주요 개념
MemStore 서비스에서 클러스터, 샤드, 노드, 고가용성, 백업, 파라미터 그룹이 어떻게 구성되고 동작하는지 설명합니다. 리소스별 생성과 관리 방법은 각 How-to Guides에서 확인할 수 있습니다.
| 주요 개념 | 설명 |
|---|---|
| Cache Only | 디스크를 사용하지 않고 모든 데이터를 메모리에 저장하는 캐시 서비스 |
| 클러스터 | 샤드와 노드를 포함하는 MemStore의 관리 단위 |
| 샤드 | 클러스터 모드를 사용하는 클러스터에서 데이터를 분산 저장하는 단위 |
| 노드 | Primary 또는 Replica 역할을 가지는 Redis OSS 실행 단위 |
| 고가용성 | 노드 장애 시 자동 조치를 통해 서비스를 지속할 수 있도록 지원하는 기능 |
| 승격 | Replica 노드를 Primary 노드로 전환하는 기능 |
| 엔드포인트 | 클러스터 또는 노드에 접속하기 위해 제공되는 접근 주소 |
| 백업 | 클러스터 정보를 저장해 복원에 사용하는 데이터 사본 |
| 파라미터 그룹 | Redis OSS 설정 파라미터를 그룹 단위로 관리하는 객체 |
Cache Only
MemStore에서 제공하는 Redis 서비스는 모든 데이터를 디스크에 저장하지 않고 메모리에 저장해 캐시 용도로만 사용할 수 있습니다.
클러스터
클러스터는 하나 이상의 노드 모음으로서, 자동으로 관리되는 구성 단위입니다. 클러스터는 다수의 샤드 내 여러 노드로 구성되며 각 노드는 Primary와 Replica의 역할을 가집니다. 필요에 따라 샤드 또는 Replica 노드를 추가하거나 삭제할 수 있습니다.
클러스터 생성 방법은 클러스터 생성을, 클러스터 조회와 관리 방법은 클러스터 관리를 참고해 주세요.
클러스터 생명 주기 및 상태 값
클러스터의 생명 주기와 상태 값은 다음과 같습니다.
- 클러스터 모드 사용 시
- 클러스터 모드 미사용 시
클러스터 모드를 사용할 경우, 샤드와 각 노드의 상태는 클러스터 상태에 의존하므로 동일한 상태를 가집니다.
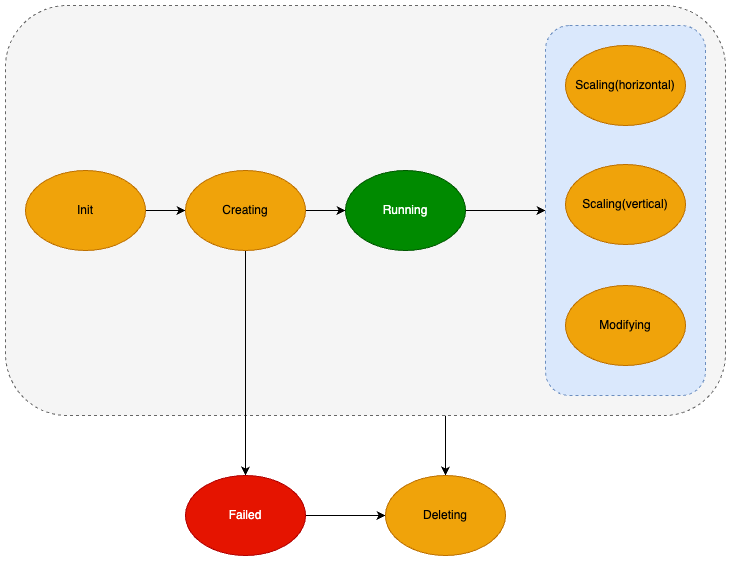 클러스터 모드를 사용할 경우의 클러스터/샤드/노드 생명 주기 다이어그램
클러스터 모드를 사용할 경우의 클러스터/샤드/노드 생명 주기 다이어그램
| 상태 | 설명 |
|---|---|
Init | 클러스터 생성 초기 상태로 생성 시작 전의 상태 |
Creating | 자원 생성 중 |
Running | 동작 중 |
Scaling(horizontal) | 샤드 추가/삭제, 노드 추가/삭제가 진행 중 |
Scaling(vertical) | 노드의 Flavor 변경이 진행 중 |
