive (version 2.3.2)
Driver: Hive JDBC (version 2.3.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://10.182.50.137:10000/default> show databases;
+----------------+
| database_name |
+----------------+
| db_1 |
| default |
+----------------+
2 rows selected (0.198 seconds)
#####################################
# 주키퍼를 이용한 접근
#####################################
beeline> !connect jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kepbp_hiveserver2
Connecting to jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kepbp_hiveserver2
Enter username for jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/:
Enter password for jdbc:hive2://hadoopmst-hadoop-ha-1:2181,hadoopmst-hadoop-ha-2:2181,hadoopmst-hadoop-ha-3:2181/:
22/09/06 05:40:52 [main]: INFO jdbc.HiveConnection: Connected to hadoopmst-hadoop-ha-1:10000
Connected to: Apache Hive (version 2.3.9)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoopmst-hadoop-ha-1:2181,ha> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (2.164 seconds)
0: jdbc:hive2://hadoopmst-hadoop-ha-1:2181,ha>
#####################################
# 사용자 입력 (Enter username: )
#####################################
beeline> !connect jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default;
Connecting to jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default;
Enter username for jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default: ubuntu
Enter password for jdbc:hive2://bigdata-hadoop-master-1.kep.k9d.in:10000/default:
Connected to: Apache Hive (version 2.3.9)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://bigdata-hadoop-master-1.kep.k> create table t2 (`value` string,`product_num` int) partitioned by (manufacture_date string) STORED AS ORC;
No rows affected (0.527 seconds)
0: jdbc:hive2://bigdata-hadoop-master-1.kep.k> insert into t2 partition(manufacture_date='2019-01-01') values('asdf', '123');
No rows affected (26.56 seconds)
0: jdbc:hive2://bigdata-hadoop-master-1.kep.k>
-
Hue
Hue는 Hadoop Eco 클러스터에 제공되는 사용자 인터페이스입니다.
클러스터 상세 페이지에서 퀵 링크를 클릭하여 접속합니다. 클러스터 생성 시점에 입력한 관리자 정보로 로그인합니다.
Hue는 Hive 편집기와 브라우저를 이용할 수 있습니다.
- 브라우저 종류: 파일 브라우저, 테이블 브라우저, 잡 브라우저
클러스터 유형별 Hue 접속 포트
| 클러스터 가용성 | 접속 포트 |
|---|---|
| 표준(Single) | 마스터 1번 노드의 8888 포트 |
| HA | 마스터 3번 노드의 8888 포트 |
 Hue 사용자 로그인
Hue 사용자 로그인
Impala
Impala는 대규모 데이터 분석을 위한 MPP(대규모 병렬 처리) SQL 쿼리 엔진으로 HDFS, Apache Kudu, 오브젝트 스토리지 등 다양한 데이터 소스에 저장된 데이터를 빠르고 효율적으로 쿼리할 수 있도록 설계되었습니다.
Impala 컴포넌트
| 구분 | 설명 | 포트 |
|---|---|---|
| Impala Statestore(StateStored) | 클러스터의 각 데이터 노드에서 수행되는 Impalad의 상태를 관리하며, Catalogd에서 요청받은 Impalad에 대한 메타데이터 동기화 작업을 수행합니다. | 25010 |
| Impala Catalogd | 쿼리 작업 시 이를 Impalad의 메타데이터에 반영하기 위해 StateStored에 브로드캐스팅을 요청하는 역할을 담당합니다. | 25020 |
| Impala Admissiond | Impala 클러스터 내에서 동시에 실행되는 쿼리의 수와 리소스 사용량을 관리하여 시스템 과부하를 방지하고 쿼리 실행의 안정성을 보장합니다. | 25030 |
| Impala Impalad | Hadoop 클러스터 내 데이터 노드에 설치되어 요청받은 쿼리에 대한 계획, 스케줄링, 실행 엔진을 관리하는 역할을 수행합니다. | 25000 |
Impala 실행
# statestored
sudo systemctl start impala-statestored.service
/opt/impala/bin/impala.sh start statestored
# catalogd
sudo systemctl start impala-catalogd.service
/opt/impala/bin/impala.sh start catalogd
# admissiond
sudo systemctl start impala-admissiond.service
/opt/impala/bin/impala.sh start admissiond
# impalad
sudo systemctl start impala-impalad.service
/opt/impala/bin/impala.sh start impalad
Impala CLI
-- table 생성
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 8
STORED AS KUDU
TBLPROPERTIES (
'kudu.num_tablet_replicas' = '1'
);
-- 데이터 입력
INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");
-- 조회
SELECT id, count(*)
FROM my_first_table
GROUP BY id
;
Query: SELECT id, count(*)
FROM my_first_table
GROUP BY id
Query submitted at: 2025-08-20 08:49:44 (Coordinator: http://host-10-0-1-5:25000)
Query state can be monitored at: http://host-10-0-1-5:25000/query_plan?query_id=e2426e102602a7d8:36a55eac00000000
+----+----------+
| id | count(*) |
+----+----------+
| 3 | 1 |
| 2 | 1 |
| 1 | 1 |
+----+----------+
Fetched 3 row(s) in 0.44s
JupyterLab
JupyterLab은 확장성이 뛰어나고, 다양한 기능을 제공하는 노트북 제작 애플리케이션 편집 환경입니다. JupyterLab을 설치한 후 8880 포트로 접근합니다.
JupyterLab - Object Storage 연결
{
"classification": "jupyterlab-env",
"properties": {
"jupyterlab.s3.endpoint": "https://objectstorage.kr-central-2.kakaocloud.com",
"jupyterlab.s3.access.key.id": "xxx",
"jupyterlab.s3.secret.access.key": "yyy"
}
}
Kudu
Kudu 는 실시간 데이터 분석과 빠른 데이터 변경을 위한 칼럼 기반의 고성능 스토리지입니다.
Kudu 컴포넌트
| 구분 | 설명 | 포트 |
|---|---|---|
| 마스터 서버 | 마스터는 메타데이터를 관리하며 신규 서버 등록·장애 복구·리더 선출을 통해 클라이언트 요청을 조정합니다. | kudu-master(web server): 8051 kudu-master(rpc): 7051 |
| 태블릿 서버 | 태블릿 서버는 분할된 태블릿을 저장하고 읽기/쓰기를 처리하며, 각 태블릿의 복제본은 Raft로 Leader–Follower 구조를 유지해 일관성을 보장합니다. | kudu-tserver(web server): 8050 kudu-tserver(rpc): 7050 |
Kudu 실행
# 마스터 실행
## hde
sudo systemctl start kudu-master.service
## cli 실행
/opt/kudu/bin/kudu-master --flagfile=/etc/kudu/conf/kudu-master.conf
# 태블릿 서버 실행
## hde
sudo systemctl start kudu-tserver.service
## cli 실행
/opt/kudu/bin/kudu-tserver --flagfile=/etc/kudu/conf/kudu-tserver.conf
Kudu CLI
클러스터 상태 확인
$ kudu cluster ksck host-10-0-1-5
Master Summary
UUID | Address | Status
----------------------------------+---------------+---------
19402cdb3e934180a8965bb21c34d3fc | host-10-0-1-5 | HEALTHY
Flags of checked categories for Master:
Flag | Value | Master
---------------------+-------------------------------------------------------------+-------------------------
builtin_ntp_servers | 0.pool.ntp.org,1.pool.ntp.org,2.pool.ntp.org,3.pool.ntp.org | all 1 server(s) checked
time_source | system | all 1 server(s) checked
Tablet Server Summary
UUID | Address | Status | Location | Tablet Leaders | Active Scanners
----------------------------------+----------------------+---------+----------+----------------+-----------------
2b61ad307a0a4a2dae14115a479f20bf | host-10-0-3-213:7050 | HEALTHY | <none> | 0 | 0
Tablet Server Location Summary
Location | Count
----------+---------
<none> | 1
Flags of checked categories for Tablet Server:
Flag | Value | Tablet Server
---------------------+-------------------------------------------------------------+-------------------------
builtin_ntp_servers | 0.pool.ntp.org,1.pool.ntp.org,2.pool.ntp.org,3.pool.ntp.org | all 1 server(s) checked
time_source | system | all 1 server(s) checked
Version Summary
Version | Servers
---------+-------------------------
1.17.1 | all 2 server(s) checked
The cluster doesn't have any matching tablets
The cluster doesn't have any matching system tables
The cluster doesn't have any matching tables
Tablet Replica Count Summary
Statistic | Replica Count
----------------+---------------
Minimum | 0
First Quartile | 0
Median | 0
Third Quartile | 0
Maximum | 0
OK
파일 시스템 확인
$ kudu fs list -fs_wal_dir /opt/kudu/wal -fs_data_dirs /opt/kudu/data
I20250820 04:15:47.838682 29708 fs_manager.cc:337] Metadata directory not provided
I20250820 04:15:47.838729 29708 fs_manager.cc:343] Using write-ahead log directory (fs_wal_dir) as metadata directory
W20250820 04:15:47.838948 29708 dir_manager.cc:457] IO error: Could not lock instance file. Make sure that Kudu is not already running and you are not trying to run Kudu with a different user than before: lock /opt/kudu-1.17.1-bin/data/data/block_manager_instance: Resource temporarily unavailable (error 11)
W20250820 04:15:47.838963 29708 dir_manager.cc:458] Proceeding without lock
I20250820 04:15:47.839223 29708 fs_manager.cc:525] Time spent opening directory manager: real 0.000s user 0.001s sys 0.001s
I20250820 04:15:47.840155 29718 log_block_manager.cc:3016] Read-only block manager, skipping repair
I20250820 04:15:47.840261 29708 fs_report.cc:352] FS layout report
--------------------
wal directory:
metadata directory:
1 data directories: /opt/kudu-1.17.1-bin/data/data
Total live blocks: 5
Total live bytes: 7955
Total live bytes (after alignment): 24576
Total number of LBM containers: 7 (0 full)
Did not check for missing blocks
Did not check for orphaned blocks
Total full LBM containers with extra space: 0 (0 repaired)
Total full LBM container extra space in bytes: 0 (0 repaired)
Total incomplete LBM containers: 0 (0 repaired)
Total LBM partial records: 0 (0 repaired)
I20250820 04:15:47.840302 29708 fs_manager.cc:551] Time spent opening block manager: real 0.001s user 0.000s sys 0.000s
I20250820 04:15:47.840314 29708 fs_manager.cc:579] Opened local filesystem: /opt/kudu-1.17.1-bin/data,/opt/kudu-1.17.1-bin/wal
uuid: "19402cdb3e934180a8965bb21c34d3fc"
format_stamp: "Formatted at 2025-08-20 01:58:17 on host-10-0-1-5"
tablet-id | rowset-id | block-id | block-kind
----------------------------------+-----------+----------+-------------
00000000000000000000000000000000 | 0 | 2 | column
00000000000000000000000000000000 | 0 | 3 | column
00000000000000000000000000000000 | 0 | 4 | column
00000000000000000000000000000000 | 0 | 5 | bloom
00000000000000000000000000000000 | 0 | 6 | adhoc-index
Kudu - Hive 연동
- kudu table create(테이블 생성)
- kudu hms list(테이블 목록 확인)
$ kudu table create host-10-0-1-5 '{ "table_name": "default.test", "schema": { "columns": [ { "column_name": "id", "column_type": "INT32", "default_value": "1" }, { "column_name": "key", "column_type": "INT64", "is_nullable": false, "comment": "range partition column" }, { "column_name": "name", "column_type": "STRING", "is_nullable": false, "comment": "user name" } ], "key_column_names": ["id", "key"] }, "partition": { "hash_partitions": [{"columns": ["id"], "num_buckets": 2, "seed": 8}], "range_partition": { "columns": ["key"], "range_bounds": [ { "lower_bound": {"bound_type": "inclusive", "bound_values": ["2"]}, "upper_bound": {"bound_type": "exclusive", "bound_values": ["3"]} }, { "lower_bound": {"bound_type": "inclusive", "bound_values": ["3"]} } ] } }, "extra_configs": { "configs": { "kudu.table.history_max_age_sec": "3600" } }, "comment": "a test table", "num_replicas": 1 }'
$ kudu hms list host-10-0-1-5
database | table | type | kudu.table_name
----------+-------+---------------+-----------------
default | test | MANAGED_TABLE | default.test
Oozie
Oozie는 Hadoop Eco 클러스터의 유형이 Core Hadoop일 때 제공되는 워크플로(Workflow) 작업 도구입니다.
