Kubernetes Engine 클러스터에 NVIDIA GPU 워크 노드 사용
쿠버네티스 클러스터에서 GPU 노드를 생성하고, 워크로드에 GPU를 사용하는 두 가지 방법을 설명합니다.
- 예상 소요 시간: 15분
- 권장 운영 체제: macOS, Ubuntu
- 사전 준비 사항
시나리오 소개
이 튜토리얼은 Kubernetes Engine에서 NVIDIA GPU 워크 노드를 생성하고, 클러스터에서 GPU를 사용하는 두 가지 방식을 안내합니다. GPU Operator 또는 NVIDIA Device Plugin을 사용해 일반 GPU 워크 노드를 구성하거나, MIG(Multi-Instance GPU)를 활성화한 워크 노드를 구성해 리소스를 효율적으로 활용할 수 있습니다.
주요 내용은 다음과 같습니다.
- 쿠버네티스 클러스터에 GPU 노드 풀 추가
- GPU Operator 또는 NVIDIA Device Plugin 설치
- 워크로드에 GPU 자원 할당 및 실행 확인
- MIG 기능을 활용한 다중 인스턴스 GPU 환경 구성 및 테스트
시작하기 전에
Kubernetes 패키지 관리를 도와주는 패키지 매니저인 Helm을 설치합니다. Helm을 통해 Kubernetes용 소프트웨어를 검색하거나 공유하고 사용할 수 있습니다. 사용자의 로컬 머신에 아래와 같은 명령어를 입력하여 Helm 패키지를 설치합니다.
- Mac
- Linux(Ubuntu)
-
Homebrew 패키지 매니저를 이용하여 설치합니다.
brew install helm -
설치가 정상적으로 되었는지 아래 명령어를 통해 확인합니다.
helm version
# version.BuildInfo{Version:"v3.14.0", GitCommit:"3fc9f4b2638e76f26739cd77c7017139be81d0ea", GitTreeState:"clean", GoVersion:"go1.21.6"}
-
curl명령어를 이용하여 설치합니다.curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh -
설치가 정상적으로 되었는지 아래 명령어를 통해 확인합니다.
helm version
# version.BuildInfo{Version:"v3.14.0", GitCommit:"3fc9f4b2638e76f26739cd77c7017139be81d0ea", GitTreeState:"clean", GoVersion:"go1.21.6"}
시작하기
Kubernetes Engine을 이용해 생성한 쿠버네티스 클러스터에서 GPU 노드를 생성하는 방식과 워크로드에 GPU를 사용하는 방식을 설명합니다.
Type 1. NVIDIA GPU 워크 노드 구축
Type 1에서는 쿠버네티스 클러스터에 NVIDIA GPU 워크 노드를 구축하는 방법을 설명합니다.
Step 1. 쿠버네티스 클러스터에 NVIDIA GPU 노드 풀 생성
이 문서는 쿠버네티스 클러스터를 생성하는 방법을 다루지 않습니다. 새로운 클러스터를 생성하거나 기존에 존재하는 클러스터에 GPU 노드 풀을 생성합니다. 카카오클라우드 콘솔에서 쿠버네티스 노드 풀을 생성하는 방법은 다음과 같습니다.
-
카카오클라우드 콘솔에 접속합니다.
-
Kubernetes Engine > 클러스터 목록에서 작업을 진행할 클러스터 혹은 [클러스터 생성] 버튼을 클릭합니다.
- 노드 풀을 생성할 클러스터를 클릭한 경우, 클러스터의 상세 페이지의 노드 풀 탭에서 [노드 풀 생성] 버튼을 누른 후, 노드 풀 정보를 입력하고 노드 풀을 생성합니다.
- [클러스터 생성] 버튼을 클릭한 경우, 클러스터 생성 단계별로 정보를 입력합니다. 2단계: 노드 풀 설정에서 다음을 참고해 노드 풀 정보를 입력하고 클러스터를 생성합니다.
