1. LLM 모델 서빙 Endpoint 생성
카카오클라우드 Kubeflow에서 LLM 모델 서빙 API Endpoint를 생성하는 방법을 안내합니다.
- 예상 소요 시간: 30분
- 권장 운영 체제: Ubuntu
- 사전 준비 사항
- Kubeflow 기반 LLM 워크플로우의 사전 준비 사항 완료
시나리오 소개
Kubeflow 환경에서 KServe를 활용해 최신 LLM 모델인 카카오의 카나나(Kanana) 와 Meta Llama 3.2의 사전 학습(pretrained) 모델을 기반으로, CPU/GPU 환경에서 서빙 API Endpoint를 생성하는 과정을 설명합니다. 사용자는 KServe를 활용한 모델 서빙 API 구축 과정을 직접 구현하여, Kubeflow 내 서빙 프로세스를 이해하고 실시간 AI 대화형 API를 쉽고 효과적으로 관리할 수 있습니다.
주요 내용은 다음과 같습니다.
- Kubeflow에서 LLM 모델 Endpoint(
Inference ServiceCR) 배포 - 배포된 Endpoint를 통한 추론 테스트 및 응답 확인
지원 도구
| 도구 | 버전 | 설명 |
|---|---|---|
| Jupyter Notebook | 4.2.1 | 다양한 머신러닝 프레임워크와 Kubeflow SDK 연동을 지원하는 웹 기반 개발 환경 |
| KServe | 0.15.0 | - 모델 서빙 도구로 빠른 모델 배포 및 업데이트 지원, 높은 가용성과 확장성을 제공 - 머신러닝 모델 서빙을 위한 일반적인 문제(로드 밸런싱, 모델 버전 관리, 실패 복구 등) 자동 처리 |
시작하기 전에
1. Kubeflow 환경 준비
Kubeflow에서 LLM 모델을 안정적으로 서빙하기 위해 아래와 같은 사양의 노드 풀 환경이 필요합니다. 사전 준비 사항을 참고하여 CPU 또는 GPU 노드 풀이 설정된 환경을 먼저 준비하세요.
2. 실습 환경 설정 전 확인 사항
실습이 원활하게 진행될 수 있도록 아래 항목을 반드시 확인 및 설정하세요.
| 항목 | 확인 및 설정 내용 |
|---|---|
| Kubeflow 도메인 연결 및 쿼터 설정 | - Kubeflow 생성 시 도메인 연결(선택) 항목에 도메인 설정 필요 - 쿼터 설정 문서를 참고해 쿼터를 미설정으로 유지 ㄴ 네임스페이스에 쿼터가 설정되어 있으면 리소스 사용 제약 발생 가능 |
| KServe 인증 비활성 확인 | - KServe 서빙 API에 대해 Dex 인증이 비활성화되어 있어야 함 ㄴ 설정 방법은 서비스 > 문제 해결 문서를 참조 |
3. Serving Runtime CR 배포
ServingRuntime 또는 ClusterServingRuntime은 KServe에서 추론을 위한 런타임 타입을 정의하는 CR(Custom Resource) 입니다. 이 리소스는 사용자가 InferenceService CR을 손쉽게 생성하고 관리할 수 있도록 서빙 환경을 미리 정의합니다.
Kubeflow 버전별 ServingRuntime 설정 가이드
| Kubeflow 버전 | ServingRuntime 설정 방식 |
|---|---|
| 1.10 | Hugging Face용 ServingRuntime CR이 기본 설치되어 있으므로, 별도 작업 불필요 |
| 1.9 | 아래 YAML을 사용해 직접 생성 필요 |
YAML 생성 및 배포 절차
Kubeflow 환경에서 사용하는 네임스페이스(예: admin-user)를 <YOUR_NAMESPACE>에 입력하고, 아래 YAML 중 CPU 또는 GPU 환경에 맞는 설정을 적용하세요.
