메모리 최적화(Memory optimized)
메모리 최적화 인스턴스(Memory optimized instance)는 메모리에서 대규모 데이터를 처리하는 워크로드에 대해 빠른 성능을 제공하도록 설계되었습니다. 이 인스턴스는 관계형 고성능 데이터베이스, 인 메모리 캐시, Hadoop 및 Spark 클러스터 기반 대용량 비정형 데이터의 실시간 처리 애플리케이션, 고성능 컴퓨팅(HPC) 및 전자 설계 자동화(EDA) 애플리케이션에 적합합니다.
- 적용 유형 :
r2a
r2a
r2a 인스턴스는 3세대 AMD EPYC 7000 시리즈 프로세서와 메모리 최적화 기술을 활용하여 높은 성능과 안정성을 제공합니다. 이 인스턴스는 최대 3.6GHz의 올코어 터보 클록 속도를 지원하며, 대규모 데이터를 처리하는 메모리 집약적인 워크로드에 최적화되어 있습니다.
하드웨어 사양
- 최대 3.6GHz의 3세대 AMD EPYC 프로세서(AMD EPYC 7643)
- 최대 25Gbps의 네트워크 대역폭 (Bare Metal Server는 50Gbps)
- 최대 96개의 vCPU 및 768GiB 메모리를 지원하는 인스턴스 크기 (Bare Metal Server는 192 vCPU 및 2,048GiB 메모리)
- 모든 크기에서 8:1의 Memory 대 vCPU 비율(Bare Metal Server는 제외)
- AMD 명령어 세트(AVX, AVX2) 지원
사용 사례
- 고성능 데이터베이스(관계형 및 NoSQL)
- Memcached 및 Redis와 같은 분산 웹 스케일 인 메모리 캐시
