비디오 트랜스코딩 인스턴스의 성능 테스트
카카오클라우드의 비디오 트랜스코딩 인스턴스 유형인
vt1a를 사용하여 효율적으로 비디오를 트랜스코딩하는 방법을 설명합니다.
- 예상 소요 시간: 30 ~ 60분
- 권장 운영 체제: Ubuntu
- 사전 준비 사항
시나리오 소개
카카오클라우드는 실시간 비디오 트랜스코딩 작업 수행 시 뛰어난 성능을 제공하도록 설계된 인스턴스 유형 중 하나로 vt1a 인스턴스를 제공합니다. 이 시나리오에서는 vt1a 인스턴스를 활용하여 비디오 트랜스코딩을 효율적으로 수행하는 방법을 설명합니다. 또한, 다른 인스턴스 유형에서 실행한 결과와 비교하여, 비디오 트랜스코딩에 특화된 vt1a 인스턴스의 성능 및 장점을 설명합니다.
시작하기 전에
사전 작업으로 VPC와 서브넷, 보안 그룹을 설정합니다.
1. VPC 및 서브넷 생성
인스턴스를 생성하기 전, 인스턴스가 생성될 VPC 및 서브넷을 생성해야 합니다. VPC와 서브넷이 없다면, VPC 생성, 서브넷 생성 문서를 참고하여 VPC 및 서브넷을 생성합니다.
2. 보안 그룹 설정
인스턴스 레벨에서 높은 보안을 확보하기 위해 보안 그룹을 생성하고, 적절한 인바운드 규칙을 추가해야 합니다. 보안 그룹 생성 문서를 참고하여 보안 그룹을 생성하고 인바운드 규칙에 아래의 규칙을 추가합니다.
다음 버튼을 클릭하면 현재 사용 중인 나의 퍼블릭 IP를 확인할 수 있습니다.
| 프로토콜 | 출발지 | 포트 번호 | 규칙 설명 |
|---|---|---|---|
| TCP | {사용자 퍼블릭 IP}/32 | 22 | 로컬 PC에서 이 보안 그룹에 연결된 인스턴스에 SSH 접근을 허용 |
시작하기
vt1a 인스턴스를 활용하는 세부 작업은 다음과 같습니다.
Step 1. 인스턴스 생성
-
카카오클라우드 콘솔에서 Beyond Compute Service의 Virtual Machine 메뉴를 선택합니다.
-
인스턴스 메뉴로 이동 후, [인스턴스 생성] 버튼을 클릭합니다.
-
아래와 같이
vt1a인스턴스를 생성합니다. 본 예제에서는vt1a.4xlarge를 사용합니다.항목 설정값 기본 정보 - 이름: 사용자 지정
- 개수: 1개이미지 기본 탭에서 Ubuntu 22.04 선택
- 하단의 SDK 지원 운영체제 정보 참고인스턴스 유형 vt1a.4xlarge볼륨 - 루트 볼륨: 기본값 유지 키 페어 사전 작업에서 미리 생성한 키 페어 선택 네트워크 - VPC: 사전 작업에서 미리 생성한 VPC 선택
- 서브넷: 사전 작업에서 미리 생성한 서브넷 선택
- 보안 그룹: 사전 작업에서 미리 생성한 보안 그룹 선택
2024년 기준 최신 버전인 Xilinx Video SDK 3.0가 정상적으로 작동되는 검증된 운영체제 및 커널 버전은 아래와 같습니다.
- Ubuntu 22.04(Kernel 5.15)
- Ubuntu 20.04.4 (Kernel 5.13)
- Ubuntu 20.04.3 (Kernel 5.11)
- Ubuntu 20.04.1 (Kernel 5.4)
- Ubuntu 20.04.0 (Kernel 5.4)
- Ubuntu 18.04.5 (Kernel 5.4)
Step 2. 퍼블릭 IP 연결
앞서 생성한 인스턴스 각각에 퍼블릭 IP를 할당 및 연결하여 SSH 접근이 가능하도록 설정합니다.