- CPU 이미지 사용 시
- GPU 이미지 사용 시
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: kserve-huggingfaceserver
namespace: <YOUR_NAMESPACE>
spec:
annotations:
prometheus.kserve.io/path: /metrics
prometheus.kserve.io/port: "8080"
containers:
- image: kserve/huggingfaceserver:v0.15.0
name: kserve-container
resources:
limits:
cpu: "1"
memory: 2Gi
requests:
cpu: "1"
memory: 2Gi
protocolVersions:
- v2
- v1
supportedModelFormats:
- autoSelect: true
name: huggingface
priority: 1
version: "1"
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: kserve-huggingfaceserver
namespace: <YOUR_NAMESPACE>
spec:
annotations:
prometheus.kserve.io/path: /metrics
prometheus.kserve.io/port: "8080"
containers:
- image: kserve/huggingfaceserver:v0.15.0-gpu
name: kserve-container
resources:
limits:
cpu: "1"
memory: 2Gi
requests:
cpu: "1"
memory: 2Gi
protocolVersions:
- v2
- v1
supportedModelFormats:
- autoSelect: true
name: huggingface
priority: 1
version: "1"
YAML 파일을 huggingface_sr.yaml으로 저장한 후, 다음 명령어를 실행하여 ServingRuntime 리소스를 생성합니다.
kubectl apply -f huggingface_sr.yaml
Kubectl 설정 방법은 kubectl 제어 설정 문서를 참고하세요.
Kubeflow 노트북 터미널 환경에서는 별도 kubeconfig 없이도 kubectl 명령어를 바로 사용할 수 있습니다.
시작하기
본 실습은 Hugging Face Runtime 또는 커스텀 모델 이미지 중 하나를 선택해 LLM 모델을 서빙합니다. Kubeflow KServe를 사용한 LLM 모델 서빙 과정의 구체적인 단계는 다음과 같습니다.
Step 1. InferenceService CR 정의 및 생성
앞서 준비한 ServingRuntime CR을 기반으로, 본격적으로 LLM 모델을 서빙하는 InferenceService 리소스를 정의합니다. 이 과정을 통해 Kubeflow 내에서 실시간 추론 API를 구성하고, 외부 또는 내부 요청에 응답할 수 있는 엔드포인트를 생성합니다. Hugging Face 서빙 런타임 또는 커스텀 모델을 활용해 LLM 모델을 서빙할 수 있으며, 아래와 같이 구현 형태를 선택할 수 있습니다.
구현 방식 1. Hugging Face 기반 모델 서빙
InferenceService는 Kubeflow KServe에서 모델 서빙을 위해 사용하는 기본 리소스입니다. 카카오의 Kanana-Nano-2.1B, Meta의 Llama 3.2와 같은 Hugging Face 기반 LLM 모델도 이 리소스를 통해 손쉽게 서빙할 수 있습니다.
아래는 Hugging Face Serving Runtime을 활용하여 InferenceService를 정의한 예시입니다.
- Kanana 모델
- Llama3 모델
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: kanana-isvc
spec:
predictor:
model:
modelFormat:
name: huggingface
args:
- --model_name=kanana-nano-inst
- --model_id=kakaocorp/kanana-nano-2.1b-instruct
- --dtype=bfloat16
- --backend=vllm
# GPU 사용
resources:
limits:
cpu: '1'
memory: '32Gi'
nvidia.com/mig-1g.10gb: '1'
requests:
cpu: '1'
memory: '2Gi'
nvidia.com/mig-1g.10gb: '1'
# CPU 사용
# limits:
# cpu: '6'
# memory: '32Gi'
# requests:
# cpu: '1'
# memory: '2Gi'
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: llama-isvc
spec:
predictor:
model:
modelFormat:
name: huggingface
args:
- --model_name=llama3-inst
- --model_id=meta-llama/Llama-3.2-3B-Instruct
- --dtype=bfloat16
- --backend=vllm
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: HF_TOKEN
optional: false
resources:
# GPU 사용
limits:
cpu: '1'
memory: '32Gi'
nvidia.com/mig-4g.40gb: '1'
requests:
cpu: '1'
memory: '2Gi'
nvidia.com/mig-4g.40gb: '1'
# CPU 사용
# limits:
# cpu: '6'
# memory: '32Gi'
# requests:
# cpu: '1'
# memory: '2Gi'
Hugging Face에서 모델 접근 권한이 제한된 리포지토리 또는 private 모델 리포지토리인 경우, Hugging Face 액세스 토큰을 Kubernetes Secret으로 등록해야 합니다.
apiVersion: v1
kind: Secret
metadata:
name: hf-secret
type: Opaque
stringData:
HF_TOKEN: <YOUR_HUGGINGFACE_TOKEN>
자세한 Hugging Face 토큰 발급 방법은 Hugging Face 공식 문서를 참고하세요.
구현 방식 2. 커스텀 모델 서빙
사용자가 직접 모델 로직을 구현하고 Docker 이미지로 빌드하여 KServe로 서빙하는 방식입니다.