클러스터 유형별 Oozie 접속 포트
| 클러스터 가용성 | 접속 포트 |
|---|---|
| 표준(Single) | 마스터 1번 노드의 11000 포트 |
| HA | 마스터 3번 노드의 11000 포트 |
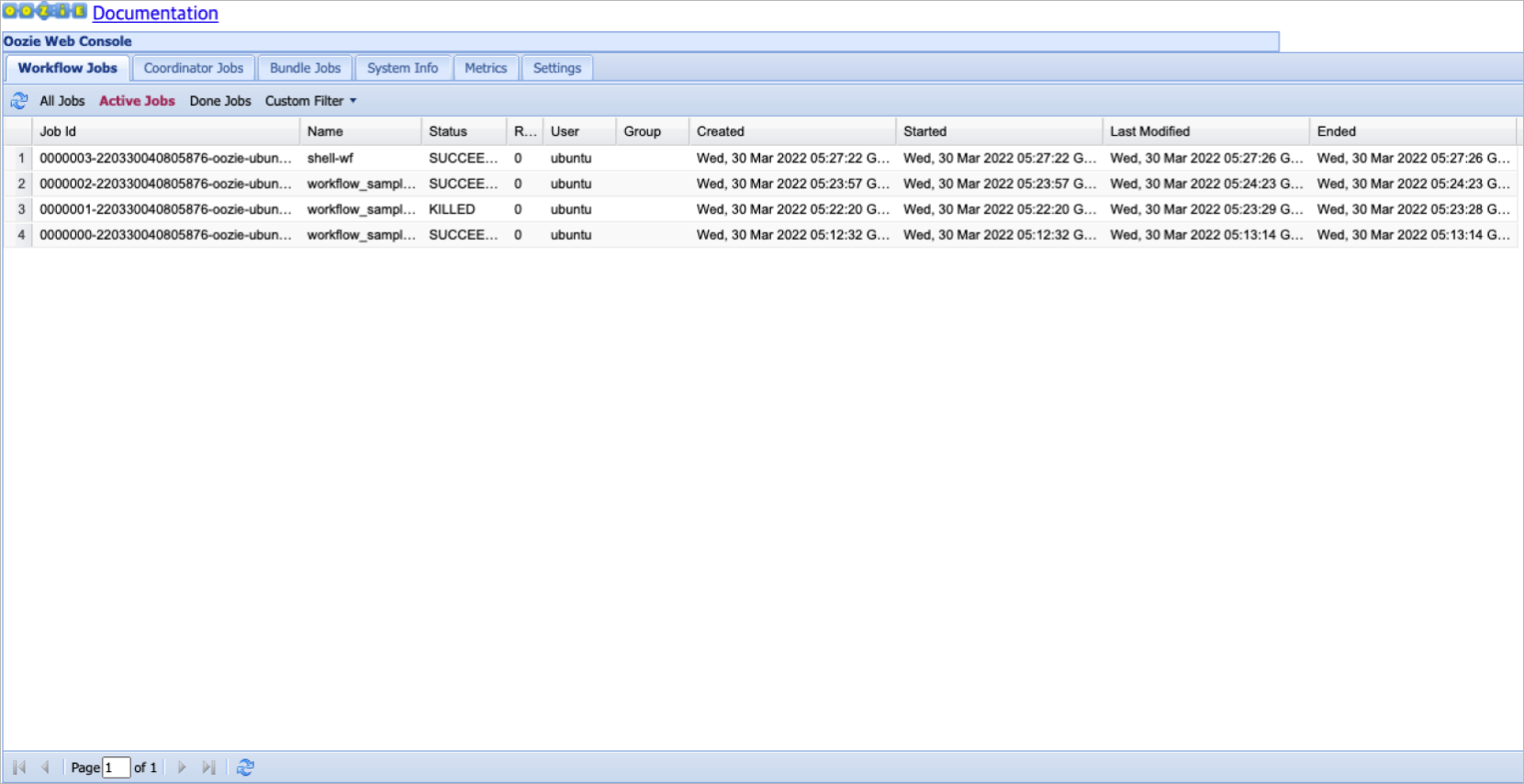 Oozie 워크플로 목록
Oozie 워크플로 목록
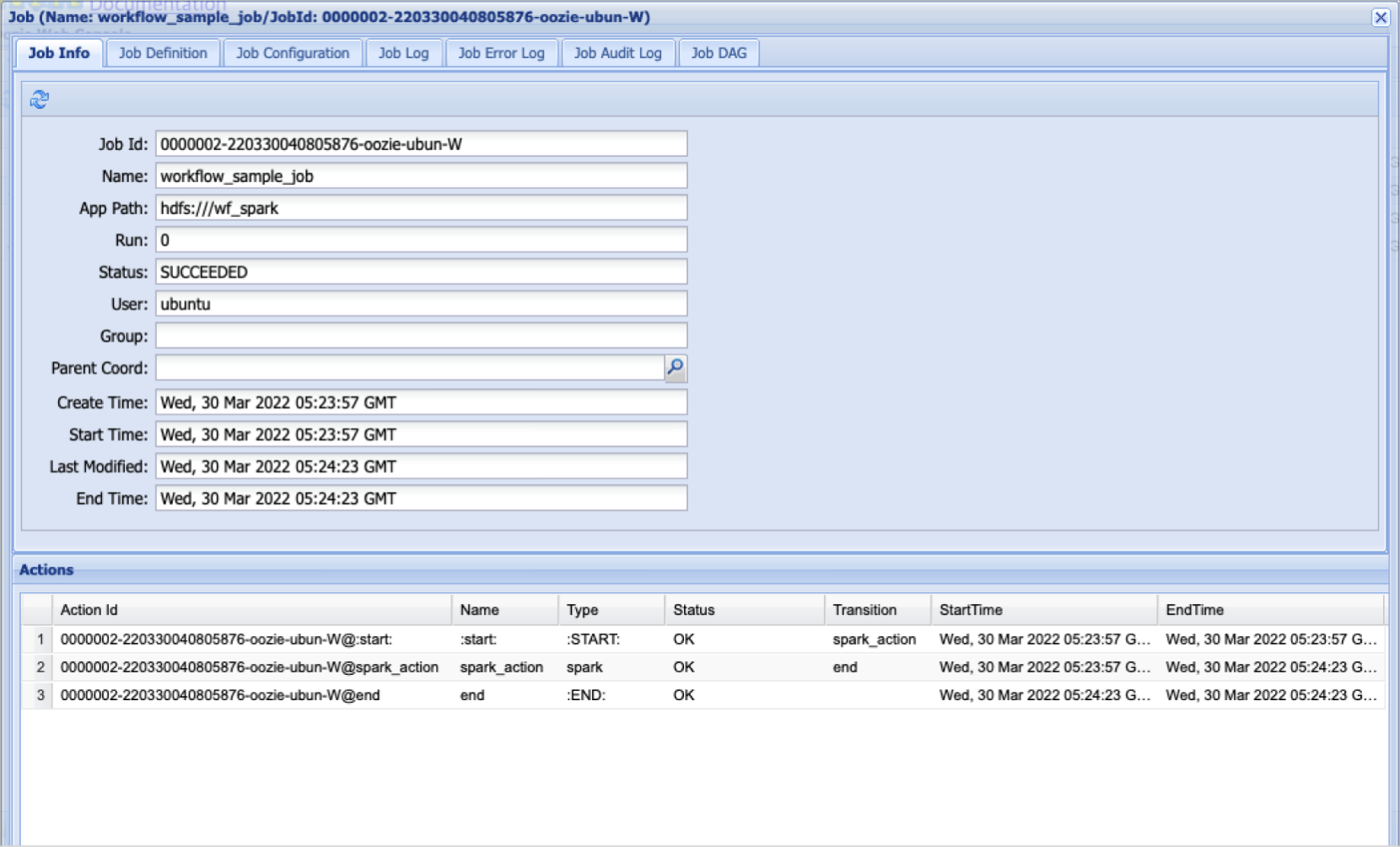 Oozie 워크플로 작업 정보
Oozie 워크플로 작업 정보
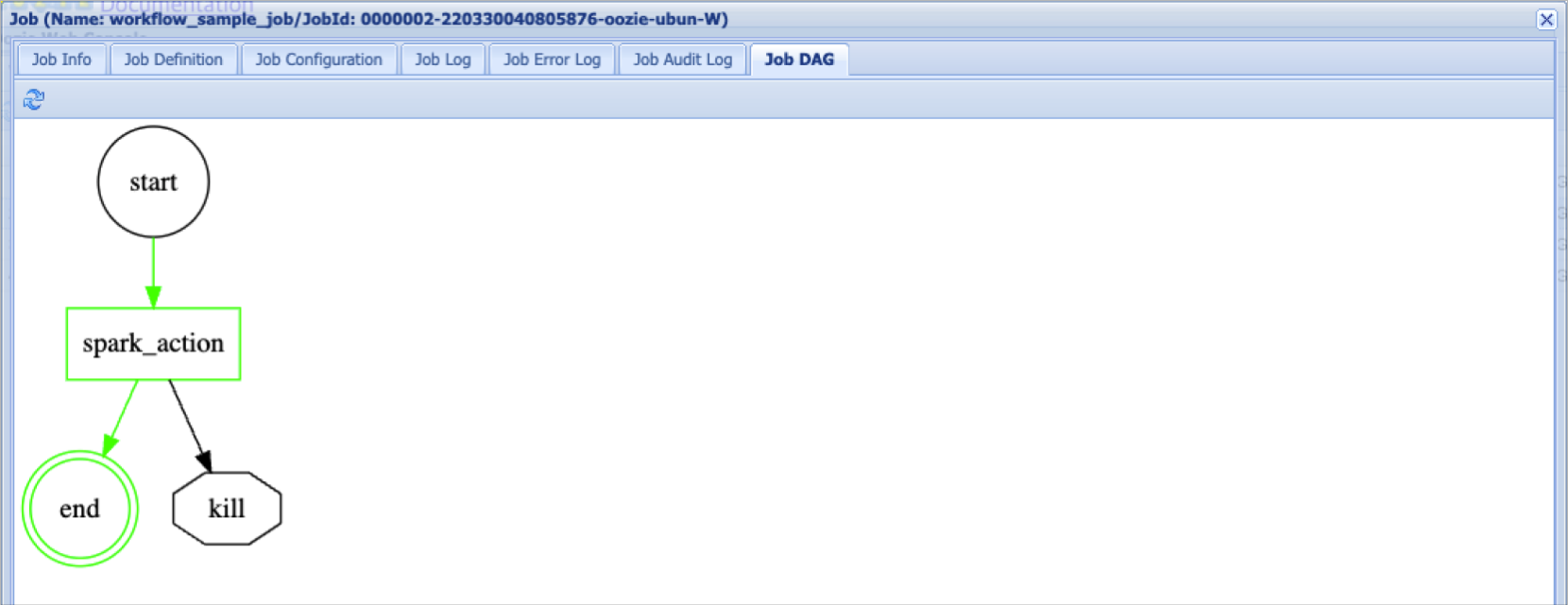 Oozie 워크플로 작업 내용
Oozie 워크플로 작업 내용
Zeppelin
Zeppelin은 Hadoop Eco 클러스터 유형이 Core Hadoop, Trino 일 때 제공되는 사용자 인터페이스입니다.
클러스터 상세 페이지에서 퀵 링크를 클릭하여 Zeppelin에 접속합니다.
클러스터 고가용성에 따른 Zeppelin 접속 포트
| 클러스터 고가용성 | 접속 포트 |
|---|---|
| 표준(Single) | 마스터 1번 노드의 8180 포트 |
| HA | 마스터 3번 노드의 8180 포트 |
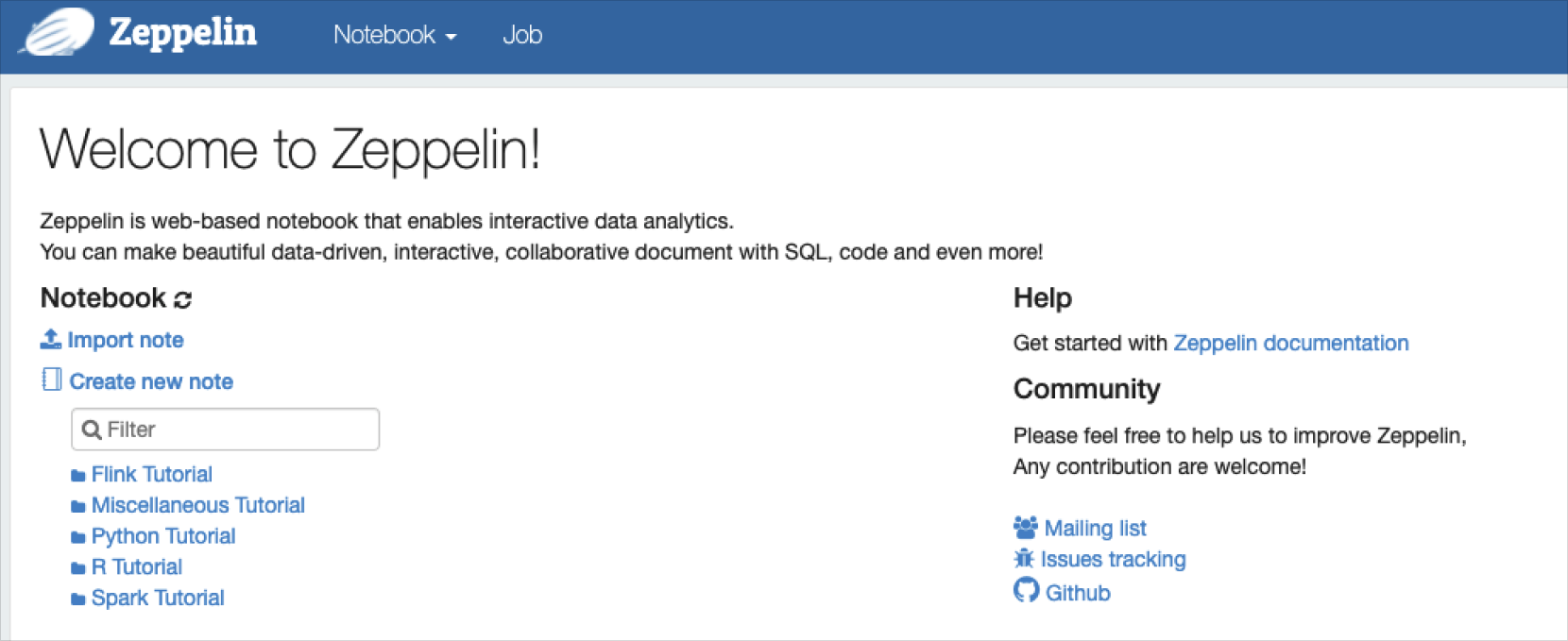 Zeppelin 사용자 인터페이스
Zeppelin 사용자 인터페이스
인터프리터
인터프리터는 프로그래밍 언어 소스 코드를 바로 실행하는 환경을 의미합니다.
Zeppelin은 Spark, Hive, Trino 인터프리터를 제공합니다.
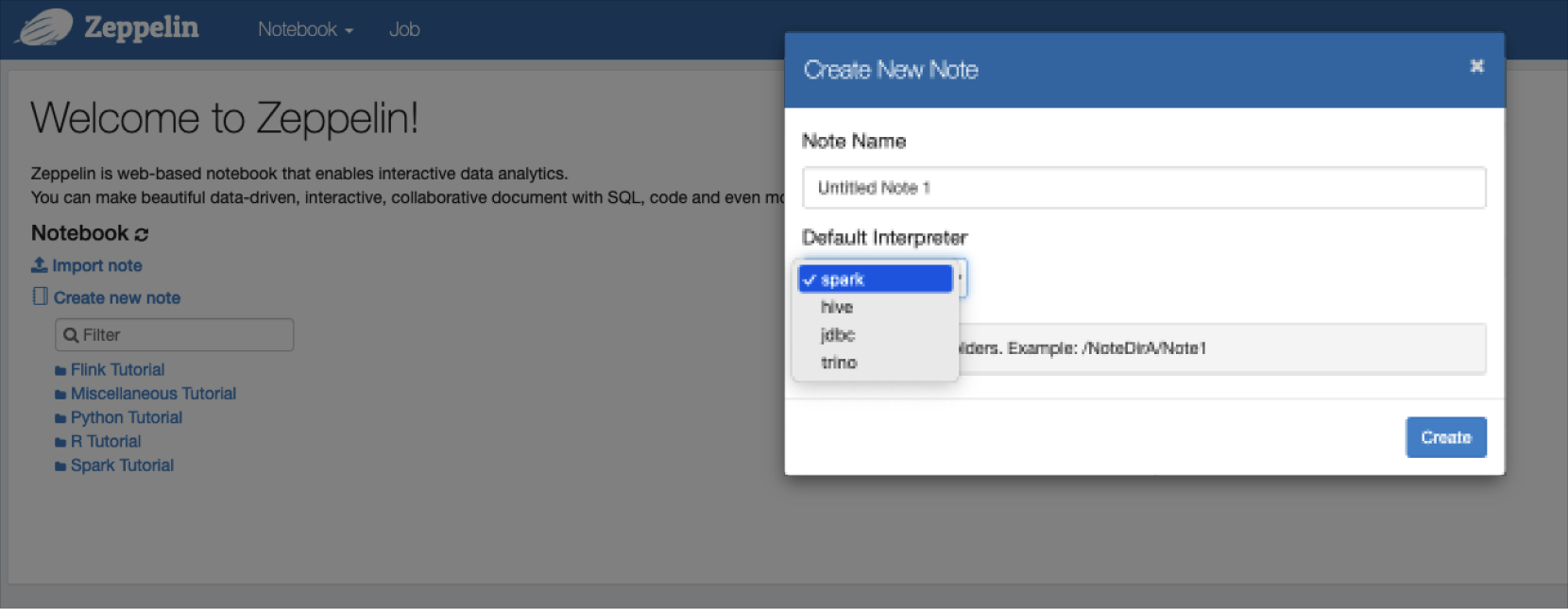 Zeppelin 사용
Zeppelin 사용
Spark
-
마스터 노드에서 spark-shell CLI를 실행한 후 테스트 코드를 입력합니다.
spark-shell CLI를 이용한 쿼리 실행Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.2
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val count = sc.parallelize(1 to 90000000).filter { _ =>
| val x = math.random
| val y = math.random
| x*x + y*y < 1
| }.count()
count: Long = 70691442 -
마스터 노드에서 spark-submit 명령어로 Spark 예제 파일을 실행합니다.
