Hadoop Eco 스케줄링을 이용한 적재된 웹 서버 로그 분석
Hadoop Eco 스케줄링 기능으로 Object Storage에 적재되는 로그를 주기적으로 분석하는 작업을 자동화합니다.
- 예상 소요 시간: 60분
- 권장 운영 체제: macOS, Ubuntu
- 사전 준비 사항
- 참고 문서
시나리오 소개
이 시나리오에서는 Hadoop Eco의 분산 처리 및 스케줄링 기능을 활용하여 Object Storage에 저장된 웹 서버 로그를 정기적으로 분석하는 방법을 설명합니다. 이 자동화된 로그 분석 프로세스를 통해 사용자는 로그 데이터를 효율적으로 처리하고, 주기적인 분석 작업을 손쉽게 관리할 수 있습니다.
시작하기
아래 실습 단계에서는 Object Storage에 업로드된 로그 파일 확인, Hadoop Eco를 활용한 데이터 처리, 그리고 스케줄링 작업 자동화까지의 전체 과정을 다룹니다. 이 튜토리얼을 통해 로그 데이터를 저장, 관리, 처리하는 방법과 최종적으로 자동화된 스케줄링 작업을 설정하는 방법을 학습할 수 있습니다.
Step 1. Object Storage에 업로드된 로그 파일 확인하기
문서에 따라 핸즈온 진행에 필요한 로그 파일 예제를 생성합니다. Hadoop Eco 서비스를 이용한 웹 서버 로그 분석 튜토리얼을 먼저 진행한 뒤, Object Storage에 예제 로그 파일이 정상적으로 업로드되었는지 확인합니다.
⚠️ 사전 튜토리얼에서 생성한 예제 로그 파일의 업로드 경로(
/log/nginx/...)와 이 문서의 예제 경로(/nginx/ori/...)가 다를 수 있습니다. 실습 전 사용 중인 Object Storage 경로를 확인하고 일관되게 설정해 주세요.
Step 2. Data Catalog 리소스 생성
Data Catalog는 카카오클라우드 내 조직과 사용자 데이터 자산을 파악하고 효율적으로 관리할 수 있도록 도와주는 완전 관리형 서비스입니다. 이 단계에서는 Data Catalog를 구성하는 Catalog, Database, Table을 생성해야 합니다.
-
Catalog는 VPC 내 완전 관리형 중앙 리포지토리로, Data Catalog 서비스를 이용하기 위해 먼저 Catalog를 생성합니다.
항목 설정값 이름 hands_on VPC ${any}서브넷 ${public} -
생성한 카탈로그의 상태가 Running이 되면 Database를 생성합니다. Data Catalog의 데이터베이스는 테이블을 저장하는 컨테이너입니다.
항목 설정값 카탈로그 hands_on 이름 hands_on_db 경로:버킷 tutorial 경로:디렉터리 nginx -
Data Catalog의 메타데이터인 Table을 생성합니다.
- 오리진 데이터 테이블
- 스키마
항목 설정값 데이터베이스 hands_on_db 테이블 이름 tutorial_log_original 데이터 저장 경로: 버킷 이름 tutorial 데이터 저장 경로: 디렉터리 nginx/ori 데이터 유형 CSV 파티션 키 칼럼 번호 필드 이름 데이터 유형 off 1 log string on - date_id string on - hour_id string
Step 3. Hadoop Eco 리소스 생성
Hadoop Eco는 오픈소스 프레임워크를 이용하여 분산 처리 작업을 실행하기 위한 카카오클라우드 서비스입니다. Hadoop Eco 리소스를 생성하는 방법은 다음과 같습니다.
-
카카오클라우드 콘솔 > Analytics > Hadoop Eco로 이동합니다. [클러스터 생성] 버튼을 클릭한 뒤 아래 정보에 해당하는 클러스터를 생성합니다.