Modifying | 클러스터의 보안 그룹 변경 작업 진행 중 |
Deleting | 자원 삭제 중 |
Failed | 영구적인 오류 발생으로 인한 비정상 상태이며, 정상 상태로 복귀할 수 없으며 삭제만 가능 |
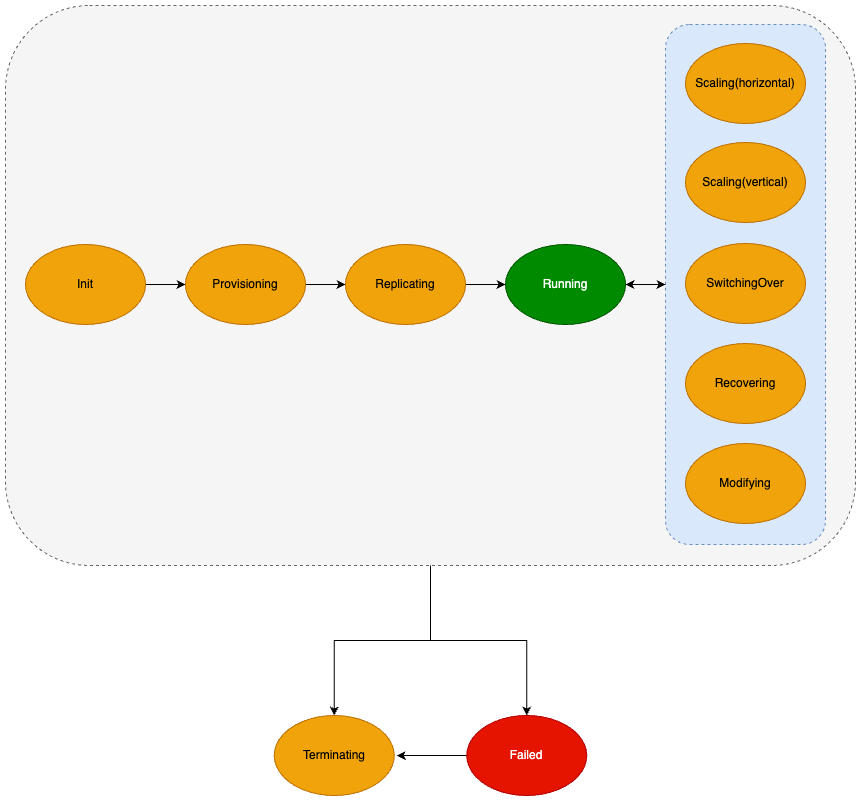 클러스터 모드를 사용하지 않을 경우의 생명 주기 다이어그램
클러스터 모드를 사용하지 않을 경우의 생명 주기 다이어그램
| 상태 | 설명 |
|---|---|
Init | 클러스터를 생성한 직후의 상태 |
Provisioning | 클러스터에 포함된 모든 노드가 필요한 리소스를 준비 중 |
Replicating | 클러스터에 포함된 노드의 역할을 구성하고 엔드포인트 생성 중 |
Running | 서비스가 정상적으로 구성 및 기동이 완료되어 접속 가능 |
Scaling(horizontal) | 새로운 노드를 생성하거나, 특정 Replica 노드의 삭제가 진행 중 |
Scaling(vertical) | 노드의 Flavor 변경이 진행 중 |
SwitchingOver | 특정 Replica 노드를 Primary 노드로 승격 진행 중 |
ScalingOut | 새로운 노드를 생성하고, Replica 역할 부여 중 |
Recovering | 고가용성 기능을 사용하는 클러스터의 노드 장애 발생 시, 자동으로 알맞은 조치를 취하고 있는 상태 |
Modifying | 클러스터의 보안 그룹 변경 작업 진행 중 |
Terminating | 클러스터의 삭제 처리 중 |
Terminated | 클러스터의 삭제 완료 |
Warning | 특정 상태에서 일시적인 오류가 발생한 상태로 문제 해소 시 정상 상태로 복귀 가능 |
Failed | 영구적인 오류 발생으로 인한 비정상 상태이며, 정상 상태로 복귀할 수 없으며 삭제만 가능 |
샤드
샤드는 클러스터 모드를 사용하는 노드의 그룹으로, 클러스터의 데이터를 각각의 샤드에 분할하여 할당합니다.
최소 1개에서 최대 12개의 샤드로 클러스터를 구성할 수 있으며, 클러스터 모드를 사용할 때의 각 샤드는 최소 2개에서 최대 5개의 노드로 구성할 수 있습니다.
클러스터 모드를 사용하는 클러스터의 샤드와 노드 관리 방법은 샤드 및 노드 관리를 참고해 주세요.
노드
노드는 클러스터에 포함된 VM(Virtual Machine)입니다. 노드 생성 및 삭제 시, 필요한 작업을 수행하며 상태를 자동으로 변경합니다. 클러스터에 속한 각 노드는 Primary 역할 또는 Replica 역할을 부여받습니다. 클러스터 모드를 사용하지 않는 경우, 최대 6개의 노드를 구성할 수 있습니다.