$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/spark/examples/jars/spark-examples_*.jar 100
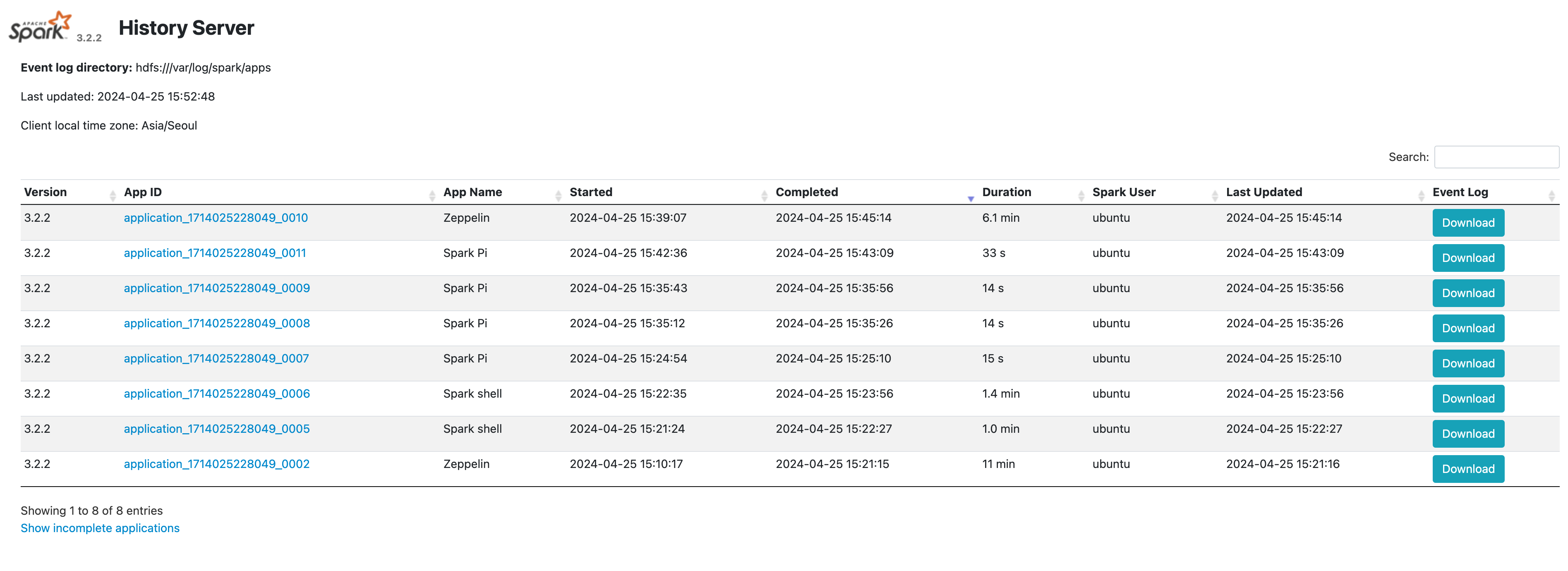
Spark History Server 접속하기
-
클러스터의 고가용성에 따라 마스터 노드에 퍼블릭 IP를 부착한 후 spark history server에 접근할 수 있습니다.
클러스터 고가용성 접속 포트 표준(Single) 마스터 1번 노드의 18082 포트 HA 마스터 3번 노드의 18082 포트 -
History Server에서 정보를 확인합니다.
Spark - Zeppelin 연동하기
-
Zeppelin이 설치된 마스터 노드에 퍼블릭 IP를 부착한 후 Zeppelin UI에 접속합니다.
Zeppelin 접근 방법은 Zeppelin을 참고하시기 바랍니다. -
Zeppelin에서 spark-shell 실행 방법
- 상단의 메뉴에서 Notebook > Create new note를 클릭하여 나타나는 팝업에서 spark Interpreter를 선택합니다.
- Zeppelin notebook에 아래와 같이 입력하여 실행할 수 있습니다.
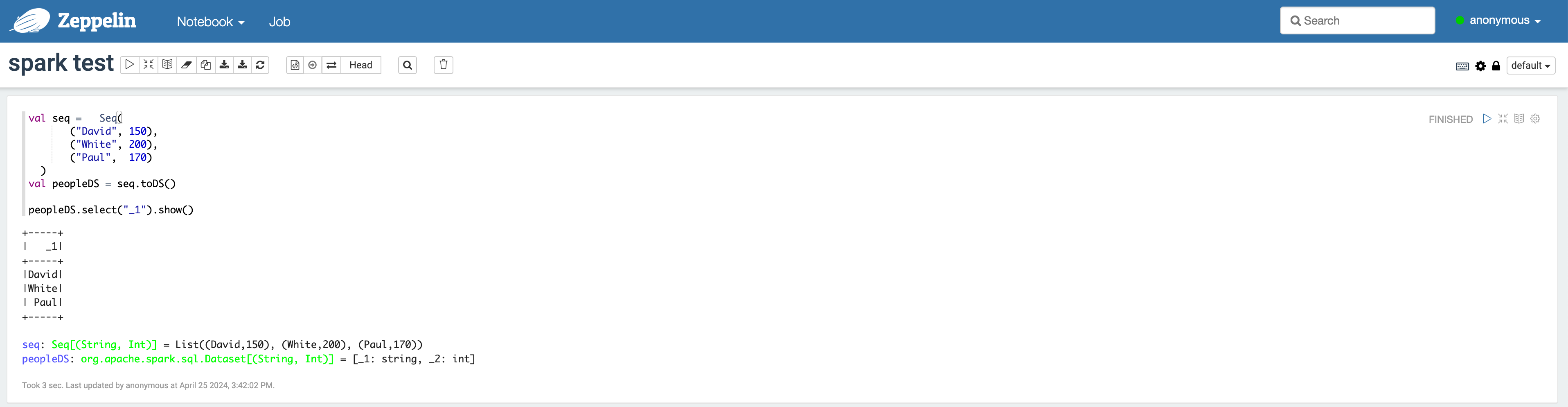 Trino-Zeppelin 쿼리 결과 확인
Trino-Zeppelin 쿼리 결과 확인 -
Zeppelin에서 pyspark 실행 방법
- 상단의 메뉴에서 Notebook > Create new note를 클릭하여 나타나는 팝업에서 spark Interpreter를 선택합니다.
- Zeppelin notebook에 다음과 같이 입력하여 실행할 수 있습니다.
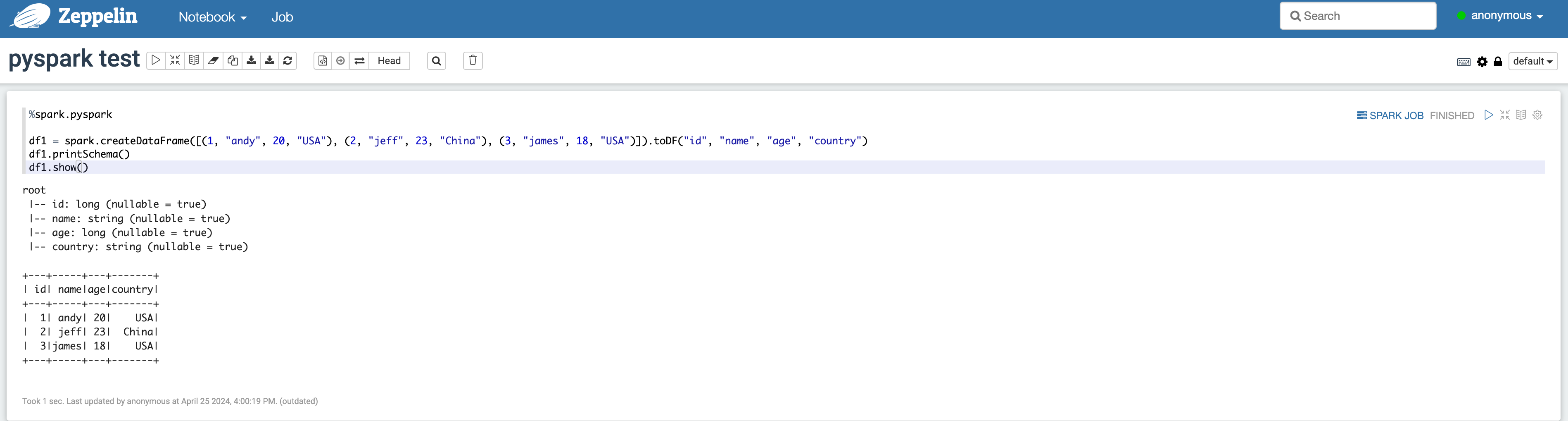 Trino-Zeppelin 쿼리 결과 확인
Trino-Zeppelin 쿼리 결과 확인 -
Zeppelin에서 Spark-submit 실행 방법
- 상단의 메뉴에서 Notebook > Create new note를 클릭하여 나타나는 팝업에서 spark Interpreter를 선택합니다.
- Zeppelin notebook에 다음과 같이 입력하여 실행할 수 있습니다.
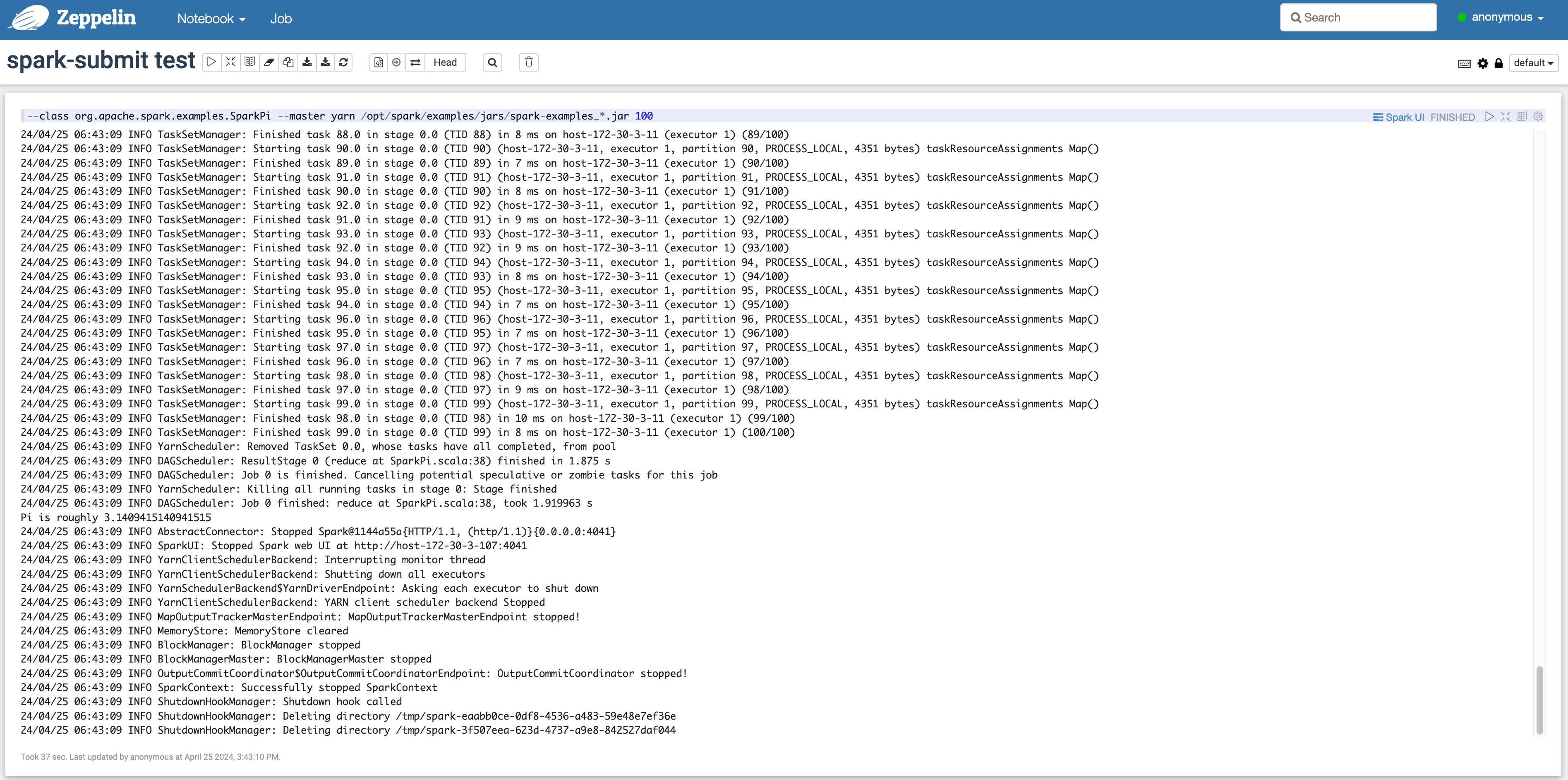 Trino-Zeppelin 쿼리 결과 확인
Trino-Zeppelin 쿼리 결과 확인
Tez
Tez는 Yarn 기반으로 Hive에서 MR 엔진을 대체하여 데이터의 분산처리를 수행하는 컴포넌트입니다.
Tez에서 제공하는 Web UI를 통해 Tez 애플리케이션의 정보를 확인할 수 있습니다.
-
Tez Web UI에 접근하기 위해서는 클러스터 고가용성에 따라 마스터 1번 혹은 3번 노드에 퍼블릭 IP를 부착해야 합니다.
-
이후 사용자의 /etc/hosts 파일에 마스터 1번 혹은 3번 노드의 호스트명과 퍼블릭 IP 정보를 추가해야 합니다.