항목 설정값 클러스터 이름 tutorial 클러스터 버전 Hadoop Eco 2.0.0 클러스터 유형 Core Hadoop 클러스터 가용성 표준 관리자 ID ${ADMIN_ID}관리자 비밀번호 ${ADMIN_PASSWORD} -
키 페어 및 네트워크 구성(VPC, 서브넷)은 사용자가 ssh 접속을 진행할 수 있는 환경에 맞게 설정합니다. 다음으로
새로운 보안 그룹 생성을 선택합니다.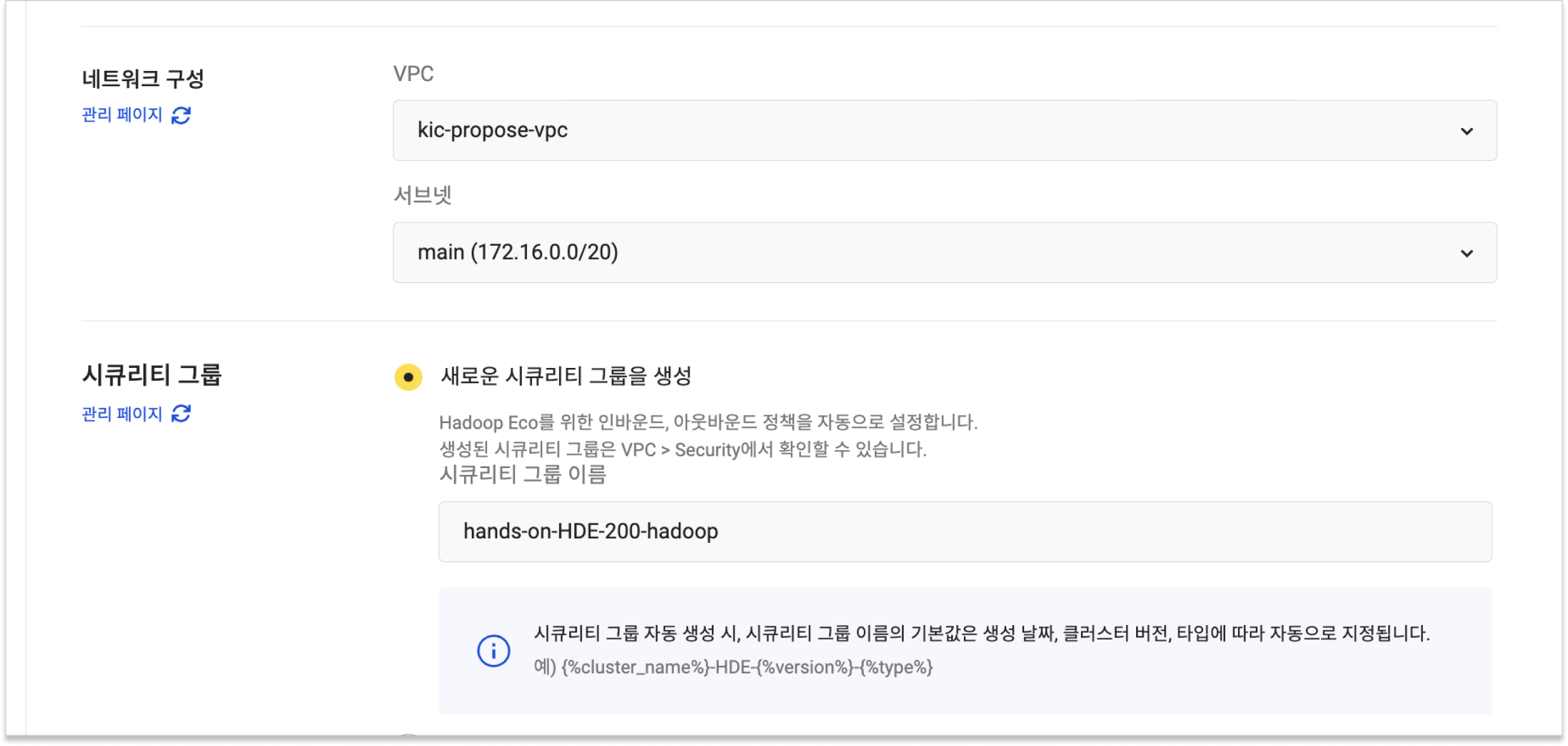
-
마스터 노드와 워커 노드 인스턴스를 설정합니다.
구분 마스터 노드 워커 노드 인스턴스 개수 1개 2개 인스턴스 유형 m2a.xlarge m2a.xlarge 볼륨 크기 50GB 100GB -
모니터링 에이전트, Data Catalog 서비스 연동 등을 설정합니다.
항목 설명 모니터링 에이전트 설치 설치 안함 서비스 연동 Data Catalog 연동 Data Catalog 이름 [hands_on]에서 생성한 [hands_on] 선택 -
클러스터를 아래 조건에 맞게 설정합니다.
항목 설정값 HDFS 블록 크기 128 HDFS 복제 개수 2 클러스터 구성 설정 [직접 입력] 선택 후 아래 코드 입력 클러스터 구성 설정값 - Object Storage 연동{
"configurations": [
{
"classification": "core-site",
"properties": {
"fs.swifta.service.kic.credential.id": "${ACCESS_KEY}",
"fs.swifta.service.kic.credential.secret": "${ACCESS_SECRET_KEY}"
}
}
]
} -
스케줄링 설정을 열고 Hive를 선택한 다음 쿼리를 입력합니다. 쿼리는 nginx 기본 포맷 로그를 정제하고 사용자 요청을 연산하여 결과를 저장합니다.