-
카카오클라우드 콘솔에서 Beyond Compute Service의 Virtual Machine 메뉴를 선택합니다.
-
인스턴스 메뉴로 이동 후, 생성한 인스턴스의 [⋮] 버튼 > 퍼블릭 IP 연결을 선택합니다.
- 필요에 따라 퍼블릭 IP 생성 및 관리을 참고하여 퍼블릭 IP를 생성한 후, 퍼블릭 IP 할당 방식을 선택합니다.
-
[확인] 버튼을 선택하여 퍼블릭 IP 연결 작업을 완료합니다. 각각의 인스턴스에서 동일하게 작업합니다.
Step 3. SSH 연결
인스턴스에 Xilinx Video SDK를 설치하기 위해 SSH로 연결 및 접근이 필요합니다. 이 작업 과정을 설명합니다.
-
카카오클라우드 콘솔에서 Beyond Compute Service의 Virtual Machine 메뉴를 선택합니다.
-
인스턴스 메뉴로 이동 후, 생성한 인스턴스의 [⋮] 버튼 > SSH 연결을 선택하여 SSH 연결을 위한 명령어 및 설정 등을 확인합니다.
-
로컬 PC에서 아래의 SSH 연결을 위한 명령어를 입력하여 각 인스턴스에 SSH 연결을 시도합니다. SSH 연결에 대한 자세한 설명은 인스턴스 연결을 참고하시기 바랍니다.
ssh -i ${key-pair-name}.pem ubuntu@${public-ip-addr}매개변수 설명 key-pair-name 인스턴스 생성 시 지정한 키 페어에 대한 프라이빗 키 파일명 public-ip-addr 인스턴스에 할당 및 연결된 퍼블릭 IP 주소
Step 4. Xilinx Video SDK 설치
Xilinx Video SDK는 사용자가 Xilinx 비디오 코덱 유닛의 하드웨어 가속 기능을 원활하게 활용하여 라이브 스트리밍 비디오와 같은 고밀도 실시간 비디오 트랜스코딩을 지원하기 위한 소프트웨어 스택입니다. 이 SDK에는 Xilinx 디바이스용 비디오 트랜스코딩 플러그인을 통합하는 사전 컴파일 버전의 FFmpeg 및 GStreamer가 포함되어 있으며, 이를 통해 비디오 인코딩 및 디코딩, 비디오 업스케일링을 포함한 하드웨어 가속화를 지원합니다.
비디오 트랜스코딩 예제를 실행하기 전 Xilinx Video SDK의 설치가 필요하며, Xilinx Video SDK 설치 가이드를 따라 설치를 진행합니다.
Step 5. 런타임 환경 설정
런타임 환경 설정을 참고하여 런타임 환경 설정을 완료합니다.
이제 예제를 실행할 수 있는 환경 구성이 완료되었습니다.
Step 6. 예제 실행
예제 1. 다중 디바이스로 ABR(Adaptive Bit Rate) 트랜스코딩 예제
vt1a 인스턴스에서 지원하는 Alveo U30 가속기 카드의 가속 H.264/AVC 및 H.265/HEVC 코덱은 이전 세대 모바일 핸드셋부터 초고해상도 디스플레이가 탑재된 최신 세대 핸드셋에 이르기까지, 광범위한 최종 사용자 디바이스에서 효율적으로 디코딩할 수 있는 SDR(8비트) 및 HDR(10비트) 프로파일을 지원합니다.
이 U30 가속기 카드에는 카드당 2개씩 Xilinx 디바이스가 설정되어 있습니다. vt1a.4xlarge, vt1a.8xlarge, vt1a.32xlarge 각각 1, 2, 8개의 U30 가속기 카드가 있으며, 따라서 디바이스 수는 각각 2, 4, 16개입니다. 디바이스 1개당 트랜스코딩 가능한 스트림 개수는 다음과 같습니다.
| 해상도 | 비트레이트 | 스트림 개수 |
|---|---|---|
| 4K | 60fps | 1 |
| 1080p | 60fps | 4 |
| 1080p | 30fps | 8 |
| 720p | 30fps | 16 |
본 예제는 해상도가 4K이고 비트레이트가 60fps인 H.264 샘플 파일을 ABR Ladder 트랜스코딩하는 작업을 수행합니다. 이때, 처리하는 스트림 개수는 디바이스 1개가 처리할 수 있는 스트림 개수를 초과하므로(위 표 참고) 2개의 디바이스를 사용합니다.