노드 풀 유형 인스턴스 유형 노드 수 볼륨(GB) GPU p2i.6xlarge 1 100 -
GPU 노드를 생성할 시, 단일 GPU 인스턴스로 생성되도록 사용자 스크립트에 아래 코드를 작성합니다.
sudo nvidia-smi -mig 0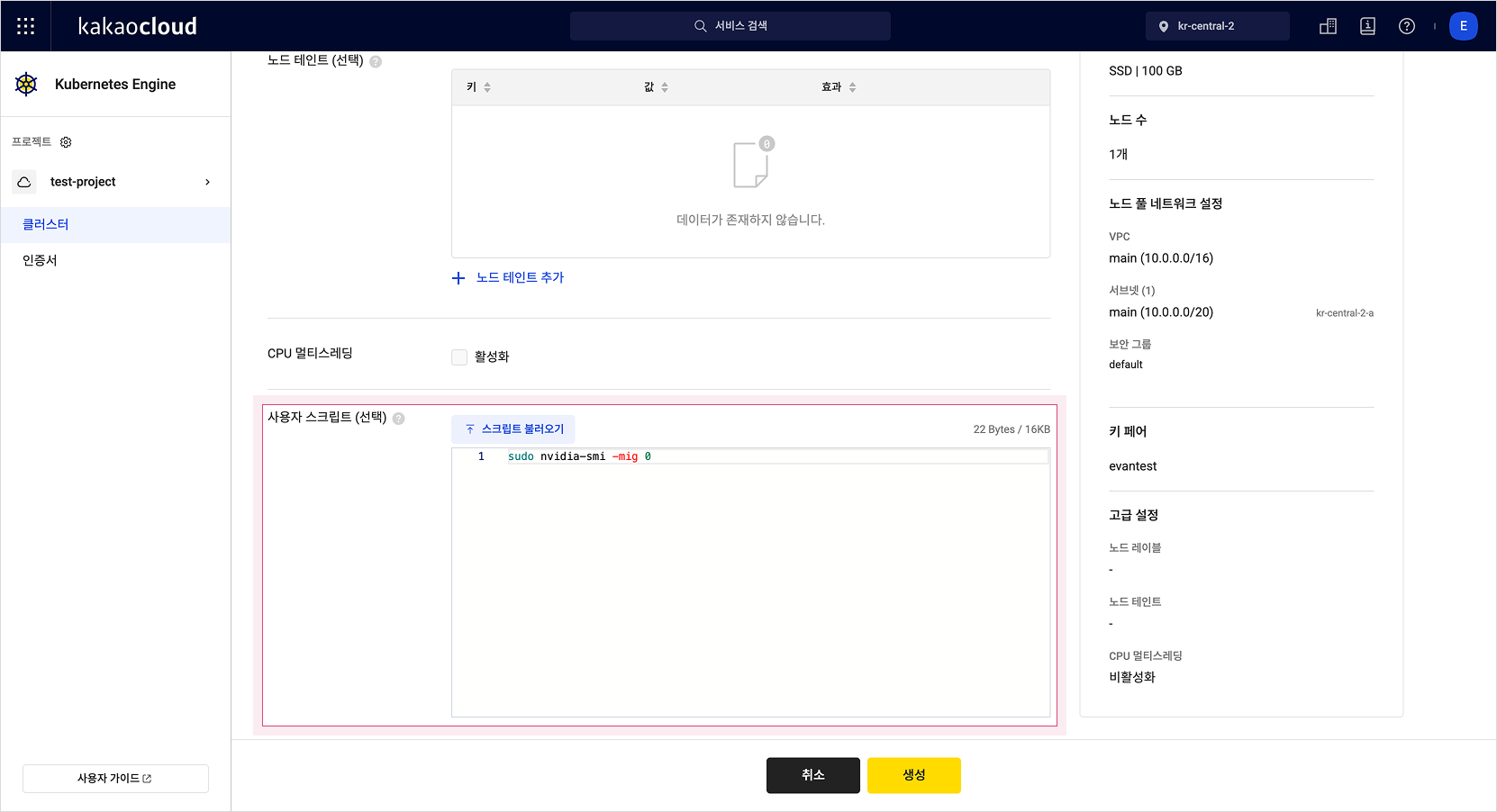
Step 2. NVIDIA GPU 워크 노드 환경 구성
NVIDIA GPU 워크 노드 환경 구성 방법은 GPU Operator를 사용하는 방법과 NVIDIA Device Plugin을 사용하는 방법으로 나누어 설명합니다.
두 방법 모두 클러스터 내 GPU를 자동으로 노출하고 관리, 실행 등에 필요한 기능을 제공합니다. 노드 풀을 통해 GPU 워크 노드를 생성하면, GPU 리소스를 사용하기 위해 필요한 Driver, Container Runtime 등의 환경 구축을 기본으로 제공합니다.