-- Hive 설정: 동적 파티션 모드 변경
SET hive.exec.dynamic.partition.mode=nonstrict;
-- Database 선택
USE hands_on_db;
-- 테이블 복구
MSCK REPAIR TABLE tutorial_log_original;
-- refined_json 테이블 생성
CREATE EXTERNAL TABLE IF NOT EXISTS refined_json (
remote_addr STRING,
request_method STRING,
request_url STRING,
status STRING,
request_time STRING,
day_time STRING)
PARTITIONED BY (date_id STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
STORED AS TEXTFILE;
-- refined_json 데이터 삽입
INSERT INTO refined_json PARTITION (date_id)
SELECT
split(log, ' ')[0] AS remote_addr,
split(log, ' ')[5] AS request_method,
split(log, ' ')[6] AS request_url,
split(log, ' ')[8] AS status,
split(log, ' ')[9] AS request_time,
regexp_extract(split(log, ' ')[3], '\\d{2}:\\d{2}:\\d{2}', 0) AS day_time,
date_id
FROM
tutorial_log_original;
-- JsonSerDe를 사용하여 JSON 형식의 빈 urlcount 테이블 생성
CREATE EXTERNAL TABLE IF NOT EXISTS urlcount (
request_url STRING,
status STRING,
count BIGINT)
PARTITIONED BY (date_id STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
STORED AS TEXTFILE;
-- urlcount 테이블에 데이터 적재
INSERT INTO urlcount PARTITION (date_id)
SELECT
request_url,
status,
count(*) AS count,
date_id
FROM
refined_json
GROUP BY
request_url,
status,
date_id; -
입력한 정보를 확인한 뒤 클러스터를 생성합니다.
Step 4. Hadoop Eco 스케줄링 크론잡 설정
-
크론잡을 실행할 가상머신을 생성합니다.
Type Virtual Machine Quantity 1 Name cron-vm Image Ubuntu 20.04 Flavor m2a.large Volume 20 안내크론잡을 수행할 인스턴스는 외부 네트워크에 요청을 보냅니다. 따라서 외부 네트워크에 요청을 주고받을 수 있는 보안 그룹 및 네트워크 환경 설정이 필요합니다.
-
크론잡을 수행할 인스턴스에 ssh를 통해 접속합니다. 퍼블릭 IP를 추가하거나 Bastion 호스트 등을 사용하여 ssh 접속을 시도할 수 있습니다.
ssh -i ${PRIVATE_KEY}.pem ubuntu@${CRON_VM_ENDPOINT} -
shell에서 json 포맷의 데이터를 쉽게 사용하기 위해 jq 패키지를 설치합니다.sudo apt-get update -y
sudo apt-get install -y jq -
SSH를 통해 인스턴스에 접속한 다음, 로그를 적재할 환경 변수 파일을 아래 표를 참조하여 작성합니다. 클러스터 ID는 클러스터의 상세 정보에서 확인할 수 있습니다.
Create env filecat << \EOF | sudo tee /tmp/env.sh
#!/bin/bash
export CLUSTER_ID="${CLUSTER_ID}"
export HADOOP_API_KEY="${HADOOP_API_KEY}"
export ACCESS_KEY="${ACCESS_KEY}"
export ACCESS_SECRET_KEY="${ACCESS_SECRET_KEY}"
EOF환경 변수 키 환경 변수 값 CLUSTER_ID🖌︎ 클러스터 ID HADOOP_API_KEY🖌︎ 하둡 API 키 ACCESS_KEY🖌︎ 액세스 키 ACCESS_SECRET_KEY🖌︎ 사용자 보안 액세스 키
-
환경 변수 파일의 정보를 이용하여 클러스터 생성을 요청하는 스크립트를 작성합니다. 하둡 클러스터 API와 관련된 자세한 정보는 Hadoop Eco API를 확인하세요.
cat << \EOF | sudo tee /tmp/exec_hadoop.sh
#!/bin/bash
. /tmp/env.sh
curl -X POST "https://hadoop-eco.kr-central-2.kakaocloud.com/v2/hadoop-eco/clusters/${CLUSTER_ID}" \
-H "Hadoop-Eco-Api-Key:${HADOOP_API_KEY}" \
-H "Credential-ID:${ACCESS_KEY}" \
-H "Credential-Secret:${ACCESS_SECRET_KEY}" \
-H "Content-Type: application/json"
EOF -
일정 시간마다 자동으로 스크립트를 실행하기 위해 cron 패키지를 사용합니다.
sudo apt update -y
sudo apt install -y cron -
Crontab에 작성했던 하둡 클러스터를 생성하는 스크립트를 매일 자정에 실행하는 명령을 작성합니다.