모든 설정이 끝나면 다음과 같이 접근할 수 있습니다.클러스터 고가용성 접속 포트 표준(Single) 마스터 1번 노드의 9999 포트 HA 마스터 3번 노드의 9999 포트 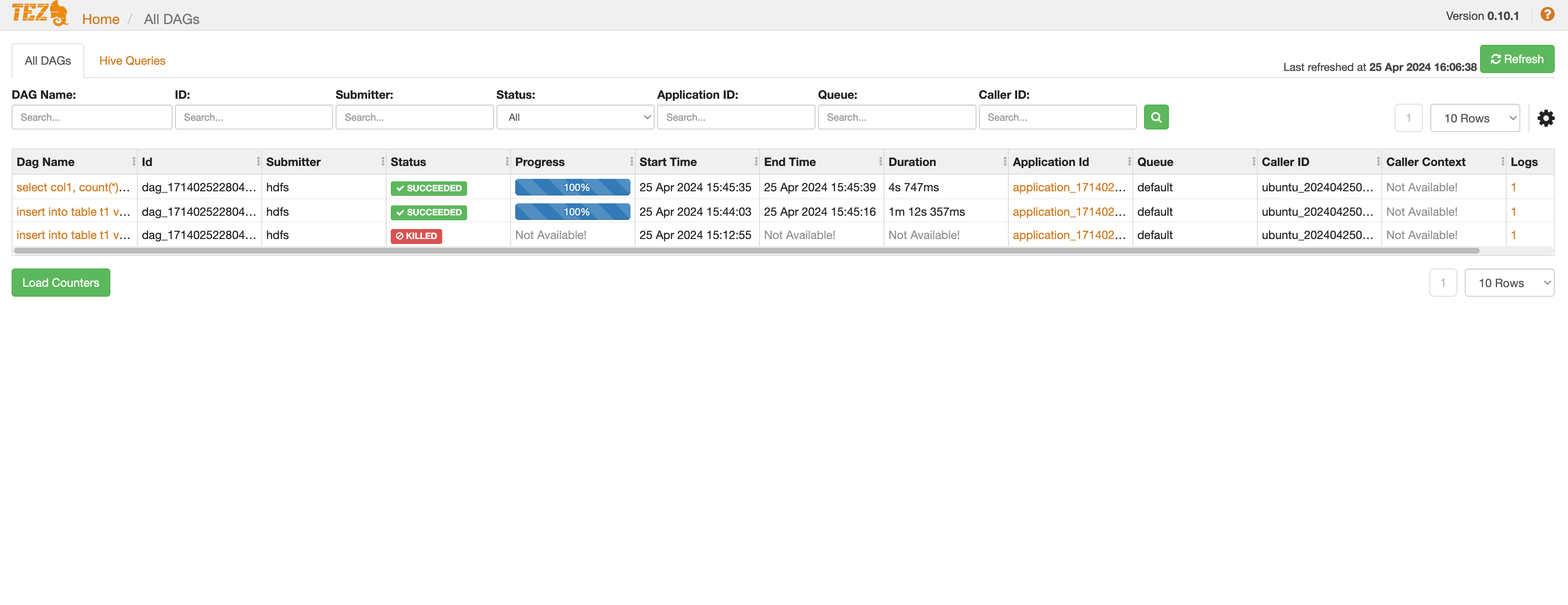 Trino-Zeppelin 쿼리 결과 확인
Trino-Zeppelin 쿼리 결과 확인
Trino
-
Trino CLI를 실행합니다. 서버 정보는 Trino Coordinator가 설치된 위치를 입력합니다.
클러스터 가용성 접속 포트 표준(Single) 마스터 1번 노드의 8780 포트 HA 마스터 3번 노드의 8780 포트 -
쿼리를 입력합니다.
Trino CLI를 이용한 쿼리 실행$ trino --server http://hadoopmst-trino-ha-3:8780
trino> SHOW CATALOGS;
Catalog
---------
hive
system
(2 rows)
Query 20220701_064104_00014_9rp8f, FINISHED, 2 nodes
Splits: 12 total, 12 done (100.00%)
0.23 [0 rows, 0B] [0 rows/s, 0B/s]
trino> SHOW SCHEMAS FROM hive;
Schema
--------------------
default
information_schema
(2 rows)
Query 20220701_064108_00015_9rp8f, FINISHED, 3 nodes
Splits: 12 total, 12 done (100.00%)
0.23 [2 rows, 35B] [8 rows/s, 155B/s]
trino> select * from hive.default.t1;
col1
------
a
b
c
(3 rows)
Query 20220701_064113_00016_9rp8f, FINISHED, 1 node
Splits: 5 total, 5 done (100.00%)
0.23 [3 rows, 16B] [13 rows/s, 71B/s]
Trino Web 접속하기
-
Trino Coordinator가 설치된 서버의 8780 포트로 Trino Web UI에 접속합니다.
클러스터 가용성 접속 포트 표준(Single) 마스터 1번 노드의 8780 포트 HA 마스터 3번 노드의 8780 포트 -
Trino 쿼리 히스토리와 통계 정보를 확인합니다.
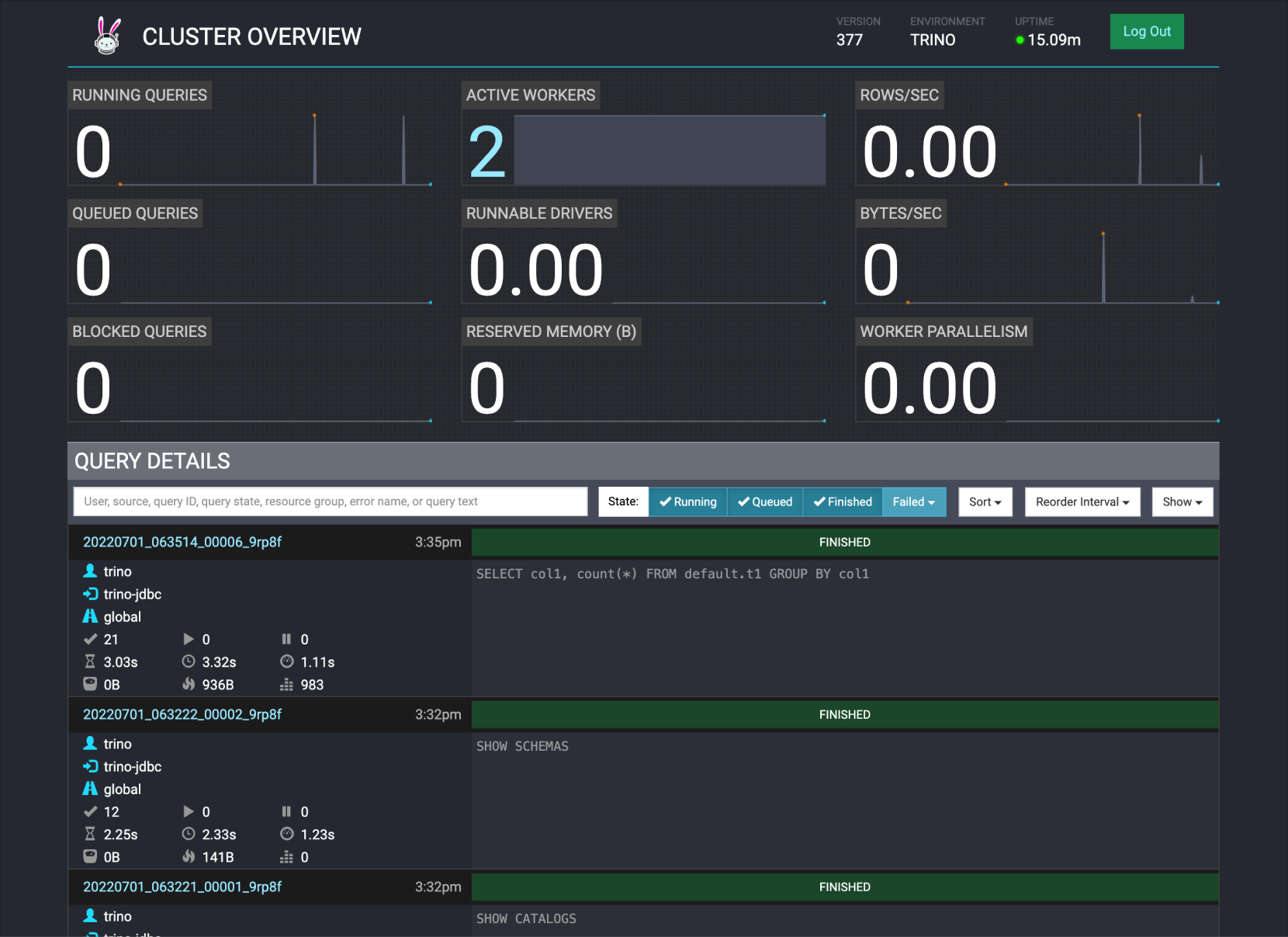 Trino Web 화면
Trino Web 화면
Trino - Zeppelin 연동하기
-
Zeppelin에서 인터프리터를 Trino로 선택합니다.
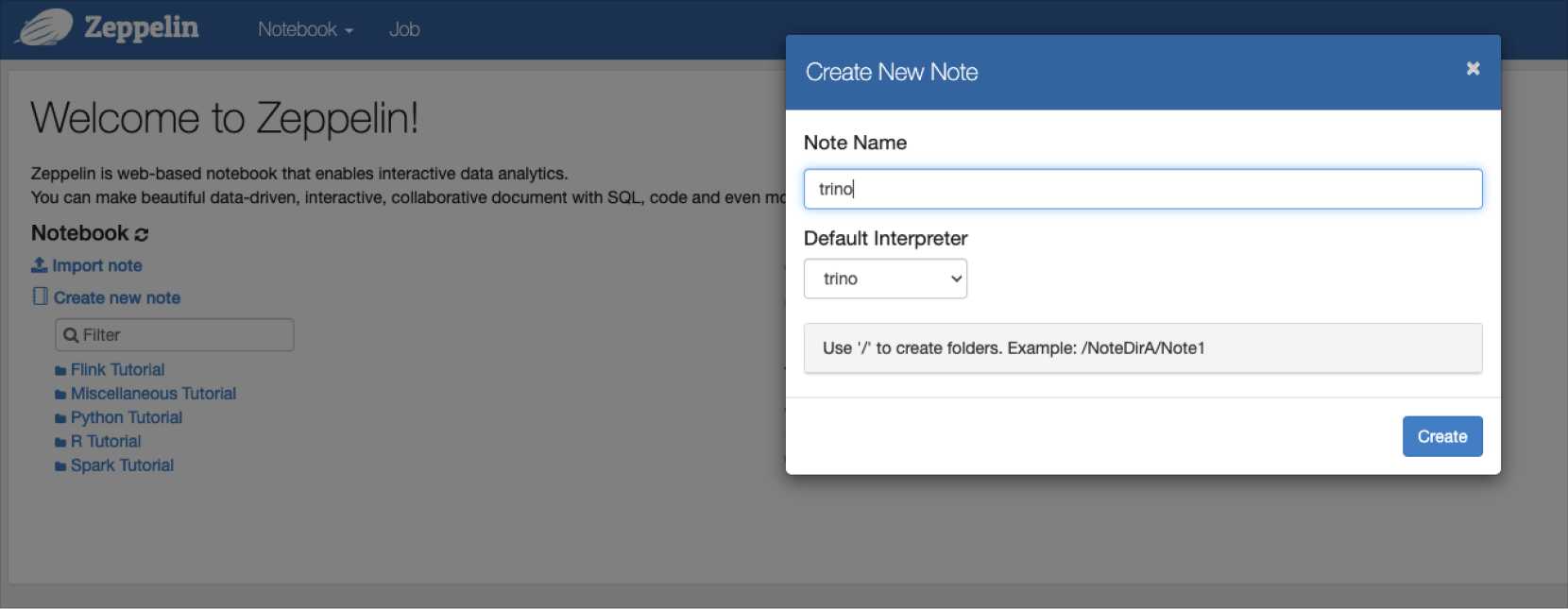 Trino-Zeppelin 연동
Trino-Zeppelin 연동 -
Trino에 조회하고자 하는 쿼리를 입력하면 결과를 확인할 수 있습니다.
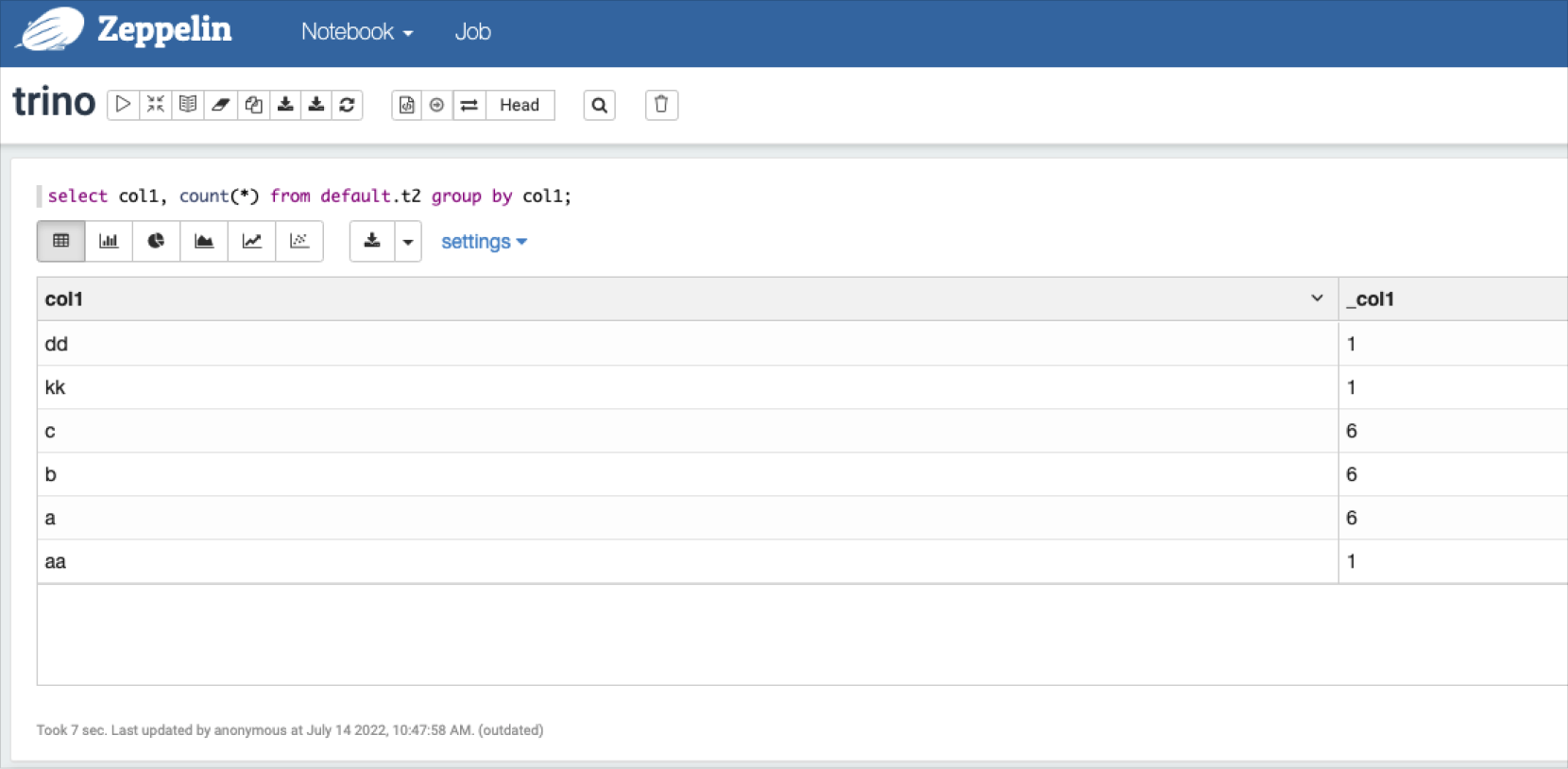 Trino-Zeppelin 쿼리 결과 확인
Trino-Zeppelin 쿼리 결과 확인
Kafka
아파치 카프카(Apache Kafka)는 Hadoop Eco 클러스터의 유형이 Dataflow일 때 제공되는 대규모 실시간 데이터 스트리밍 플랫폼입니다.
Hadoop Eco 클러스터에 설치된 카프카는 터미널에서 명령어를 통해 실행할 수 있습니다. 아래의 예시 이외의 자세한 설명은 카프카 공식 문서를 참고하시기 바랍니다.