Option 1. GPU Operator 설치
-
Helm을 사용하여 GPU Operator를 설치합니다.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install gpu-operator nvidia/gpu-operator \
--namespace gpu-operator \
--create-namespace설치가 완료되면 GPU Operator가 자동으로 필요한 구성 요소를 설정합니다. 자세한 설명은 NVIDIA GPU Operator 공식 문서를 확인해 주세요.
-
GPU Operator가 정상적으로 설치되었는지 확인합니다.
# GPU Operator 설치 확인
kubectl get all -n gpu-operator -
설치된 GPU Operator의 로그를 확인할 수 있습니다.
# GPU Operator 로그 확인
kubectl logs -n gpu-operator -l app=gpu-operator
Option 2. NVIDIA Device Plugin 사용
-
RuntimeClass를 생성하여 GPU 사용을 위한 환경을 정의합니다.
cat <<EOF | kubectl create -f -
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia
EOF위 RuntimeClass는 GPU를 사용하는 모든 워크로드에서 공통적으로 사용됩니다.
-
nvidia-device-plugin을 설치합니다.
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm install \
--version=0.12.3 \
--namespace nvidia-device-plugin \
--create-namespace \
--generate-name \
nvdp/nvidia-device-plugin \
--set runtimeClassName=nvidia -
nvidia-k8s-device-plugin이 클러스터에 추가되었는지 확인합니다.
kubectl get all -A | grep nvidia
# gpu-operator pod/nvidia-container-toolkit-daemonset-ssrwp 1/1 Running 0 64m
# gpu-operator pod/nvidia-cuda-validator-f62c9 1/1 Running 0 64m
# gpu-operator pod/nvidia-dcgm-exporter-vhgd4 1/1 Running 0 64m
# nvidia-device-plugin pod/nvidia-device-plugin-1738819866-24wpl 0/1 ContainerCreating 0 64m
# ... -
아래 명령어로 노드 리소스의 상세 정보를 출력해, 자원 용량에 GPU가 추가된 것을 확인합니다.
kubectl describe nodes | grep nvidia
# nvidia.com/gpu: 1
# nvidia.com/gpu: 1
# ... -
쿠버네티스 클러스터에 GPU 테스트용 파드를 추가합니다. (runtimeClass 지정)
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
runtimeClassName: nvidia
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvidia/samples:vectoradd-cuda10.2"
resources:
limits:
nvidia.com/gpu: 1
EOF -
아래 명령어로 작업이 수행되었는지 확인합니다.
kubectl get pod/gpu-test
# NAME READY STATUS RESTARTS AGE
# gpu-test 0/1 Completed 0 2m -
아래 명령어로 작업 수행 로그를 확인할 수 있습니다.
kubectl logs gpu-test
# GPU 0: NVIDIA A100 80GB PCIe ...
# [Vector addition of 50000 elements]
# Copy input data from the host memory to the CUDA device
# CUDA kernel launch with 196 blocks of 256 threads
# Copy output data from the CUDA device to the host memory
# Test PASSED
# Done -
생성된 테스트용 Pod를 제거합니다.
kubectl delete pod/gpu-test
# pod "gpu-test" deleted
Type 2. MIG 지원 NVIDIA GPU 워크 노드 구축
Type 2에서는 쿠버네티스 클러스터에 GPU 작업 노드를 생성하고 MIG를 사용하는 방법 중 하나를 설명합니다.
카카오클라우드에서 제공하는 일부 GPU(예. A100 등)는 MIG(Multi Instance GPU)를 지원합니다. 사용자는 쿠버네티스 클러스터 노드를 GPU 지원 유형으로 생성하고 MIG 전략을 이용하여 리소스를 더 효율적으로 사용할 수 있습니다.
해당 GPU가 제공되는 인스턴스는 인스턴스 유형별 사양에서 확인할 수 있습니다.
Step 1. 쿠버네티스 클러스터에 GPU 워크 노드 추가
이 문서에서는 Kubernetes 클러스터를 생성하는 방법을 다루지 않습니다. 새로운 클러스터를 생성하거나 기존에 존재하는 클러스터에 GPU 노드 풀을 생성합니다.
-
카카오클라우드 콘솔에 접속합니다.
-
Kubernetes Engine > 클러스터 목록에서 작업을 진행할 클러스터 혹은 [클러스터 생성] 버튼을 클릭합니다.
- 노드 풀을 생성할 클러스터를 클릭한 경우, 클러스터의 상세 페이지의 노드 풀 탭에서 [노드 풀 생성] 버튼을 누르고 노드 풀 정보를 입력합니다.