참고 해당 예제는 Xilinx에서 제공하는 튜토리얼의 일부로, 자세한 사항과 더 많은 예제는 Xilinx Video SDK Tutorials and Examples에서 확인 가능합니다.
예제 ffmpeg 파이프라인 코드
4k 해상도의 H.264 인풋파일을 7개의 다른 해상도와 다른 비트레이트의 H.265(HEVC)파일로 트랜스코딩하는 ffmpeg 파이프라인을 실행합니다. 작업은 2개의 디바이스(device#0, device#1)에서 실행되는데, device#0에서는 인풋 파일을 가속화 디코딩 후 1080p로 스케일링하고 이를 host와 device#1에 차례로 복사합니다. 이어서 device#0에서 기존 인풋 파일을 해상도가 4k이고 비트레이트가 16M인 H.265(HEVC) 파일로 인코딩합니다. device#1에서는 device#0에서 복사된 1080p 파일을 6개의 다른 해상도와 다른 비트레이트의 H.265(HEVC) 파일로 인코딩합니다. 예제 파이프라인에서 입력 파일로 사용하는 파일은 아래의 링크에서 다운로드할 수 있습니다.
source /opt/xilinx/xcdr/setup.sh
INPUT_FILE=sample_60sec_3840x2160_60fps_h264.mp4
ffmpeg -hide_banner -c:v mpsoc_vcu_h264 -lxlnx_hwdev 0 \
-i ${INPUT_FILE} \
-max_muxing_queue_size 1024 \
-filter_complex "[0]split=2[dec1][dec2]; \
[dec2]multiscale_xma=outputs=1:lxlnx_hwdev=0:out_1_width=1920:out_1_height=1080:out_1_rate=full[scal]; \
[scal]xvbm_convert[host]; [host]split=2[scl1][scl2]; \
[scl2]multiscale_xma=outputs=4:lxlnx_hwdev=1:out_1_width=1280:out_1_height=720:out_1_rate=full:
out_2_width=848:out_2_height=480:out_2_rate=half: \
out_3_width=640:out_3_height=360:out_3_rate=half: \
out_4_width=280:out_4_height=160:out_4_rate=half \
[a][b30][c30][d30]; [a]split[a60][aa];[aa]fps=30[a30]" \
-map '[dec1]' -c:v mpsoc_vcu_hevc -b:v 16M -max-bitrate 16M -lxlnx_hwdev 0 -slices 4 -cores 4 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_4k.mp4 \
-map '[scl1]' -c:v mpsoc_vcu_hevc -b:v 6M -max-bitrate 6M -lxlnx_hwdev 1 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_1080p60.mp4 \
-map '[a60]' -c:v mpsoc_vcu_hevc -b:v 4M -max-bitrate 4M -lxlnx_hwdev 1 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_720p60.mp4 \
-map '[a30]' -c:v mpsoc_vcu_hevc -b:v 3M -max-bitrate 3M -lxlnx_hwdev 1 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_720p30.mp4 \
-map '[b30]' -c:v mpsoc_vcu_hevc -b:v 2500K -max-bitrate 2500K -lxlnx_hwdev 1 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_480p30.mp4 \
-map '[c30]' -c:v mpsoc_vcu_hevc -b:v 1250K -max-bitrate 1250K -lxlnx_hwdev 1 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_360p30.mp4 \
-map '[d30]' -c:v mpsoc_vcu_hevc -b:v 625K -max-bitrate 625K -lxlnx_hwdev 1 -max_interleave_delta 0 -f mp4 -y /tmp/xil_multidevice_ladder_160p30.mp4
| 매개 변수 | 값 | 설명 |
|---|---|---|
| -i | INPUT_FILE | 인풋 파일 경로. 값은 예제용 샘플 H.264 파일의 경로 및 파일명 - 예: -i $HOME/videos/sample_4kp60fps.h264 |
| -c:v | mpsoc_vcu_h264, mpsoc_vcu_hevc | 사용할 hw 가속화 디코더 또는 인코더 - 값은 H.264용 가속화 디코더/인코더인 mpsoc_vcu_h264와 H.265용 가속화 디코더/인코더인 mpsoc_vcu_hevc |
| -lxlnx_hwdev | 0, 1, ..., n | 사용할 디바이스 번호로, 값은 [0, 카드개수x2 - 1]의 범위만 가능 ⚠️ vt1a 인스턴스 크기에 따른 최대 디바이스 수를 초과하여 입력할 수 없으며, 초과된 값을 입력할 경우 에러가 발생 |
| -b:v | BITRATE_VALUE | 인코딩할 스트림의 타겟 비트레이트 - 예: -b:v 16M |
해당 파이프라인을 실행 시킨 후, 각 디바이스의 사용량은 다음과 같이 확인할 수 있습니다.