- 토픽 생성
$ /opt/kafka/bin/kafka-topics.sh --create --topic my-topic --bootstrap-server $(hostname):9092
- 토픽에 이벤트 작성
$ echo '{"time":'$(date +%s)', "id": 1, "msg": "첫 번째 이벤트"}' | /opt/kafka/bin/kafka-console-producer.sh --topic my-topic --bootstrap-server $(hostname):9092
$ echo '{"time":'$(date +%s)', "id": 2, "msg": "두번째 이벤트"}' | /opt/kafka/bin/kafka-console-producer.sh --topic my-topic --bootstrap-server $(hostname):9092
$ echo '{"time":'$(date +%s)', "id": 3, "msg": "세번째 이벤트"}' | /opt/kafka/bin/kafka-console-producer.sh --topic my-topic --bootstrap-server $(hostname):9092
- 이벤트 확인
$ /opt/kafka/bin/kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server $(hostname):9092
{"time":1692604787, "id": 1, "msg": "첫 번째 이벤트"}
{"time":1692604792, "id": 2, "msg": "두번째 이벤트"}
{"time":1692604796, "id": 3, "msg": "세번째 이벤트"}
Druid
아파치 드루이드(Apache Druid)는 Hadoop Eco 클러스터의 유형이 Dataflow일 때 제공되는 대규모 데이터에 대한 빠른 분할 분석을 위해 설계된 실시간 분석 데이터베이스입니다. 드루이드는 다양한 종류의 데이터소스를 지원하여 데이터 파이프라인 구축에 적합합니다.
클러스터 상세 페이지에서 드루이드 퀵 링크를 통하여 라우터에서 제공하는 UI에 접속합니다.
Hadoop Eco 클러스터 유형별 드루이드 UI 접속 포트는 다음과 같습니다.
클러스터 유형별 드루이드 UI 접속 포트
| 클러스터 가용성 | 접속 포트 |
|---|---|
| 표준(Single) | 마스터 1번 노드의 3008 포트 |
| HA | 마스터 3번 노드의 3008 포트 |
드루이드 UI 둘러보기
-
Ingestion 작업 목록
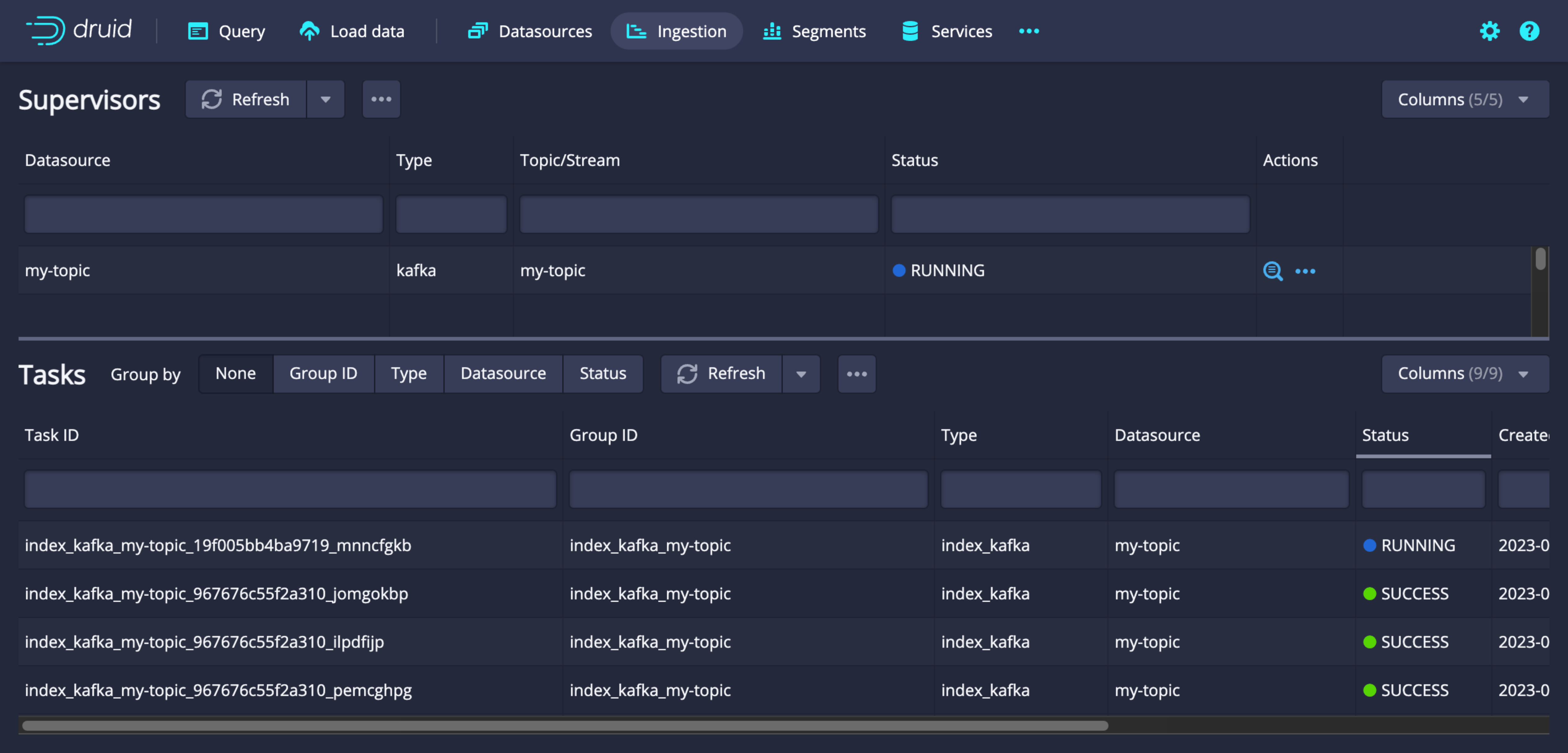
-
데이터소스 목록
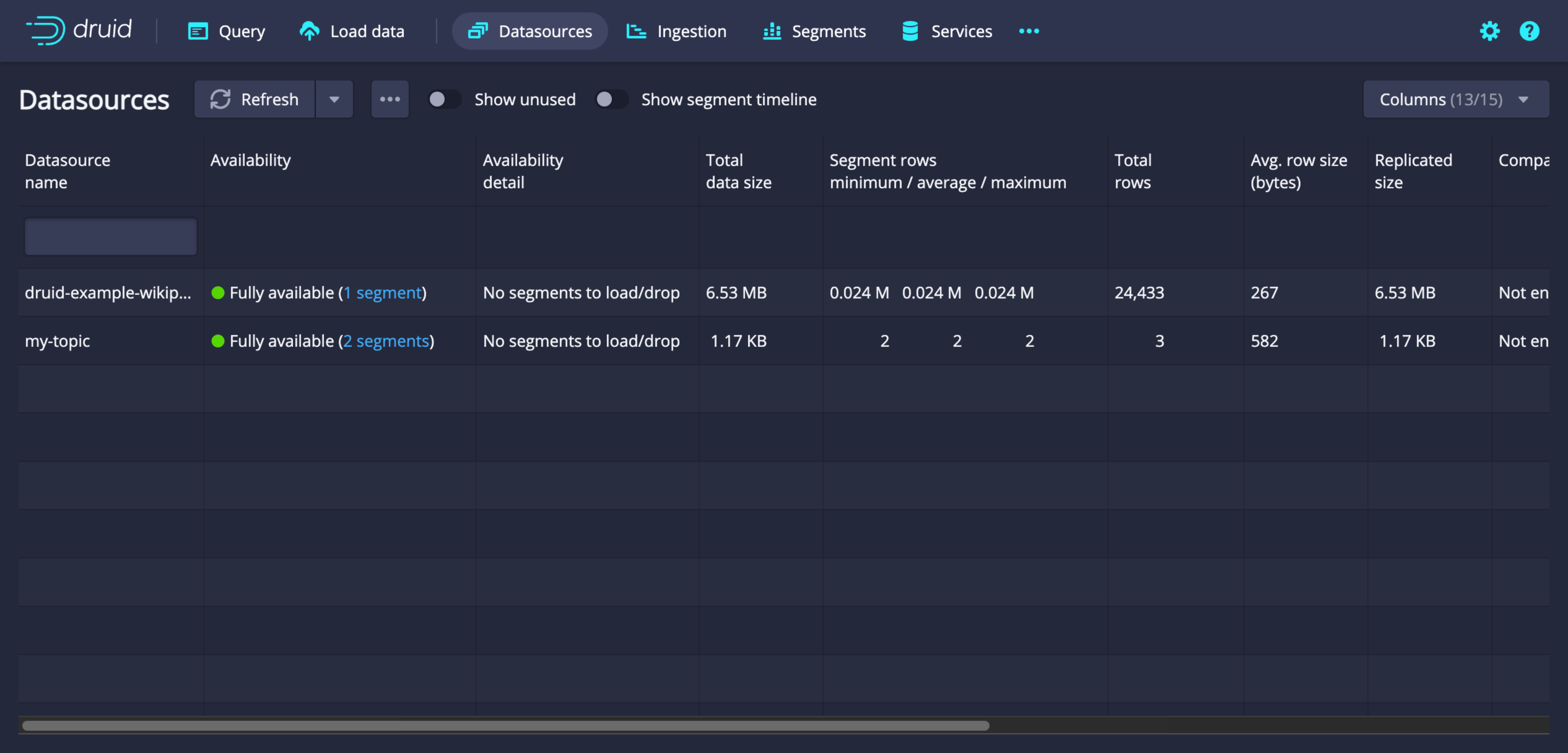
-
쿼리
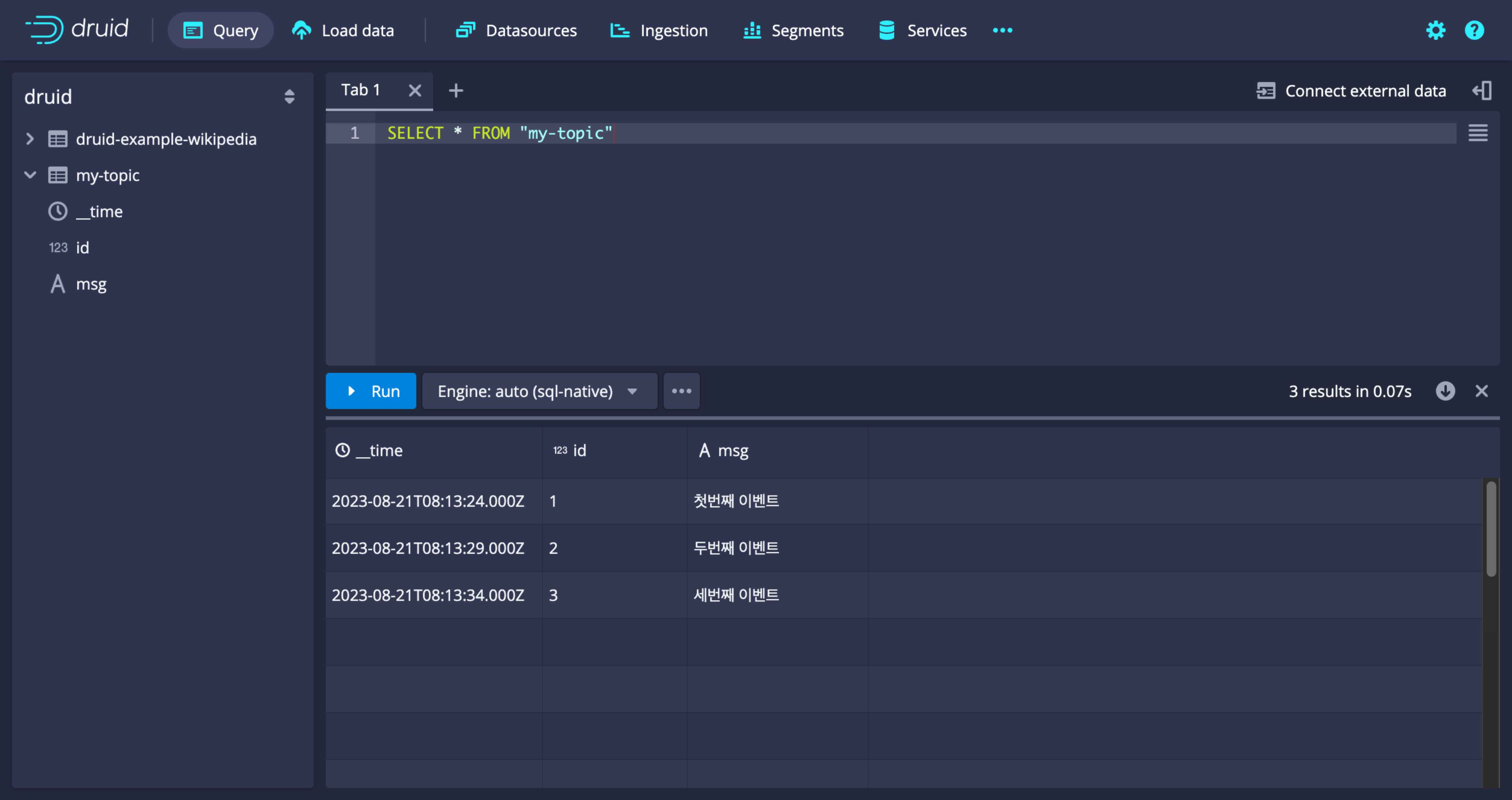
카프카에서 데이터 불러오기
-
드루이드 UI에서 Load data 탭 하위의 Streaming을 선택합니다. 연결 가능한 데이터소스에서 Apache Kafka를 선택합니다.