클러스터 모드를 사용하지 않는 클러스터의 노드 관리 방법은 노드 관리를, 노드 유형 변경 방법은 노드 유형 변경을 참고해 주세요.
| 역할 | 설명 |
|---|---|
| Primary | 사용자가 일반적으로 사용하는 읽기/쓰기 목적의 노드 |
| Replica | Primary의 부하를 줄이기 위한 읽기 전용의 노드 |
노드 유형
사용자는 노드 생성 시 데이터의 크기 및 부하를 고려하여 유형을 선택할 수 있습니다. 추후 더 다양하고 특화된 노드 유형을 지원할 예정입니다.
| 노드 유형 | vCPU (개) | Memory(GB) |
|---|---|---|
m2a.large | 2 | 8 |
m2a.xlarge | 4 | 16 |
m2a.2xlarge | 8 | 32 |
m2a.4xlarge | 16 | 64 |
m2a.8xlarge | 32 | 128 |
m2a.12xlarge | 48 | 192 |
m2a.16xlarge | 64 | 256 |
m2a.24xlarge | 96 | 384 |
r2a.large | 2 | 16 |
r2a.xlarge | 4 | 32 |
r2a.2xlarge | 8 | 64 |
r2a.4xlarge | 16 | 128 |
r2a.8xlarge | 32 | 256 |
r2a.12xlarge | 48 | 384 |
r2a.16xlarge | 64 | 512 |
r2a.24xlarge | 96 | 768 |
t1i.small | 2 | 2 |
t1i.medium | 2 | 4 |
t1i.large | 2 | 8 |
t1i.xlarge | 4 | 16 |
t1i.2xlarge | 8 | 32 |
t1i 인스턴스 유형은 최초 생성 후 Running 상태로 전환되는 데 수 분에서 수십 분이 소요될 수 있습니다.
CPU 크레딧 잔여량이 부족할 경우 CPU 부하가 있는 작업이 정상 동작하지 않을 수 있습니다.
노드 생명 주기 및 상태 값
노드의 생명 주기와 상태 값은 다음과 같습니다.
-
클러스터 모드를 사용할 경우
- 노드는 클러스터와 동일한 생명 주기를 가집니다. 클러스터 생명 주기 및 상태 값을 참고해 주세요.
-
클러스터 모드를 사용하지 않을 경우
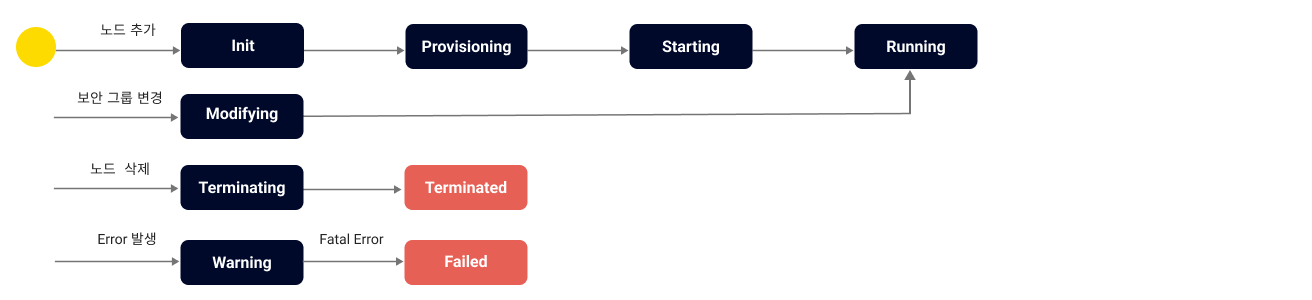 노드 생명 주기 다이어그램
노드 생명 주기 다이어그램
| 상태 | 설명 |
|---|---|
Init | 클러스터 생성 시 설정한 각 노드가 생성을 시작하는 상태 |
Provisioning | 서비스를 기동할 운영 서버 생성을 시작한 상태 - 해당 단계에서 수 분이 소요될 수 있음 |
Starting | 운영 서버 생성 완료 후, 서비스의 설치와 기동을 기다림 |
Running | 서비스가 정상적으로 가동되어 접속 가능 상태 |
Modifying | 보안 그룹 변경 작업 진행 중 |
Terminating | 사용자가 노드 삭제를 요청하여 노드 삭제 중 |
Terminated | 노드가 삭제된 상태 - Terminated 상태가 되면 사용자는 해당 노드 관련 정보를 더 이상 조회 불가 |
Warning | 특정 상태에서 일시적인 오류가 발생한 상태 - 문제 해소 시 정상 상태로 복귀 가능 |
Failed | 영구적인 오류 발생으로 인한 비정상 상태 - 정상 상태로 복귀할 수 없으며 삭제만 가능 |
고가용성
MemStore 서비스는 사용자 편의성과 안정적인 운영을 위해 고가용성 기능을 제공합니다. 고가용성 기능을 사용하면, 노드 장애 시 자동으로 조치하여 서비스를 지속할 수 있는 환경을 제공합니다.