source /opt/xilinx/xcdr/setup.sh
check_rsrc_cmd="xrmadm /opt/xilinx/xrm/test/list_cmd.json | grep '(device_[0-1])|(cu_[0-9])|(cuName)|(usedLoad)'"
watch -n 1 $check_rsrc_cmd

예제 2. 다중 스트림 트랜스코딩 작업 성능 확인 및 비교
vt1a 인스턴스는 디바이스의 처리 가능 범위 내에서 동일 속도로 여러 개의 스트림에 대해 트랜스코딩 병렬 처리가 가능합니다.
본 예제에서는 단일 스트림이 아닌 멀티 스트림에 대한 병렬 트랜스코딩 작업 시간과 속도를 측정합니다. 그리고 동일 작업을 일부 GPU 인스턴스 및 VM 인스턴스에서도 동일하게 각각 실행 후 작업 시간을 측정하여 그 결과를 비교합니다.
예제 스크립트 코드
#!/bin/bash
if [[ $# -lt 3 ]]; then
echo "[ERROR] Incorrect arguments supplied."
echo "Usage: $(basename $0) <vt1|cpu|gpu> <input file path(string)> <the number of input(int)> <the number of vt1's device(int)>"
exit 1
fi
INSTANCE_TYPE=$1
INPUT_FILE=$2
INPUT_CNT=$3
INPUT_ARR=$(seq 0 $((INPUT_CNT-1)))
DEV_CNT=$4
INPUT_FILE_INFO=`ffprobe -v error -select_streams v:0 -show_entries stream=codec_name,width,height -of default=noprint_wrappers=1:nokey=1 ${INPUT_FILE}`
INPUT_FILE_INFO=($INPUT_FILE_INFO)
INPUT_FILE_W=${INPUT_FILE_INFO[1]}
INPUT_FILE_H=${INPUT_FILE_INFO[2]}
if [ ${INPUT_FILE_H} == '1080' ]; then
BITRATE="10M"
AVAIL_FILE_CNT=4
else
echo "[ERROR] Incorrect arguments supplied."
echo "given Resolution of Input Video File is NOT 1080p BUT ${INPUT_FILE_W} x ${INPUT_FILE_H}"
exit 1
fi
if [ ${INSTANCE_TYPE} == 'vt1' ]; then
source /opt/xilinx/xcdr/setup.sh
DETECTED_DEV_CNT=`xbutil examine | grep -c xilinx_u30`
if [[ ${DEV_CNT} -gt ${DETECTED_DEV_CNT} ]]; then
echo "[ERROR] Incorrect arguments supplied."