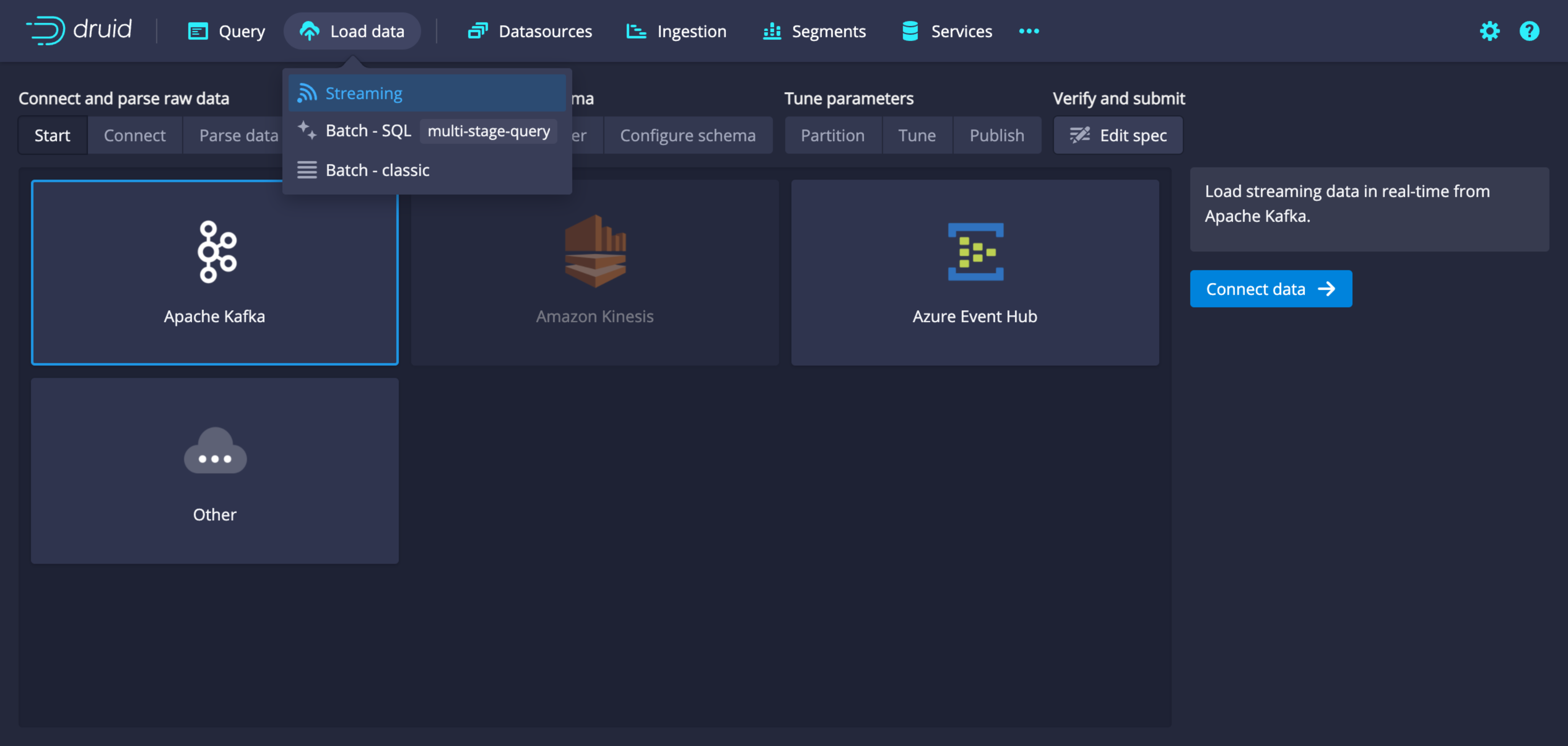
-
Bootstrap servers에
<hostname>:<port>의 형태로 연결하고자 하는 카프카의 호스트와 포트 정보를 입력합니다. Topic 칸에 불러오기를 원하는 토픽의 이름을 입력합니다.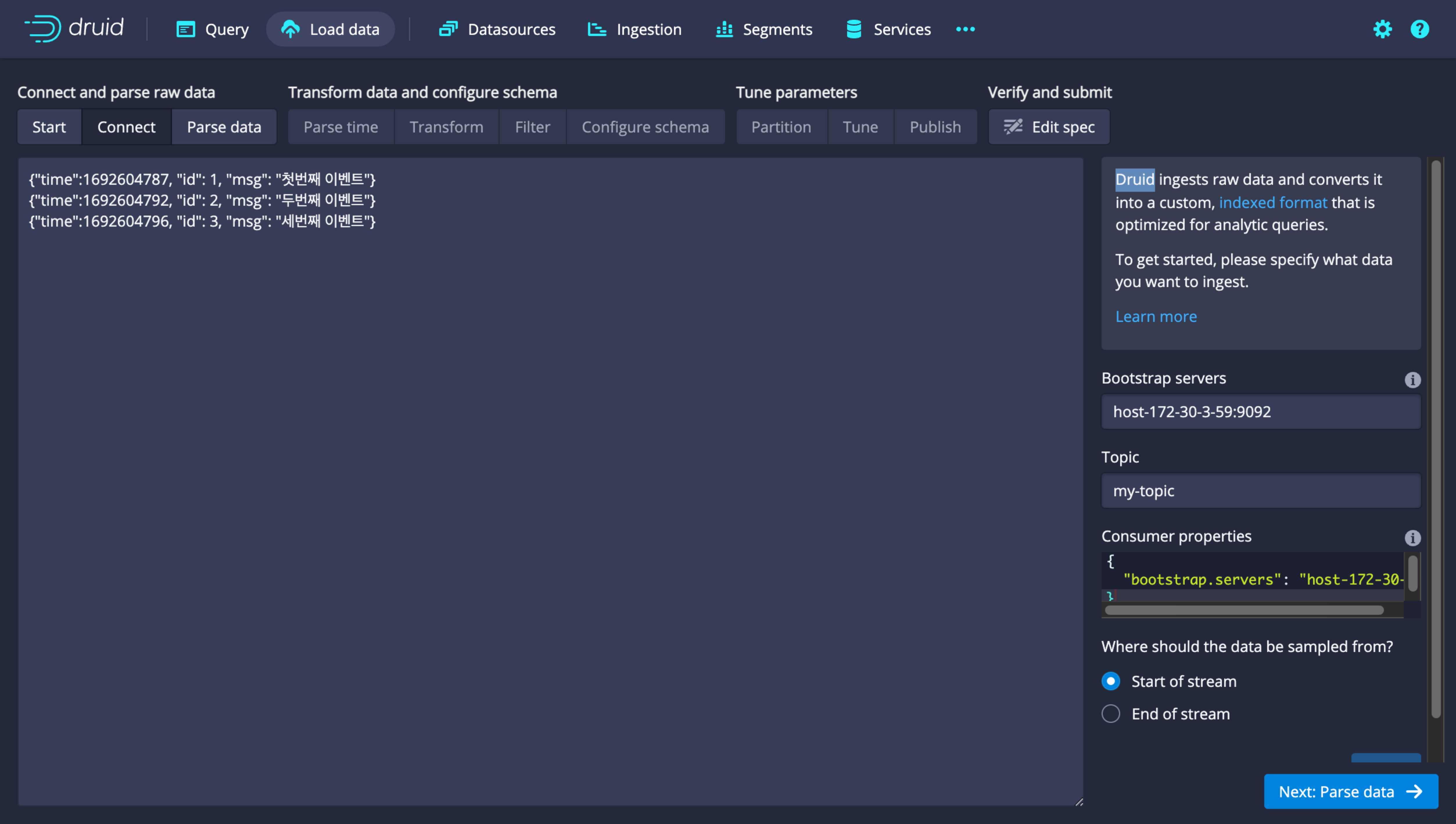
-
토픽 선택 이후 페이지에서는 불러오기를 원하는 데이터의 형상을 적절히 선택하고 아래와 같은 스펙을 마지막 페이지에서 확인하고 ingestion을 submit 합니다.
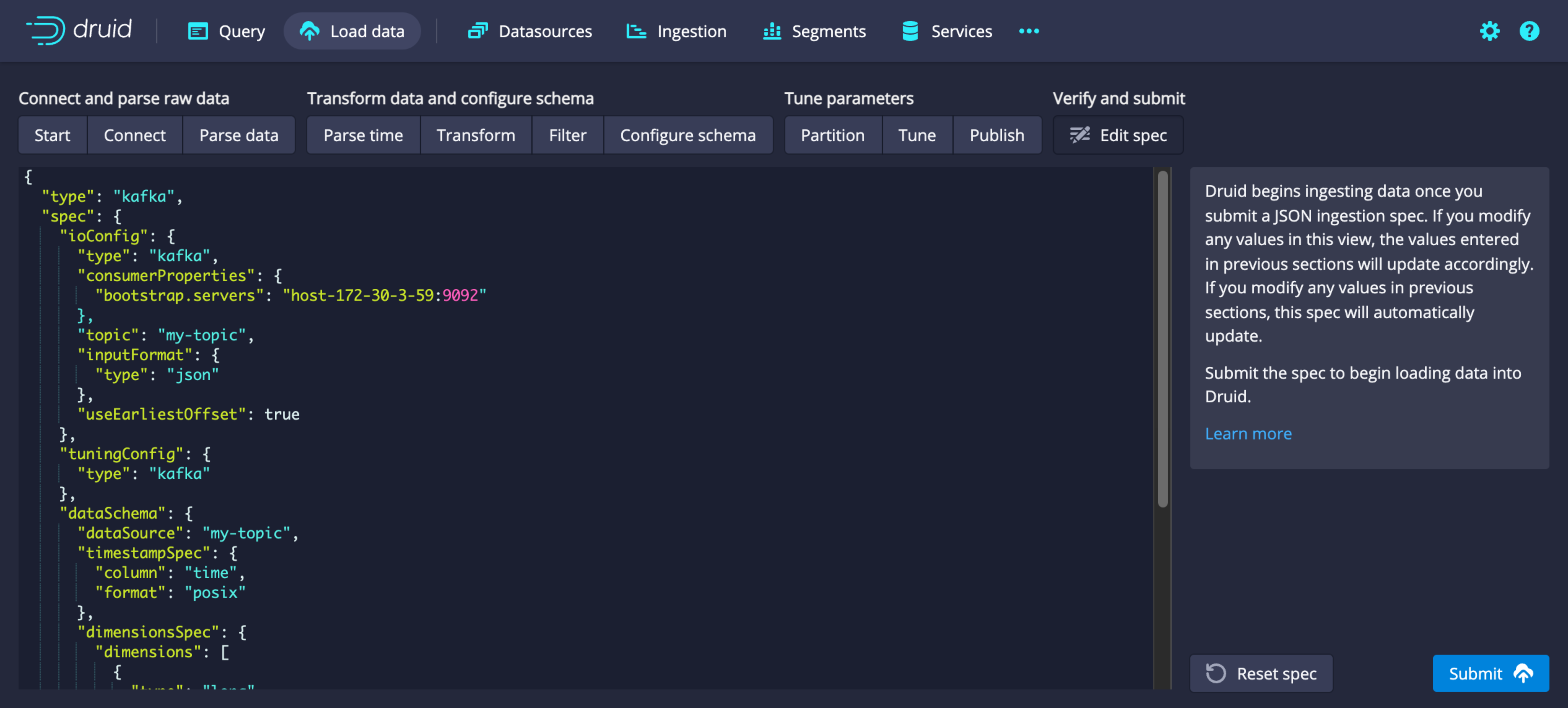
-
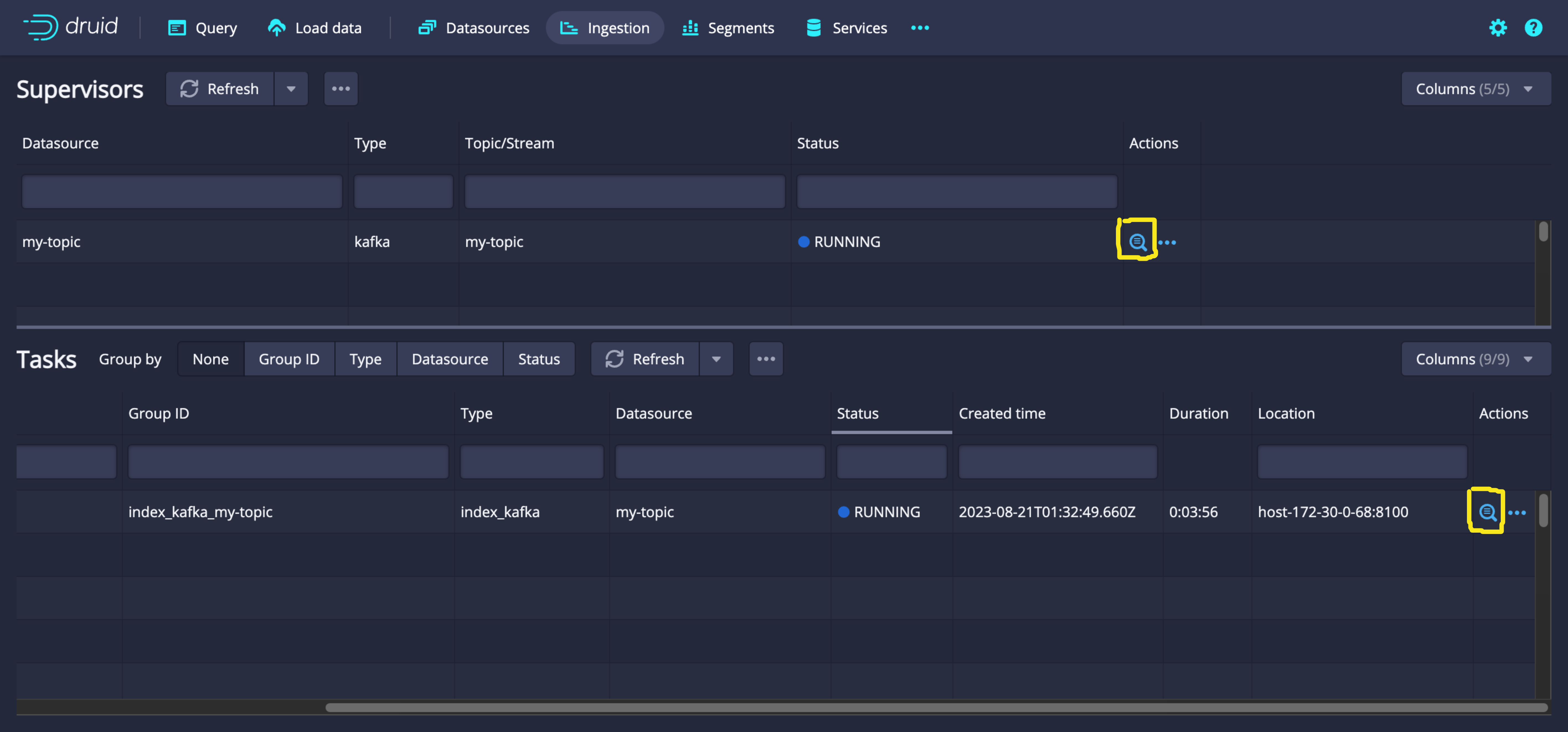
Ingestion 페이지에서 생성한 슈퍼비전의 상태를 확인합니다. Actions 칸의 돋보기 아이콘을 클릭하면 로그와 페이로드 등의 상세 정보를 확인할 수 있습니다.
Superset
Apache Superset은 Hadoop Eco 클러스터의 유형이 Dataflow일 때 제공되는 데이터 시각화 및 탐색 플랫폼입니다. Superset은 다양한 데이터소스(MySQL, SQLite, Hive, Druid, ...)와 연동이 가능하며, 쿼리, 그래프 작성, 대시보드 등 다양한 분석 도구를 제공하고 있습니다.
클러스터 상세 페이지에서 Superset 링크를 통하여 라우터에서 제공하는 UI에 접속합니다.
Hadoop Eco 클러스터 유형별 Superset UI 접속 포트는 다음과 같습니다.