- [클러스터 생성] 버튼을 클릭한 경우, 클러스터 생성의 단계별로 정보를 입력합니다. 다음을 참고하여 클러스터 생성의 2단계: 노드 풀 설정에서 노드 풀 정보를 입력합니다.
노드 풀 유형 인스턴스 유형 노드 수 볼륨(GB) GPU p2i.6xlarge 1 100 -
GPU 노드를 생성할 시, 노드 프로비저닝 단계에서 MIG를 허용하고 GPU 리소스를 MIG로 분리하는 스크립트를 작성합니다. GPU를 7개의 인스턴스로 분리하고 GPU 컨테이너 런타임 설정을 진행합니다.
sudo nvidia-smi -mig 1
sudo nvidia-smi mig -cgi 19,19,19,19,19,19,19 -C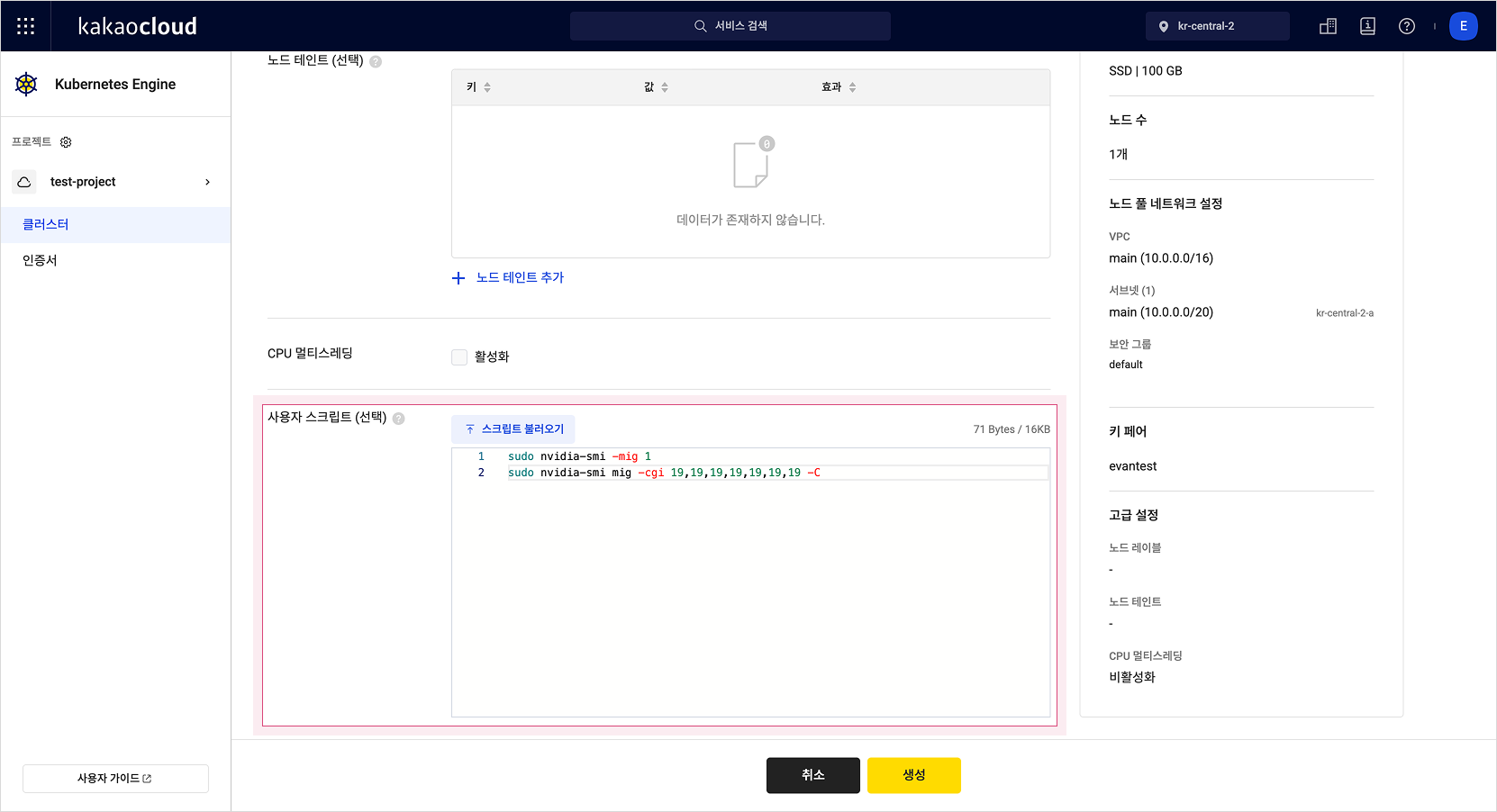
-
노드 풀을 생성합니다.