echo "<the number of device(int)> can not be larger than the actual number of devices(${DETECTED_DEV_CNT})"
exit 1
fi
else
DEV_CNT=1
DETECTED_DEV_CNT=1
fi
function init_dev_arr()
{
local device_cnt=$1
local arr_=()
for a in $(seq 0 $device_cnt)
do
arr_[a]=0
done
echo ${arr_[@]}
}
DEV_ARR=($(init_dev_arr $DEV_CNT))
for i in ${INPUT_ARR}
do
OUTPUT_FILE=/tmp/output_hevc_${i}.mp4
LOG_FILE=logs/log${i}.out
rm -rf ${OUTPUT_FILE} ${LOG_FILE}
if [ ${INSTANCE_TYPE} == 'vt1' ]; then
DEV_IDX=$((i % DEV_CNT))
if [[ DEV_ARR[$DEV_IDX] -eq $AVAIL_FILE_CNT ]]; then
echo ">> all device is in use. waiting until devices is available..."
wait
echo
# echo ">> And then, initialize device array"
DEV_ARR=($(init_dev_arr $DEV_CNT))
echo
fi
cmd="nohup ffmpeg -xlnx_hwdev ${DEV_IDX} -c:v mpsoc_vcu_h264 -i ${INPUT_FILE} -hide_banner -c:v mpsoc_vcu_hevc -b:v ${BITRATE} -max-bitrate ${BITRATE} -max_interleave_delta 0 -profile:v main -y -f mp4 ${OUTPUT_FILE} > ${LOG_FILE} 2>&1 &"
echo $cmd
echo
# eval "$cmd"
DEV_ARR[$DEV_IDX]=$((DEV_ARR[$DEV_IDX] + 1))
elif [ ${INSTANCE_TYPE} == 'gpu' ]; then
cmd="nohup ffmpeg -hwaccel cuda -hwaccel_output_format cuda -c:v h264_cuvid -i ${INPUT_FILE} -hide_banner -c:v hevc_nvenc -b:v ${BITRATE} -maxrate ${BITRATE} -max_interleave_delta 0 -profile:v main -preset p4 -y -f mp4 ${OUTPUT_FILE} > ${LOG_FILE} 2>&1 &"
echo $cmd
echo
# eval "$cmd"
else
N_THREADS=5
cmd="nohup ffmpeg -c:v h264 -i ${INPUT_FILE} -f mp4 -c:v libx265 -b:v ${BITRATE} -maxrate ${BITRATE} -threads ${N_THREADS} -max_interleave_delta 0 -profile:v main -preset faster -y -f mp4 ${OUTPUT_FILE} > ${LOG_FILE} 2>&1 &"
echo $cmd
echo
# eval "$cmd"
fi
done
wait
echo
echo "All Done."
위 코드를 multistream.sh로 저장하고, 아래 명령어 형태를 따라 인스턴스 유형별로 다중 스트림 개수를 32개까지 증가시키며 총 작업 시간을 측정합니다.
N_STREAM_ARR=$(seq 1 32)
for N_STREAM in ${N_STREAM_ARR}
do
# vt1
N_DEVICE=1
time bash multistream.sh vt1 sample_60sec_1920x1080_60fps_h264.mp4 ${N_STREAM} ${N_DEVICE}
# gpu
time bash multistream.sh gpu sample_60sec_1920x1080_60fps_h264.mp4 ${N_STREAM}
# cpu
time bash multistream.sh cpu sample_60sec_1920x1080_60fps_h264.mp4 ${N_STREAM}
wait
done
| 매개변수 | 값 | 설명 |
|---|---|---|
| INSTANCE_TYPE | vt1, cpu, gpu | 작업할 인스턴스 유형 |
| INPUT_FILE | ample_60sec_1920x1080_60fps_h264.mp4 | 작업할 인풋 비디오 파일 |
| INPUT_CNT | [1, 32] | 총 스트림 개수 = 작업할 INPUT_FILE 개수 |
| DEV_CNT | [1, 2] | vt1a 인스턴스에서 작업 시, 사용할 디바이스 개수 |
본 예제에서 gpu는 gn1i 인스턴스 유형, cpu는 c2a 인스턴스 유형이 해당되며, 결과를 그래프로 나타냈을 때 아래와 같이 나타납니다.