이때 Python에서 제공되는 기본 모델 클래스(BaseModel)를 상속받아 load(), predict() 등의 메서드를 구현해야 하며, 생성한 이미지는 InferenceService 리소스에서 참조합니다.
또는, Object Storage에 저장된 모델 파일을 직접 참조하여 서빙할 수도 있습니다. 이 경우 별도의 Docker 이미지 없이도 모델을 서빙할 수 있으며, KServe에서 S3 호환 API를 통해 모델 파일에 접근할 수 있도록 Secret과 ServiceAccount 설정이 필요합니다.
- 실습 데이터 다운로드: custom_model_files.zip
- 자세한 가이드: Kserve 공식 문서
Object Storage 설정 방법 (선택)
-
S3 API 사용을 위한 크리덴셜을 발급받은 후, Kubeflow 노트북 환경에서 다음과 같이
Secret과ServiceAccount를 생성합니다.kserve-s3-access.yaml 예시apiVersion: v1
kind: Secret
metadata:
name: kserve-s3-secret
annotations:
serving.kserve.io/s3-endpoint: objectstorage.kr-central-2.kakaocloud.com
serving.kserve.io/s3-usehttps: "1"
serving.kserve.io/s3-region: "kr-central-2"
serving.kserve.io/s3-useanoncredential: "false"
type: Opaque
stringData:
AWS_ACCESS_KEY_ID: {S3_ACCESS_KEY} # 발급받은 액세스 키 입력
AWS_SECRET_ACCESS_KEY: {S3_SECRET_ACCESS_KEY} # 발급받은 시크릿 키 입력
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kserve-s3-sa
secrets:
- name: kserve-s3-secret -
InferenceService에서 storageUri에 S3 모델 객체 URL을 입력하고,serviceAccountName항목에 위에서 생성한ServiceAccount를 지정하면 모델이/mnt/models/경로에 자동 마운트됩니다.추론 스크립트apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: <llm-isvc> # 예: kanana-isvc 또는 llama-isvc
spec:
predictor:
serviceAccountName: kserve-s3-sa # 생성한 ServiceAccount 이름
model:
storageUri: s3://{MODEL_OBJECT_URL} # 모델이 위치한 S3 URI 경로
...
이 설정은 Docker 이미지 없이 모델 파일만으로 서빙하고자 할 때 유용하며, 공통 모델 저장소를 활용할 수 있는 장점이 있습니다.
커스텀 모델 서빙 구현
Meta의 Llama 3.1 Instruct 모델을 대상으로 사용자 정의 모델 클래스를 작성하고, Docker 이미지로 빌드하여 KServe에서 서빙합니다.
-
아래는 Hugging Face 파이프라인을 활용해 KServe용 추론 로직을 직접 구현한 예시입니다.
추론 스크립트import argparse
import logging
import os
from typing import Dict, Union
from PIL import Image
import base64
import io
import numpy as np
import kserve
import torch
from transformers import pipeline
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
huggingface_key = "<YOUR_HUGGINGFACE_TOKEN>"
os.environ["HUGGING_FACE_TOKEN"] = huggingface_key
class CustomLlmModel(kserve.Model):
def __init__(self, name: str):
super().__init__(name)
self.name = name
self.ready = False
self.tokenizer = None
self.model = None
self.pipe = None
self.load()
def load(self):
model_id = "meta-llama/Llama-3.1-8B-Instruct"
self.pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
token=huggingface_key,
)
logging.info(f"cuda is available: {torch.cuda.is_available()}")
self.ready = True
def predict(self,
request: Dict,
headers: Dict[str, str] = None) -> Dict:
logging.info("request : ")
logging.info(request)
question = "What is the capital of France?"
if request["question"]:
question = request["question"]
message = [
{"role": "user", "content": question},
]
outputs = self.pipe(
message,
max_new_tokens=100
)
answer = outputs[0]["generated_text"][-1]
logging.info(answer)
return {"answer": outputs[0]["generated_text"][-1]}
parser = argparse.ArgumentParser(parents=[kserve.model_server.parser])
parser.add_argument(
"--model_name", help="The name that the model is served under.", default="llama3-inst"
)
args, _ = parser.parse_known_args()
if __name__ == "__main__":
model = CustomLlmModel(args.model_name)
kserve.ModelServer().start([model]) -
Dockerfile을 아래와 같이 구성합니다.