- Hadoop 및 Spark 클러스터와 같은 실시간 빅 데이터 분석
세부 정보
| 인스턴스 크기 | vCPU | 메모리(GiB) | 네트워크 대역폭(Gbps) |
|---|---|---|---|
r2a.large | 2 | 16 | 최대 10 |
r2a.xlarge | 4 | 32 | 최대 10 |
r2a.2xlarge | 8 | 64 | 최대 10 |
r2a.4xlarge | 16 | 128 | 최대 10 |
r2a.8xlarge | 32 | 256 | 최대 10 |
r2a.12xlarge | 48 | 384 | 최대 12.5 |
r2a.16xlarge | 64 | 512 | 최대 12.5 |
r2a.24xlarge | 96 | 768 | 최대 25 |
r2a.baremetal | 192 | 2,048 | 50 |
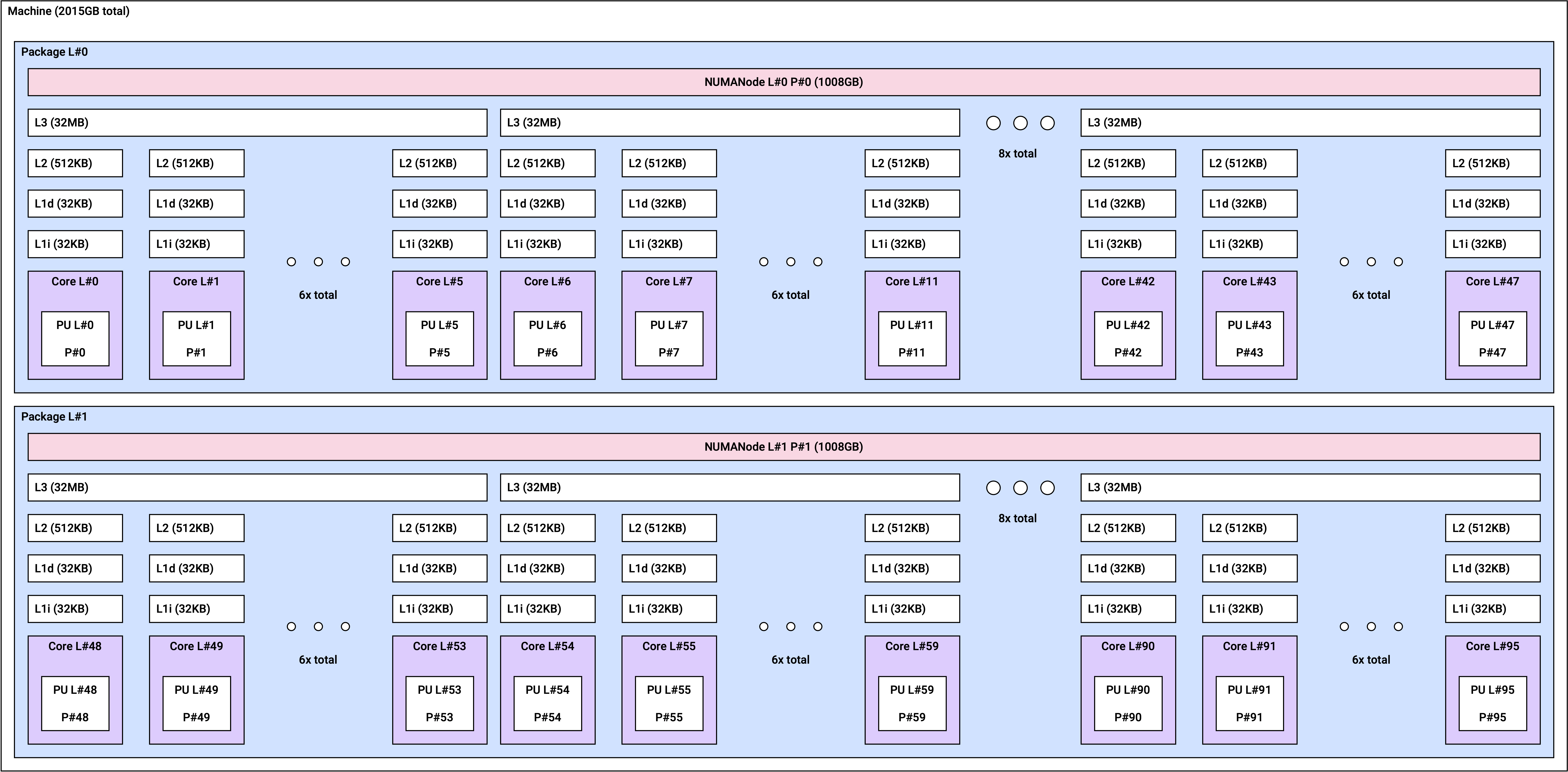
NUMA 토폴로지
Non-Uniform Memory Access(NUMA) 아키텍처에서는 각 CPU가 자체적으로 할당된 메모리(로컬 메모리)에 액세스할 