Step 2. NVIDIA GPU 워크 노드 환경 구성
Step 1 작업을 통해 MIG가 설정된 GPU 노드가 클러스터에 생성되었습니다.
-
RuntimeClass를 생성하여 GPU 사용을 위한 환경을 정의합니다.
cat <<EOF | kubectl create -f -
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia
EOF위 RuntimeClass는 GPU를 사용하는 모든 워크로드에서 공통적으로 사용됩니다.
-
쿠버네티스 클러스터에서 NVIDIA Device Plugin을 설치할 때, migStrategy 설정 플래그를 사용하여 MIG(Multi-Instance GPU) 리소스를 활성화할 수 있습니다. 이를 통해 단일 GPU를 여러 개의 독립적인 인스턴스로 나누어 보다 효율적으로 사용할 수 있습니다. 더 많은 정보가 필요하다면 NVIDIA/k8s-device-plugin Github을 참고하시기 바랍니다.
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm install \
--version=0.12.3 \
--namespace nvidia-device-plugin \
--create-namespace \
--set compatWithCPUManager=true \
--set migStrategy=mixed \
--generate-name \
nvdp/nvidia-device-plugin \
--set runtimeClassName=nvidia -
Helm 커맨드를 실행하면 nvidia-k8s-device-plugin Pod가 GPU 워크 노드에 올라가고 GPU를 클러스터에 노출합니다. 아래 명령어로 노드 리소스의 상세 정보를 출력해 자원 용량에 MIG 7개가 추가된 것을 확인합니다.
kubectl describe nodes | grep nvidia
# nvidia.com/mig-1g.10gb: 7
# nvidia.com/mig-1g.10gb: 7 -
현재 작업을 수행 중인 GPU 정보를 출력하는 명령어로, 워크로드 여러 개를 클러스터에 올립니다. 클러스터 리소스의 스케줄링을 확인합니다.
for i in $(seq 7); do
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: mig-example-${i}
spec:
restartPolicy: Never
runtimeClassName: nvidia
containers:
- name: cuda-container
image: nvidia/cuda:11.2.2-base-ubuntu20.04
command: ["nvidia-smi"]
args: ["-L"]
resources:
limits:
nvidia.com/mig-1g.10gb: 1
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
done
# pod/mig-example-1 created
# pod/mig-example-2 created
# pod/mig-example-3 created
# pod/mig-example-4 created
# pod/mig-example-5 created
# pod/mig-example-6 created
# pod/mig-example-7 created -
생성된 pod를 확인합니다. 명령어에 대한 결과와 같이 작업이 완료되었는지 확인합니다.
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# mig-example-1 0/1 Completed 0 29s
# mig-example-2 0/1 Completed 0 26s
# mig-example-3 0/1 Completed 0 22s
# mig-example-4 0/1 Completed 0 19s
# mig-example-5 0/1 Completed 0 15s
# mig-example-6 0/1 Completed 0 12s
# mig-example-7 0/1 Completed 0 9s -
작업이 완료되면 로그를 통해 해당 Pod를 실행한 MIG의 UUID를 확인할 수 있습니다. 아래 명령어를 입력해 결과를 확인합니다.
for i in $(seq 7); do
kubectl logs mig-example-${i} | grep MIG
done
# MIG 1g.10gb Device 0: (UUID: MIG-aaaaa)
# MIG 1g.10gb Device 0: (UUID: MIG-bbbbb)
# MIG 1g.10gb Device 0: (UUID: MIG-ccccc)
# MIG 1g.10gb Device 0: (UUID: MIG-aaaaa)
# MIG 1g.10gb Device 0: (UUID: MIG-bbbbb)
# MIG 1g.10gb Device 0: (UUID: MIG-ddddd)
# MIG 1g.10gb Device 0: (UUID: MIG-eeeee) -
생성한 예제 Pod를 제거합니다.
for i in $(seq 7); do
kubectl delete pod mig-example-${i}
done
# pod "mig-example-1" deleted
# pod "mig-example-2" deleted
# pod "mig-example-3" deleted
# pod "mig-example-4" deleted
# pod "mig-example-5" deleted
# pod "mig-example-6" deleted
# pod "mig-example-7" deleted