빌드 스크립트(Dockerfile)ARG PYTHON_VERSION=3.9
ARG BASE_IMAGE=python:${PYTHON_VERSION}-slim-bullseye
ARG VENV_PATH=/prod_venv
FROM ${BASE_IMAGE} as builder
# Install Poetry
ARG POETRY_HOME=/opt/poetry
ARG POETRY_VERSION=1.4.0
ARG KSERVE_VERSION=0.15.0
RUN python3 -m venv ${POETRY_HOME} && ${POETRY_HOME}/bin/pip install poetry==${POETRY_VERSION}
ENV PATH="$PATH:${POETRY_HOME}/bin"
# Activate virtual env
ARG VENV_PATH
ENV VIRTUAL_ENV=${VENV_PATH}
RUN python3 -m venv $VIRTUAL_ENV
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
COPY custom_model/pyproject.toml custom_model/poetry.lock custom_model/
RUN cd custom_model && poetry install --no-root --no-interaction --no-cache
COPY custom_model custom_model
RUN cd custom_model && poetry install --no-interaction --no-cache
FROM ${BASE_IMAGE} as prod
# Activate virtual env
ARG VENV_PATH
ENV VIRTUAL_ENV=${VENV_PATH}
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
RUN useradd kserve -m -u 1000 -d /home/kserve
COPY --from=builder --chown=kserve:kserve $VIRTUAL_ENV $VIRTUAL_ENV
COPY --from=builder custom_model custom_model
USER 1000
ENTRYPOINT ["python", "-m", "custom_model.model"] -
작성한 파일을 바탕으로 다음 명령어로 이미지 빌드 및 푸시를 수행합니다.
도커 빌드 명령어$ cd sample_kserve_custom_model
# Option1 : Docker CLI 실행
$ sudo docker buildx build --progress=plain -t <YOUR_CUSTOM_MODEL_IMG>:<YOUR_CUSTOM_MODEL_TAG> -f Dockerfile .
# Option2 : Makefile 실행
$ make docker-build-custom-model
## 또는
$ make docker-push-custom-model -
(선택) 앞서 설명한 Object Storage 연동 방식에 따라, 아래는 실제
Secret,ServiceAccount, 그리고InferenceService구성 예시입니다.apiVersion: v1
kind: Secret
metadata:
name: kserve-s3-secret
annotations:
serving.kserve.io/s3-endpoint: objectstorage.kr-central-2.kakaocloud.com
serving.kserve.io/s3-usehttps: "1"
serving.kserve.io/s3-region: "kr-central-2"
serving.kserve.io/s3-useanoncredential: "false"
type: Opaque
stringData:
AWS_ACCESS_KEY_ID: {S3_ACCESS_KEY}
AWS_SECRET_ACCESS_KEY: {S3_SECRET_ACCESS_KEY}
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kserve-s3-sa
secrets:
- name: kserve-s3-secret -
빌드한 이미지 또는 Object Storage 경로를 참조하여 아래와 같이
InferenceService를 구성합니다.InferenceService 예시apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: custom-llama-model
spec:
predictor:
timeout: 600
containers:
- name: kserve-container
image: "<YOUR_DOCKER_REGISTRY_URI>/test-kserve-llama-model:v0.0.1"
env:
- name: HUGGING_FACE_TOKEN
value: {YOUR HUGGINGFACE TOKEN}
resources:
# GPU 사용
limits:
cpu: "6"
memory: "24Gi"
nvidia.com/mig-4g.40gb: "1"
requests:
cpu: '1'
memory: '2Gi'
nvidia.com/mig-4g.40gb: "1"
# CPU 사용
# limits:
# cpu: "6"
# memory: "24Gi"
# requests:
# cpu: '1'
# memory: '2Gi'
Step 2. Kubeflow 대시보드를 통한 배포
작성한 InferenceService 리소스를 Kubeflow 대시보드에서 배포할 수 있습니다.
-
Kubeflow 대시보드에 접속한 후, 좌측 메뉴의 [Endpoints] 항목을 클릭하여 Endpoint 목록 페이지로 이동합니다.
-
오른쪽 상단의 [New Endpoint] 버튼을 클릭하여 새 Endpoint 생성 페이지로 진입합니다.