cat << EOF > tmp_crontab
0 0 * * * /bin/bash /tmp/exec_hadoop.sh
EOF
sudo crontab tmp_crontab
rm tmp_crontab -
크론 작업이 등록되었는지 확인합니다.
sudo crontab -l -
아래 명령을 실행하고 클러스터가 생성되었는지 확인합니다.
bash /tmp/exec_hadoop.sh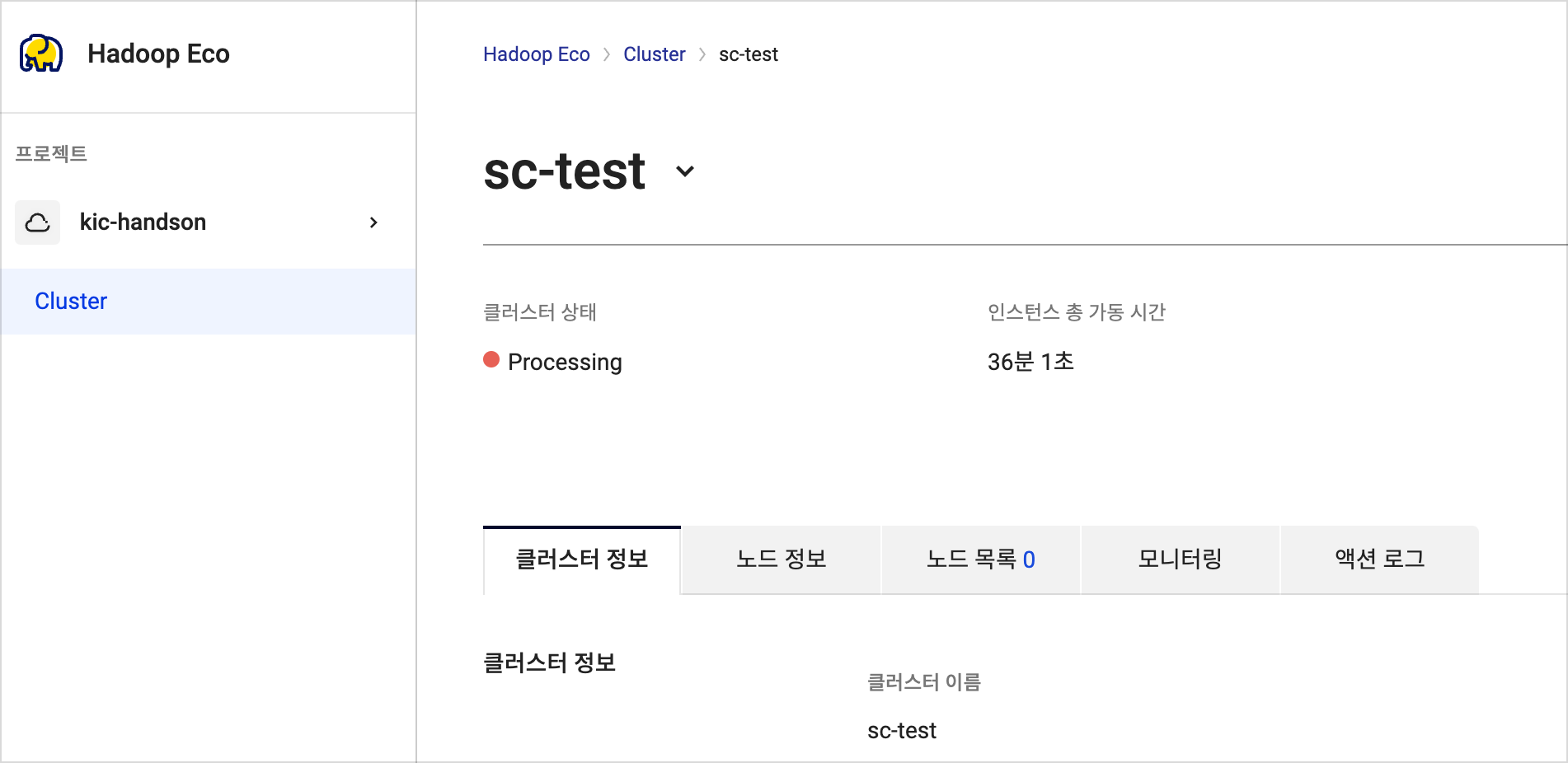
-
클러스터의 작업 결과를 확인합니다. 결과 로그는 하둡 클러스터 생성 단계에서 설정한 Object Storage의 버킷에서 확인합니다.
-
Object Storage에서 선택한 버킷과 log 디렉터리 내에 저장된 작업 결과를 확인합니다.