수 있습니다. NUMA 아키텍처를 사용하면 여러 프로세서가 메모리를 공유 가능하므로 높은 확장성을 보장합니다.
r2a 인스턴스는 인스턴스 크기에 따라 아래와 같은 NUMA 토폴로지를 갖습니다.
| 인스턴스 크기 | NUMA 도메인 수 | NUMA당 기본 코어 수 |
|---|---|---|
r2a.large | 1 | 1 |
r2a.xlarge | 1 | 2 |
r2a.2xlarge | 1 | 4 |
r2a.4xlarge | 1 | 8 |
r2a.8xlarge | 2 | 8 |
r2a.12xlarge | 2 | 12 |
r2a.16xlarge | 2 | 16 |
r2a.24xlarge | 2 | 24 |
r2a.baremetal | 2 | 48 |
NUMA 토폴로지 아키텍처
r2a.large
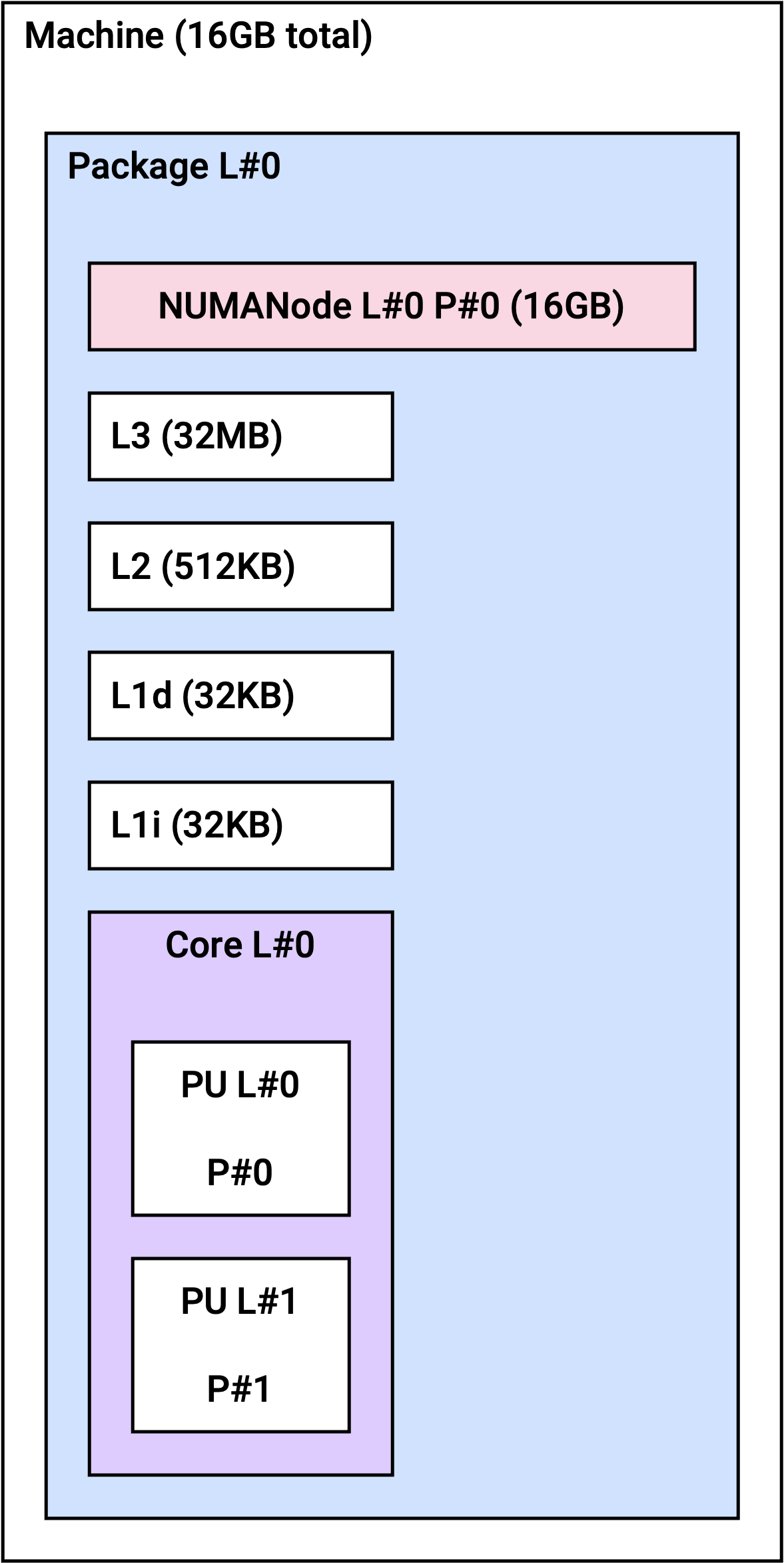
r2a.xlarge
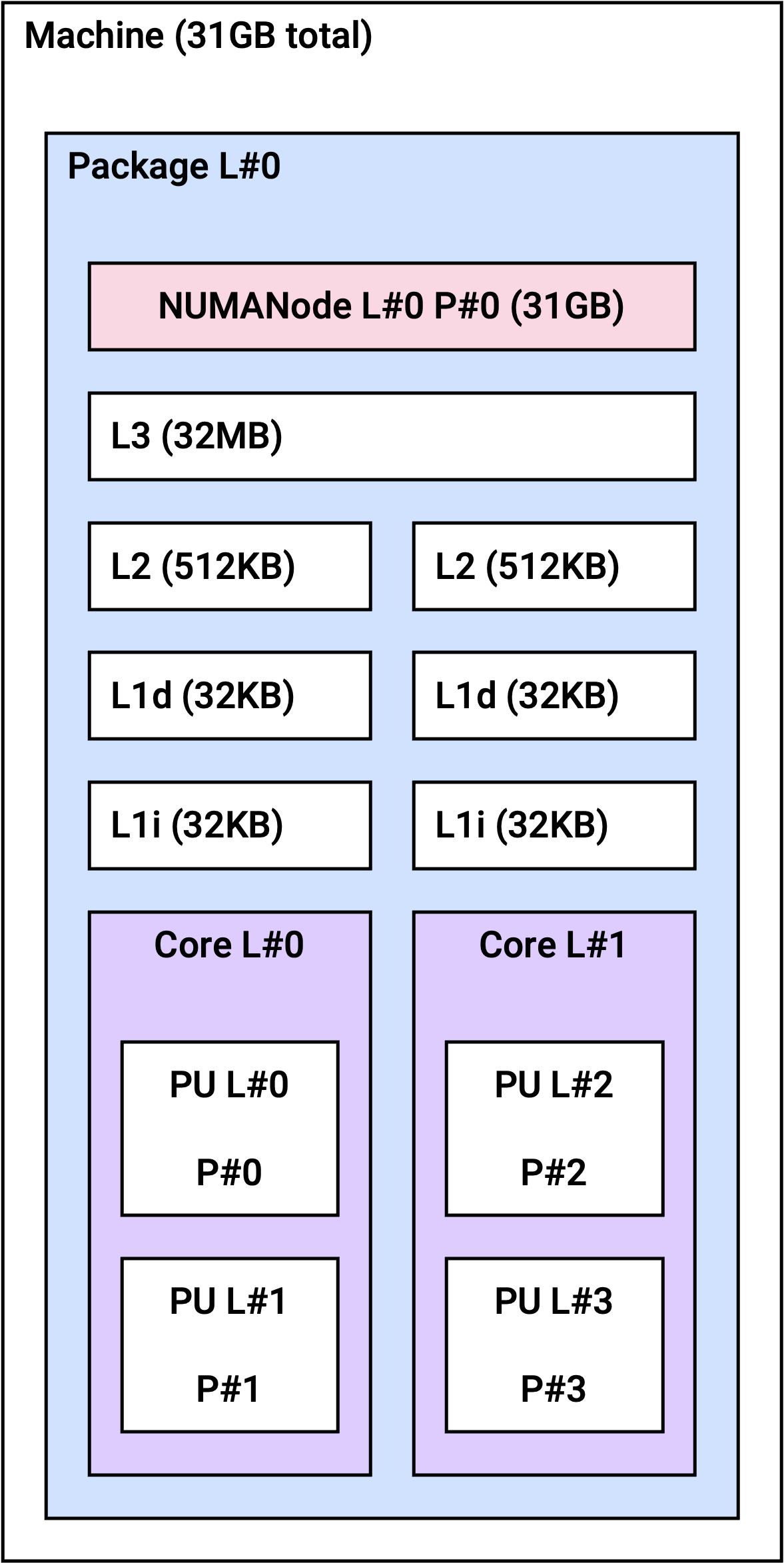
r2a.2xlarge
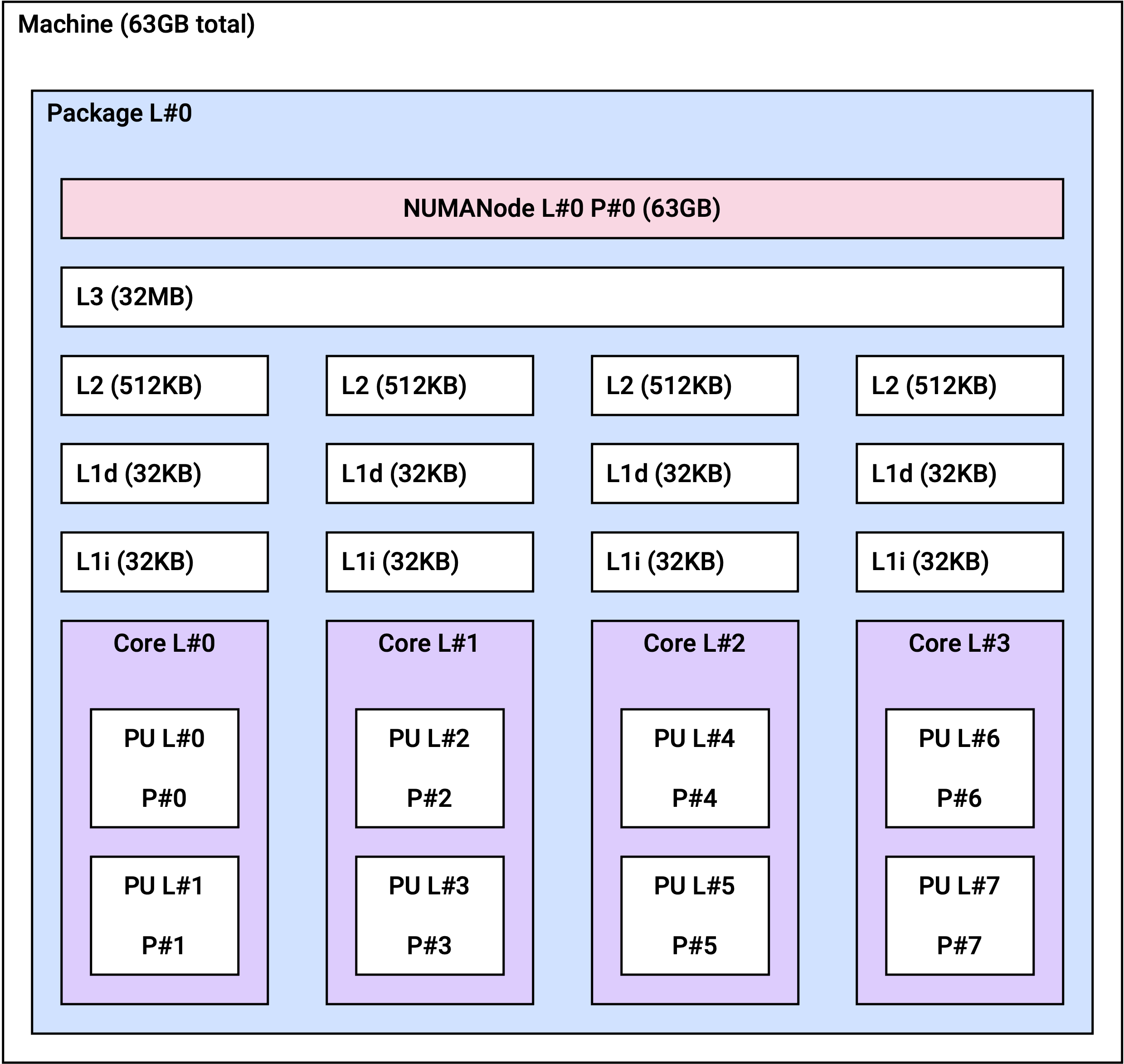