사용자는 클러스터 생성 시 클러스터 모드를 사용할 경우에는 고가용성을 기본으로 사용하게 되며 사용 여부를 변경할 수 없습니다. 클러스터 모드를 사용하지 않을 경우, 클러스터 생성 시 고가용성 기능 사용 여부를 선택할 수 있고, 운영 중에도 해당 기능의 사용 여부를 변경할 수 있습니다. 클러스터의 상세 정보 탭에서 클러스터의 고가용성 사용 여부를 확인할 수 있습니다. 고가용성 기능을 사용하는 경우에도 사용자는 노드를 추가 또는 삭제할 수 있으며, 추가된 노드는 고가용성 범위에 자동으로 포함됩니다.
고가용성 설정 방법은 고가용성 설정을 참고해 주세요.
노드 장애
노드의 역할에 따라 아래와 같은 방식으로 노드 장애를 해결합니다.
| 구분 | 설명 |
|---|---|
| Primary 노드 장애 | Primary 노드 장애 시 자동으로 가장 최신의 데이터를 보유한 Replica 노드를 선택하여 Primary로 승격(Automatic Failover)하며 새로운 Replica 노드를 생성하여 Replica 개수를 유지함(Auto Healing) |
| Replica 노드 장애 | Replica 노드 장애 시, 자동으로 새로운 노드로 대체하여 Replica 개수를 유지함 |
승격
클러스터 모드 또는 고가용성 기능을 사용하는 경우에는 사용자가 승격을 요청할 수 없고, 노드 장애 상황에 따라 서비스에서 필요하다고 판단할 때 자동으로 승격을 수행합니다. 고가용성 기능을 사용하지 않는 경우에는 수동 승격 기능을 제공합니다. Primary 노드에 장애가 발생할 경우, 사용자는 승격 기능을 통해 Replica 노드를 Primary 노드로 승격할 수 있습니다.
노드 승격 방법은 노드 승격을 참고해 주세요.
엔드포인트
클러스터 생성 시 클라이언트가 접속할 수 있는 읽기 전용인 Read 엔드포인트를 제공합니다.
해당 주소는 사용자가 선택한 사설 네트워크(서브넷)에서 접속 가능하며, 접근 권한 및 보안 설정까지 자동으로 처리되어 안전합니다.
클러스터 연결 방법은 MemStore 클러스터 연결을 참고해 주세요.
클러스터 모드를 사용할 경우에는 Read 엔드포인트를 제공하지 않으며, 각 노드의 엔드포인트를 통해 접속할 수 있습니다.
백업
생성된 클러스터 정보를 백업하여 복원에 사용할 수 있습니다.
백업 조회와 관리 방법은 백업 관리를 참고해 주세요.
백업 상태 값
| 상태 | 설명 |
|---|---|
Available | 백업이 완료되어 복원, 복사, 내보내기를 할 수 있는 상태 |
Pending | 백업 요청은 받아들여졌으나 시작하지 않은 상태 |
Creating | 백업을 수행 중이거나 원본 백업으로부터 새 백업이 복사되고 있는 상태 |
Restoring | 프로비저닝에 사용되고 있는 상태 |
Copying | 다른 백업을 만들기 위해 복사되고 있는 상태 |
Exporting | 사용자의 Object Storage로 내보내고 있는 상태 |
Error | 백업 중 오류가 발생한 상태 |
Deleting | 백업을 삭제 중인 상태 |
파라미터 그룹
MemStore의 파라미터 값을 그룹 단위로 생성하고 관리할 수 있습니다.
파라미터 그룹 생성과 수정 방법은 파라미터 그룹 관리를, 클러스터에 적용된 파라미터 그룹을 변경하는 방법은 파라미터 그룹 변경을 참고해 주세요.
파라미터 반영 상태
| 상태 값 | 설명 |
|---|---|
Pending | 파라미터 반영을 대기하는 상태 |
Applying | 클러스터에 파라미터를 반영 중인 상태 |
In-Sync | 클러스터에 파라미터가 정상 반영된 상태 |
Error-Sync | 클러스터에 파라미터 반영을 실패한 상태 - 파라미터 반영을 재시도할 수 있으며, 재시도 시 Applying 상태로 변경 |
Suspended | 순차 반영 시 앞 순서의 클러스터가 파라미터 반영에 실패하여 다음 작업을 대기하는 상태 - Pending에서 Suspended로 상태가 변경되면 파라미터 반영을 재시도할 수 있음- 재시도 시 Applying 상태로 변경 |