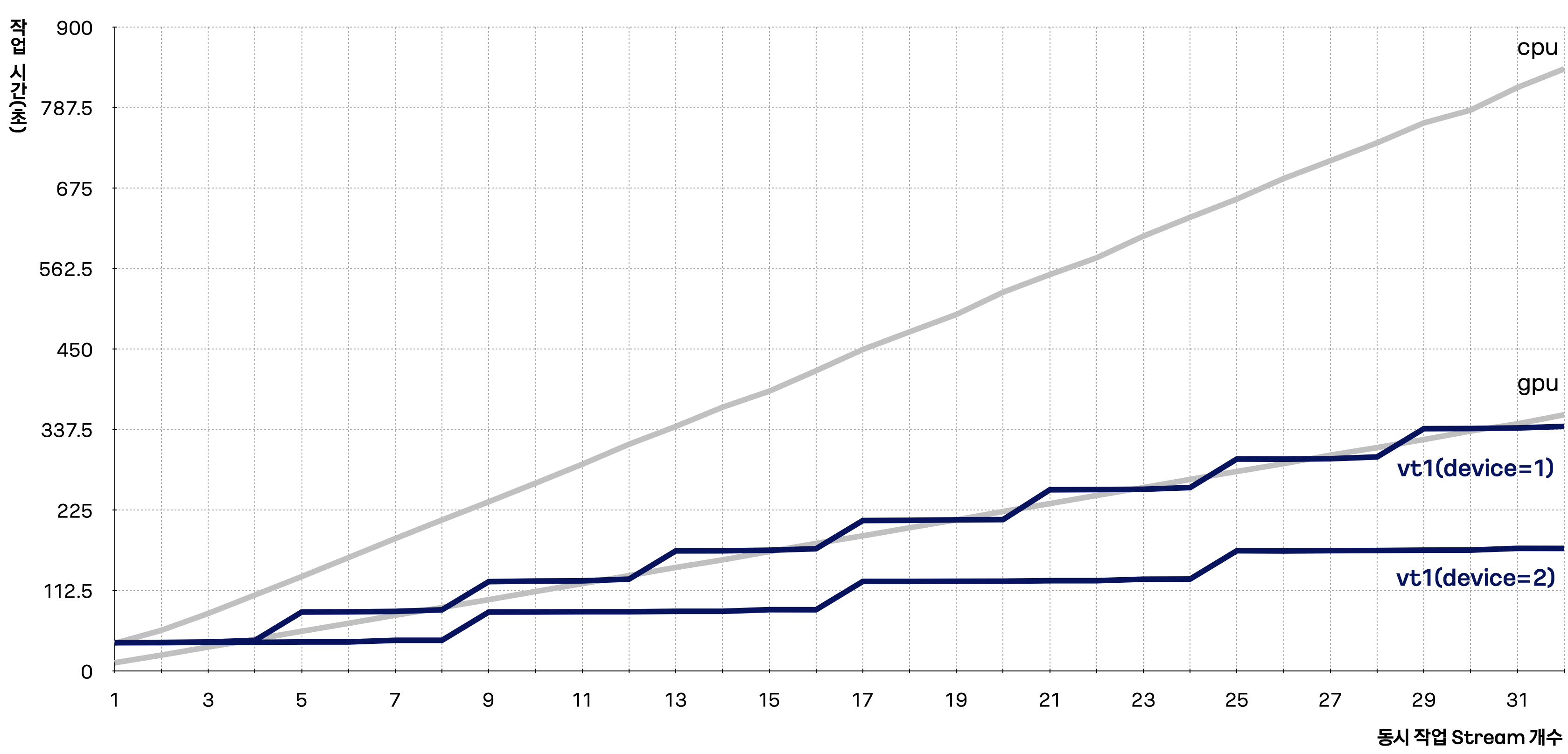
gn1i 및 c2a 인스턴스 유형에서 다중 스트림 트랜스코딩하는 수가 증가할 때 작업시간도 이에 비례하여 증가하는 것을 확인할 수 있습니다. 반면 vt1a 인스턴스 유형에서는 디바이스가 처리 가능한 다중 스트림 개수까지는 동시에 병렬 처리되어, 작업 시간의 증가폭이 상대적으로 적은 것을 확인할 수 있습니다.