r2a.4xlarge
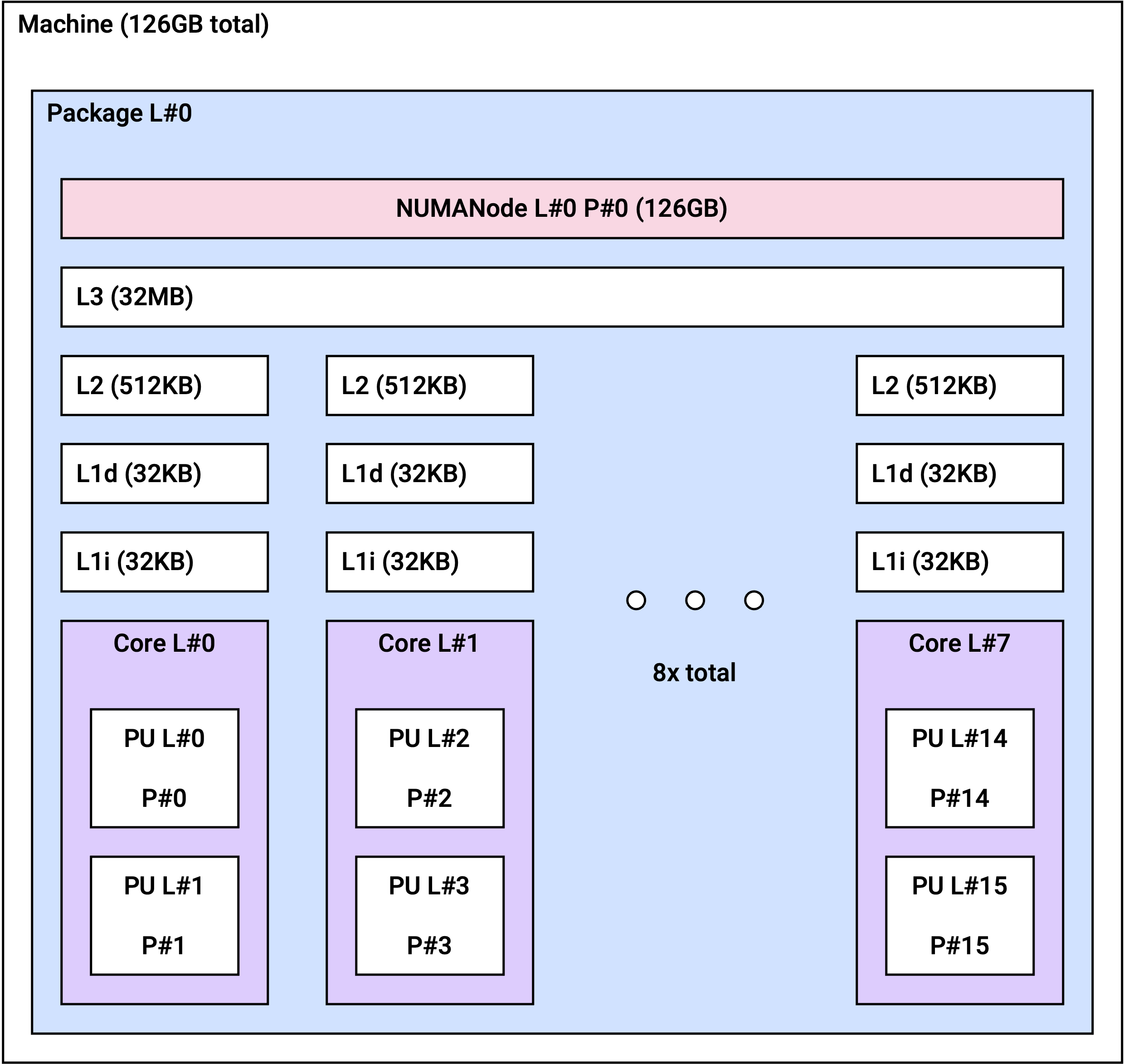
r2a.8xlarge
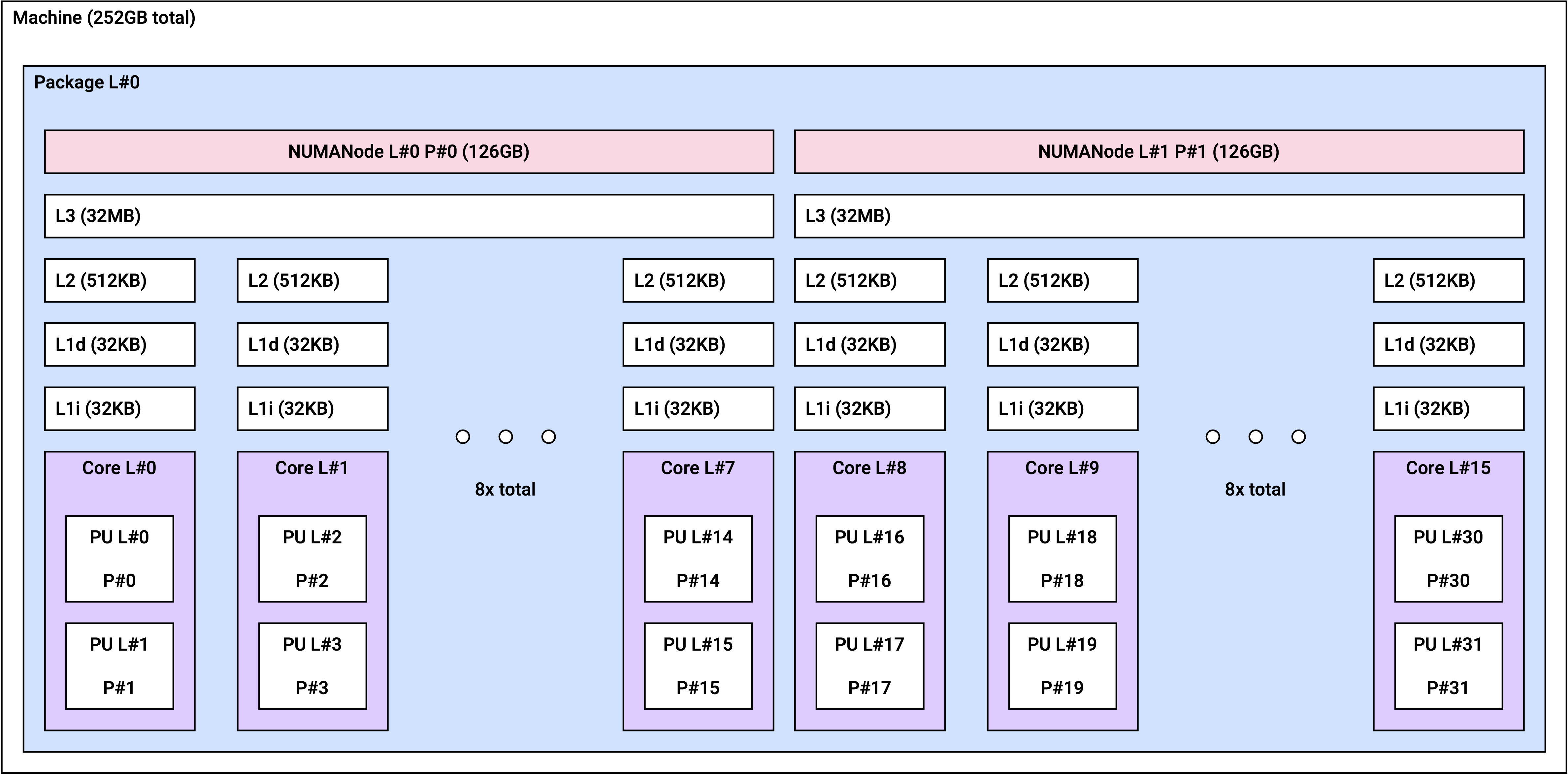
r2a.12xlarge
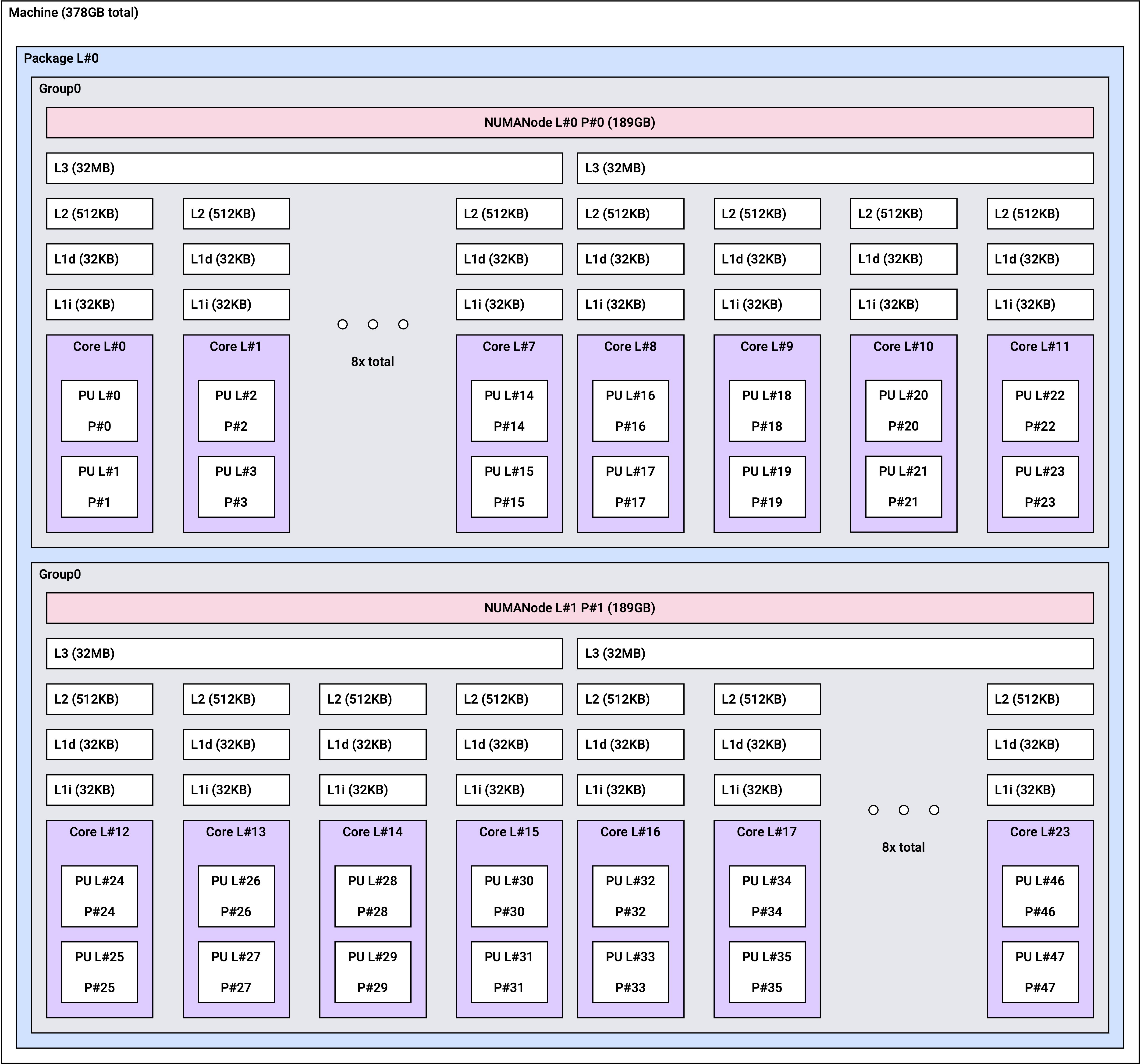
r2a.16xlarge
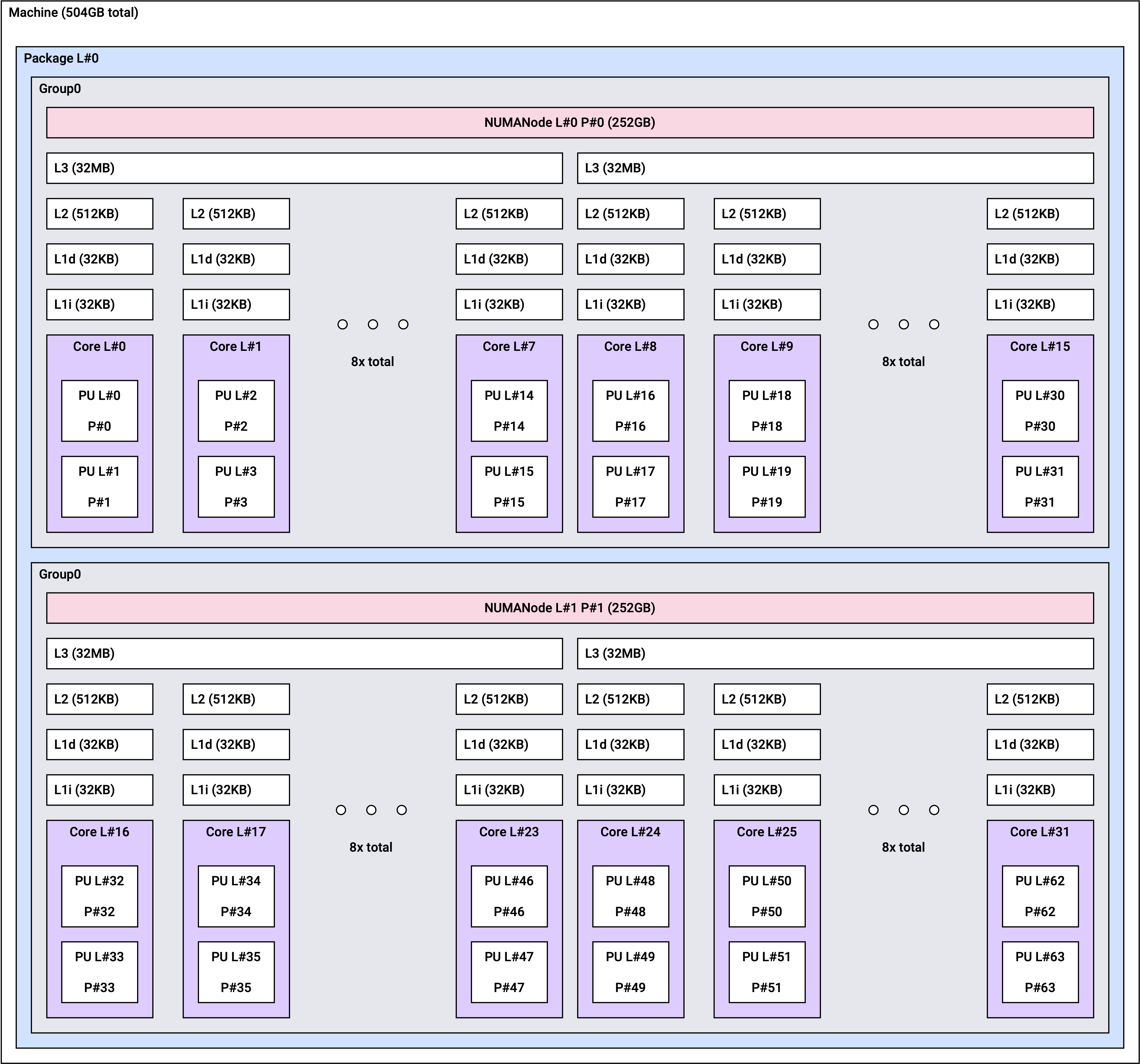
r2a.24xlarge
r2a.baremetal