클러스터 유형별 슈퍼셋 UI 접속 포트
| 클러스터 가용성 | 접속 포트 |
|---|---|
| 표준(Single) | 마스터 1번 노드의 4000 포트 |
| HA | 마스터 3번 노드의 4000 포트 |
Superset UI 둘러보기
-
대시보드 리스트
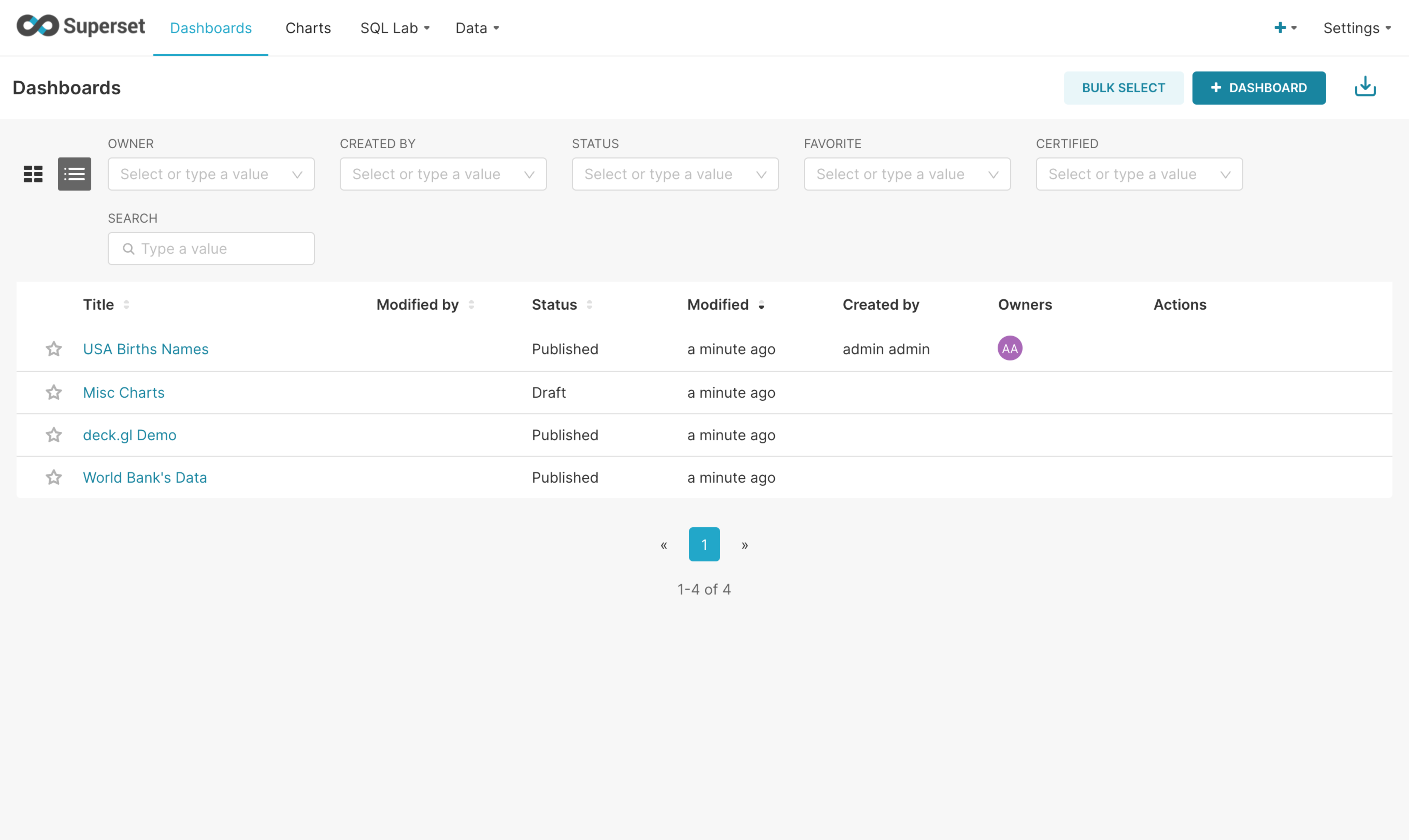
-
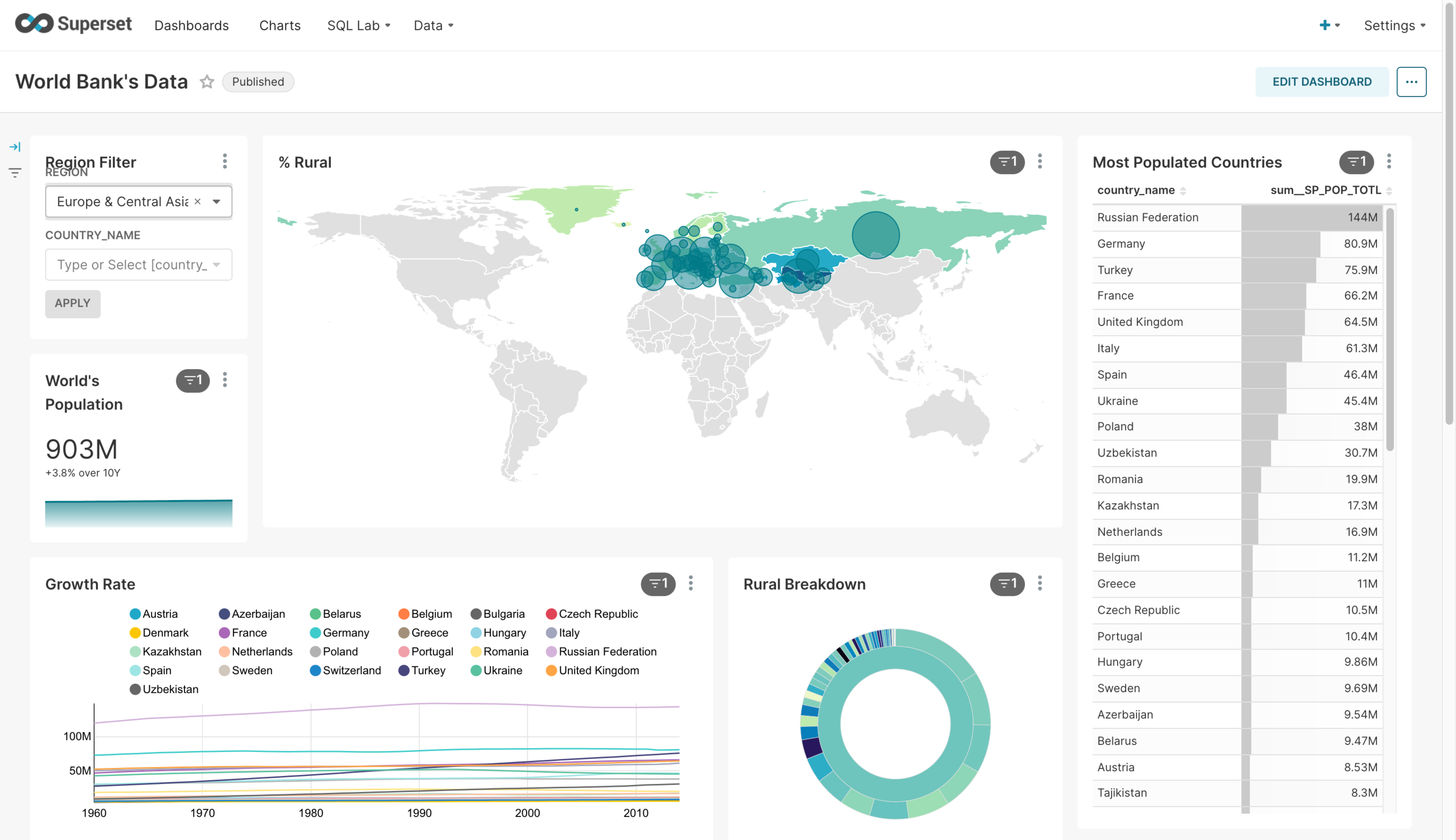
대시보드: 대시보드를 작성하여 저장하고 이를 이미지로 저장하거나 공유할 수 있는 링크를 얻을 수 있습니다.
-
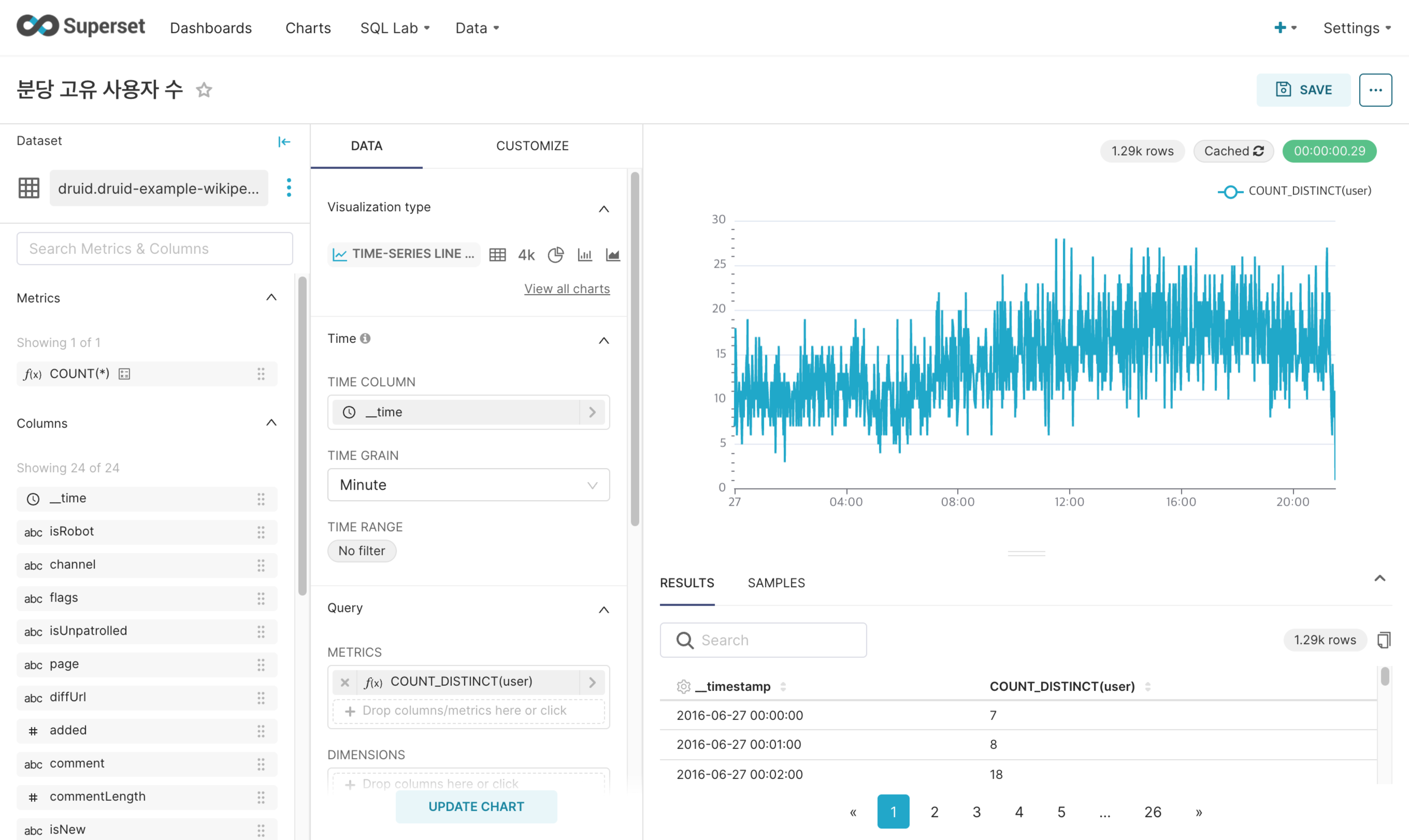
차트: 연결된 데이터베이스에서 등록된 물리 데이터세트 혹은 쿼리를 통해 저장된 가상 데이터세트를 이용하여 차트를 생성하고 저장할 수 있습니다.
-
쿼리 랩: 연결된 데이터베이스의 데이터에 대해 쿼리를 실행하여 결과를 확인할 수 있습니다.
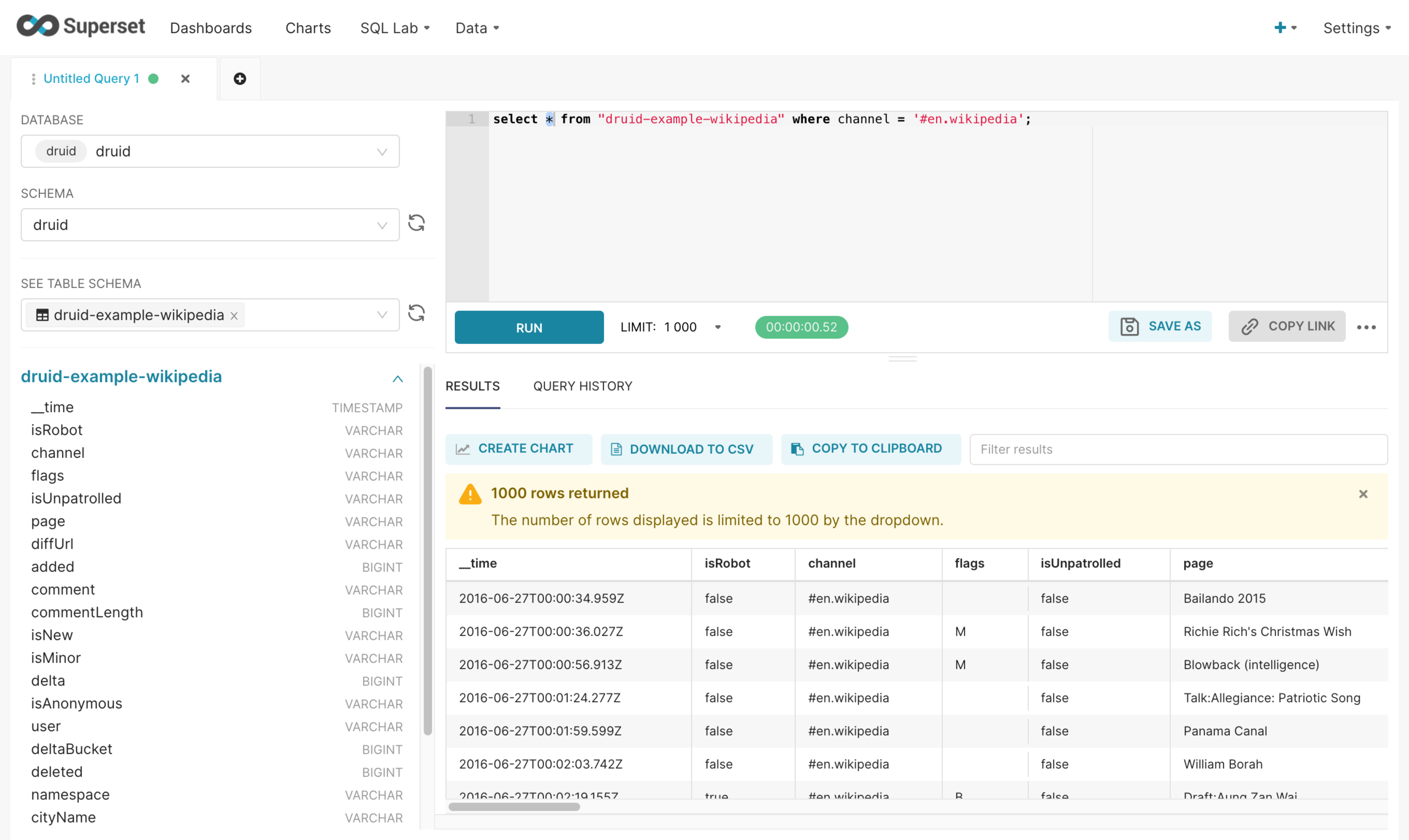
-
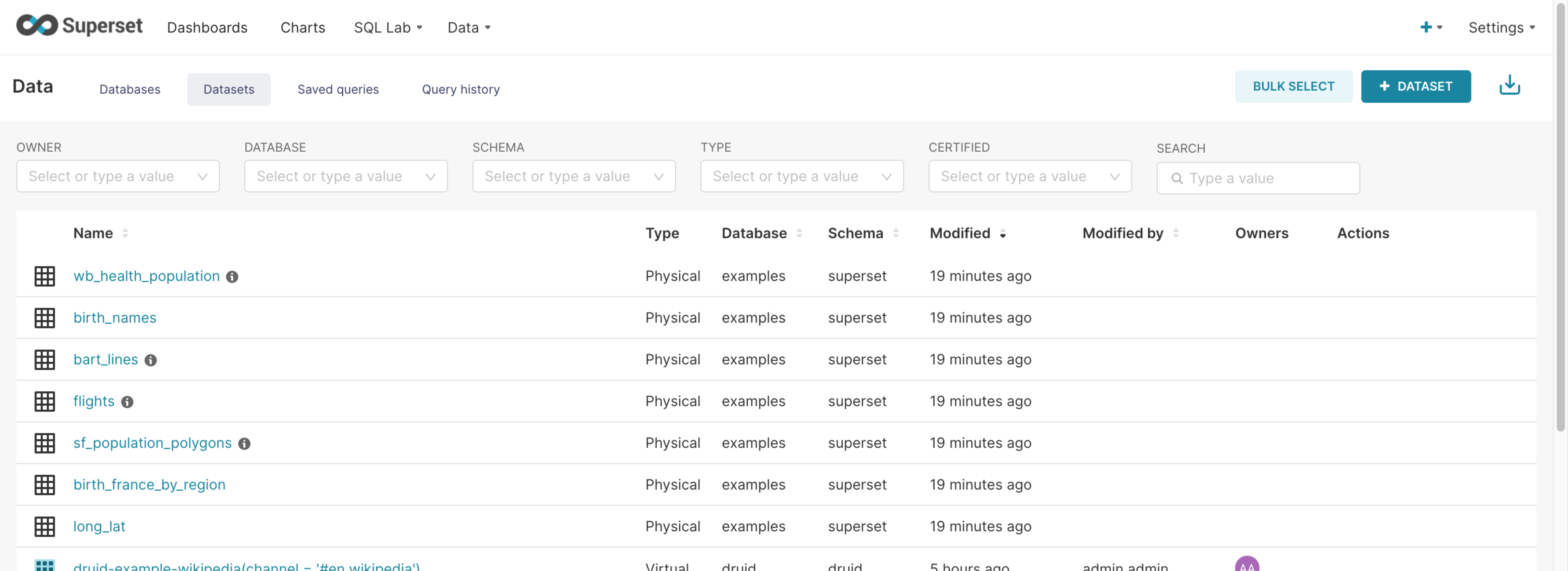
데이터: 연결된 데이터베이스와 생성한 데이터세트, 저장한 쿼리, 실행되었던 쿼리의 목록을 관리할 수 있습니다.
Superset 명령어 실행
Superset에서 제공하는 명령어는 터미널에서 아래와 같은 순서로 실행할 수 있습니다.
# 환경 변수 설정
$ export $(cat /opt/superset/.env)
# Superset 커맨드 실행 예시 $ /opt/superset/superset-venv/bin/superset --help
Loaded your LOCAL configuration at [/opt/superset/superset_config.py]
Usage: superset [OPTIONS] COMMAND [ARGS]...
This is a management script for the Superset application.
Options:
--version Show the flask version
--help Show this message and exit.
Commands:
compute-thumbnails Compute thumbnails
db Perform database migrations.
export-dashboards Export dashboards to ZIP file
export-datasources Export datasources to ZIP file
fab FAB flask group commands
import-dashboards Import dashboards from ZIP file
import-datasources Import datasources from ZIP file
import-directory Imports configs from a given directory
init Inits the Superset application
load-examples Loads a set of Slices and Dashboards and a...
load-test-users Loads admin, alpha, and gamma user for...
re-encrypt-secrets
routes Show the routes for the app.
run Run a development server.
set-database-uri Updates a database connection URI
shell Run a shell in the app context.
superset This is a management script for the Superset...
sync-tags Rebuilds special tags (owner, type, favorited...
update-api-docs Regenerate the openapi.json file in docs
update-datasources-cache Refresh sqllab datasources cache
version Prints the current version number
Flink on Yarn Session
Apache Flink는 Apache Software Foundation에서 개발한 오픈 소스, 통합 스트림 처리 및 일괄 처리 프레임워크입니다. Flink를 Yarn 세션 모드로 실행하는 방법은 다음과 같습니다.
Flink 실행하기
Flink를 세션 모드로 실행할 때 옵션을 이용해서 Flink가 사용할 수 있는 리소스를 조절할 수 있습니다.
| 실행 옵션 | 설명 |
|---|---|
| -jm | 잡 매니저 메모리 사이즈 |
| -tm | 태스크 매니저 메모리 사이즈 |
| -s | CPU 코어 개수 |
| -n | 태스크 매니저 개수 |
| -nm | 애플리케이션 이름 |
| -d | 백그라운드 모드 |
yarn-session.sh \
-jm 2048 \
-tm 2048 \
-s 2 \
-n 3 \
-nm yarn-session-jobs
Flink 인터페이스
Flink를 실행하면 Yarn의 노드에서 Flink가 실행되고 WebUI가 실행되어 해당 위치로 접속할 수 있습니다.
2022-07-07 23:15:33,775 INFO org.apache.flink.shaded.curator4.org.apache.curator.framework.state.ConnectionStateManager [] - State change: CONNECTED
2022-07-07 23:15:33,800 INFO org.apache.flink.runtime.leaderretrieval.DefaultLeaderRetrievalService [] - Starting DefaultLeaderRetrievalService with ZookeeperLeaderRetrievalDriver{connectionInformationPath='/leader/rest_server/connection_info'}.
JobManager Web Interface: http://hadoopwrk-logan-표준(Single)-2:8082
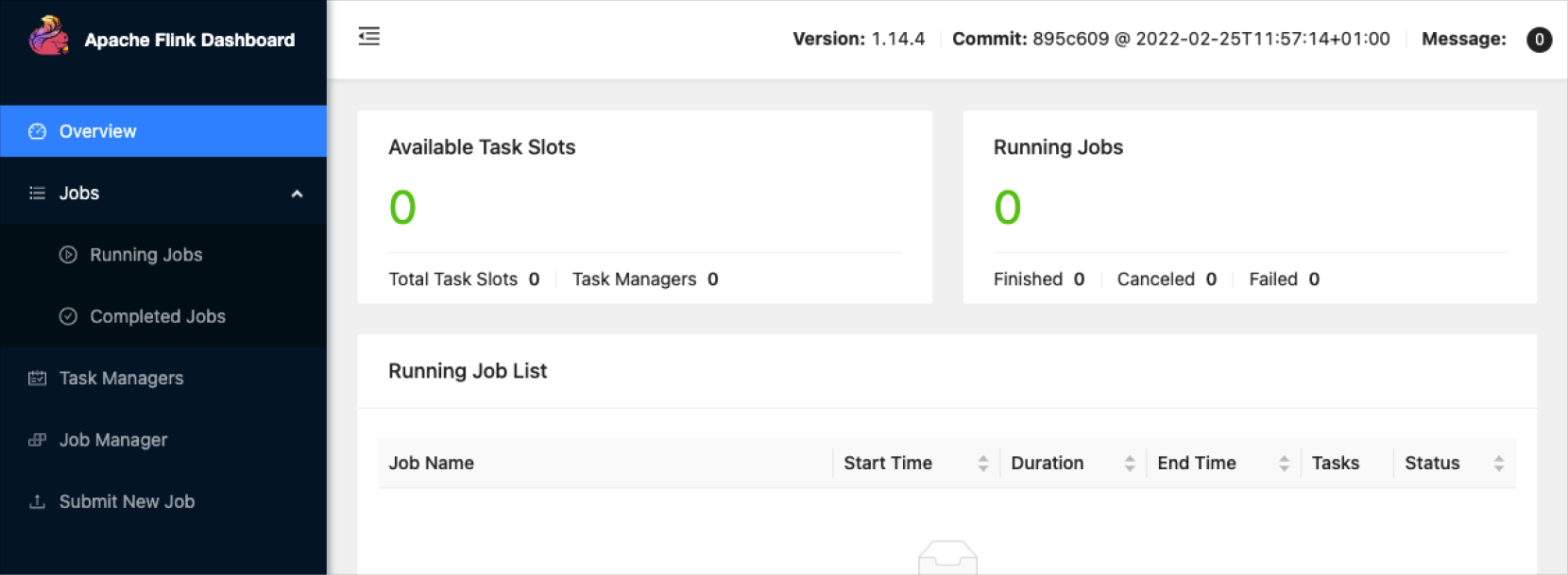 Flink Web 화면
Flink Web 화면
Flink 작업 실행하기
Flink on Yarn Session을 실행한 후 사용자 작업을 실행하고, 웹사이트에서 확인할 수 있습니다.
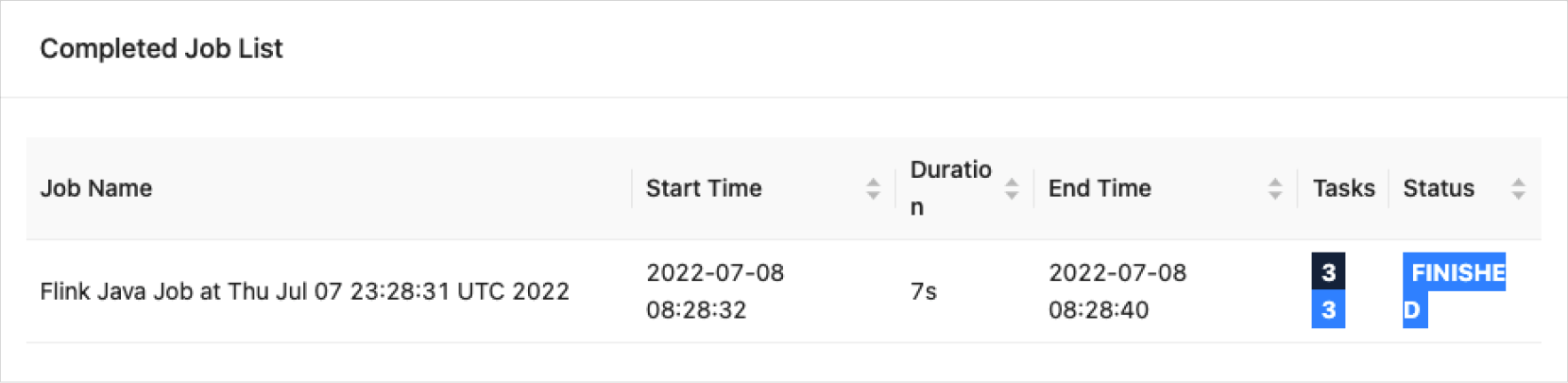 Flink 작업 실행
Flink 작업 실행
$ flink run /opt/flink/examples/batch/WordCount.jar
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 43aee6d7d947b1ce848e01c094801ab4
Program execution finished
Job with JobID 43aee6d7d947b1ce848e01c094801ab4 has finished.
Job Runtime: 7983 ms
Accumulator Results:
- 4e3b3f0ae1b13d861a25c3798bc15c04 (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
Kakao HBase Tools
HBase Tools는 Kakao에서 개발한 오픈 소스입니다. 카카오클라우드 콘솔에서 Hadoop Eco 메뉴를 선택합니다. 클러스터 목록에서 삭제할 클러스터의 [⋮] 버튼 > 클러스터 삭제를 선택합니다. 팝업창에서 삭제할 클러스터를 확인한 후, 영구 삭제를 입력하고 [삭제] 버튼을 클릭합니다.
자세한 설명은 Kakao Tech 블로그를 참고하시기 바랍니다.
| 구분 | 설명 |
|---|---|
| hbase-manager Module | 리전 배치 관리, 스플릿, 머지, 메이저 컴팩션 제공 - Region Assignment Management - Advanced Split - Advanced Merge - Advanced Major Compaction |
| hbase-table-stat Module | 성능 모니터링 - Table Metrics Monitoring |
| hbase-snapshot Module | HBase에 저장된 데이터를 백업 및 복구 - Table Snapshot Management |
Kakao HBase Tools 실행
Zookeeper 호스트 정보를 전달하여 HBase 정보를 가져옵니다.
# hbase-manager
java -jar /opt/hbase/lib/tools/hbase-manager-1.2-1.5.7.jar <command> <zookeeper host name> <table name>
# hbase-snapshot
java -jar /opt/hbase/lib/tools/hbase-snapshot-1.2-1.5.7.jar <zookeeper host name> <table name>
# hbase-table-stat
java -jar /opt/hbase/lib/tools/hbase-table-stat-1.2-1.5.7.jar <zookeeper host name> <table name>
hbase-manager
HBase 관리를 위한 Admin Tool입니다.
 hbase-manager
hbase-manager
hbase-table-stat
테이블의 현재 사용 상태를 확인하기 위한 Tool입니다.
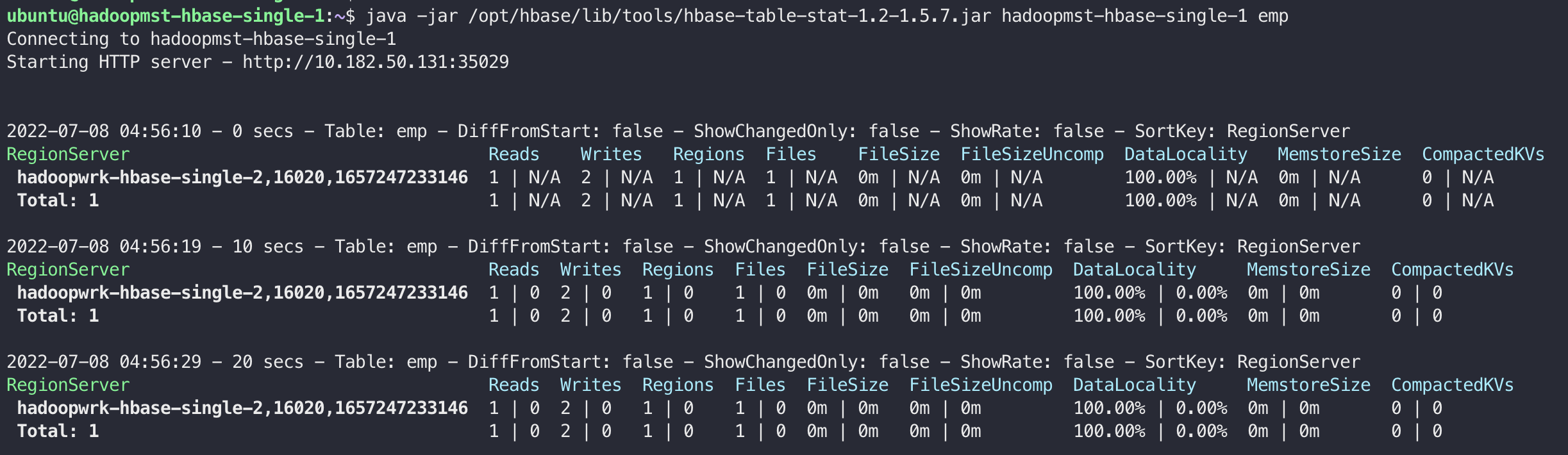 hbase-table-stat
hbase-table-stat
hbase-snapshot
테이블 데이터 스냅샷 생성을 위한 Tool입니다.
 hbase-snapshot
hbase-snapshot