-
Endpoint 생성 페이지는 사용자가 직접 작성한 YAML 코드를 입력하는 방식으로 구성되어 있습니다. 이전 단계에서 준비한
InferenceService의 YAML 코드를 입력란에 복사하여 붙여넣은 후, 하단의 [CREATE] 버튼을 클릭하면 모델 서빙 Endpoint가 생성됩니다.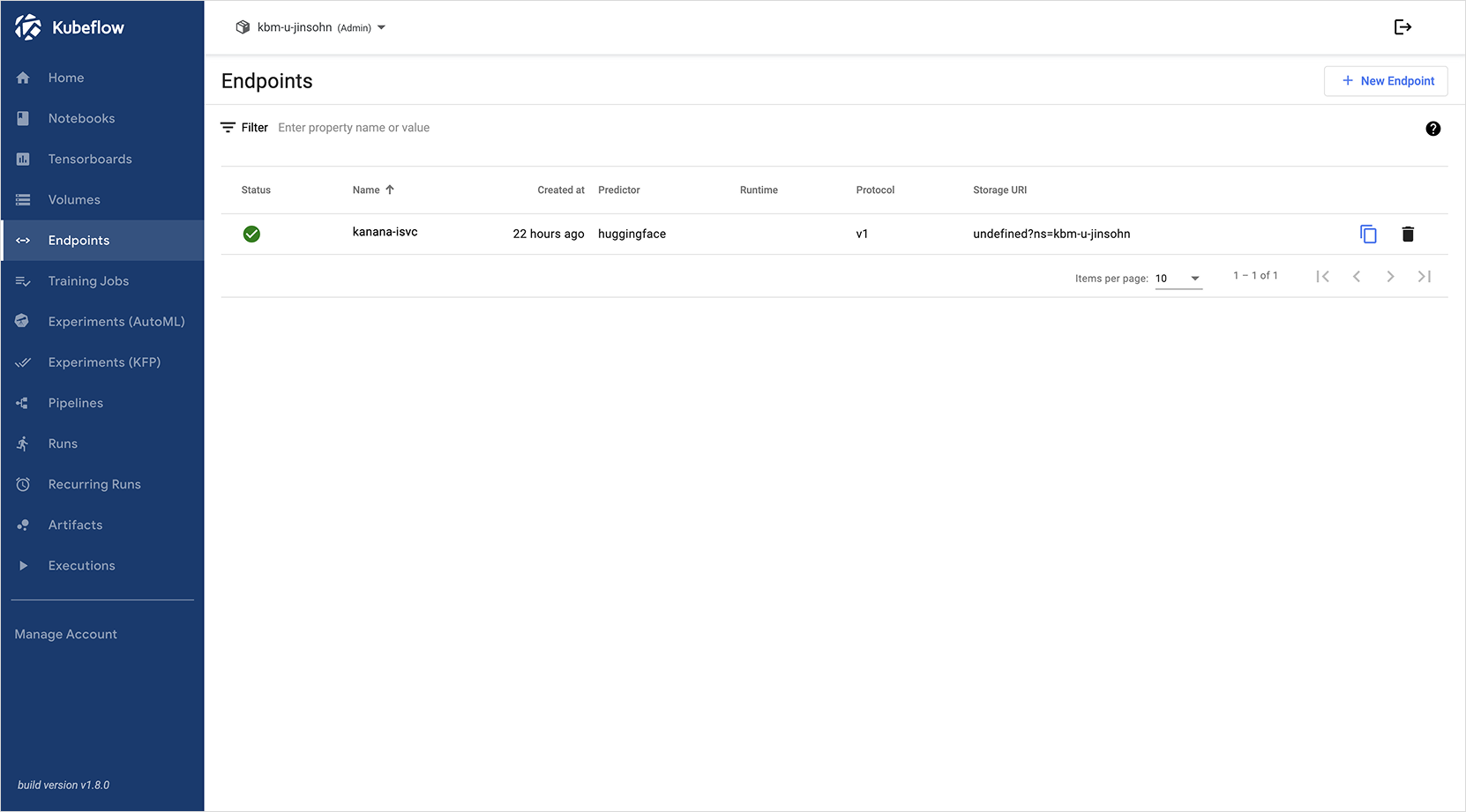
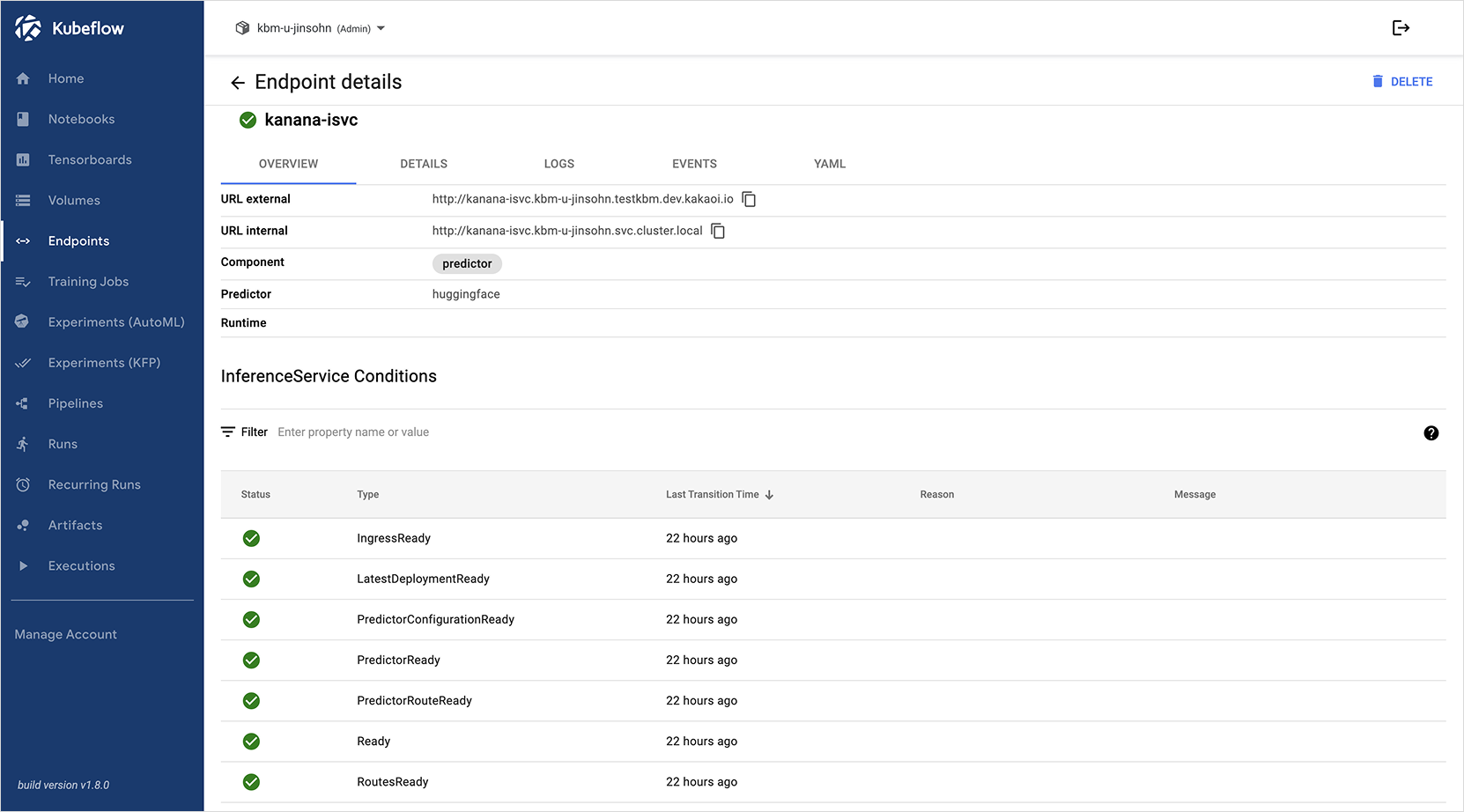
Step 3. Endpoint 응답 테스트
Endpoint(InferenceService)가 정상적으로 생성되었다면, 해당 Endpoint를 통해 프롬프트를 보내고 응답을 받는 추론 요청을 수행할 수 있습니다.
이 단계에서는 Kanana(kanana-nano-inst) 및 Llama 3.2(llama3-inst) 모델이 각각 llama-isvc, kanana-isvc 이름으로 배포되어 있다고 가정하고, curl 또는 Python 코드를 활용해 응답을 테스트합니다.
이 단계에서는 curl 명령어와 Python의 requests 패키지를 활용하여, 생성된 Endpoint 도메인으로 실제 응답 결과를 확인합니다.
- 본 단계부터는 KServe 서빙 API 인증 비활성화 설정이 반드시 선행되어야 합니다.
- 자세한 설명은 서비스 > 문제 해결 문서를 확인해 주세요.
방법 1. Curl을 활용한 요청 테스트
사용자 로컬 머신 또는 서버 환경의 터미널에 접속 후 아래 코드를 실행합니다. ISVC_NAME 변수에 테스트할 모델(llama-isvc 또는 kanana-isvc)을 지정하세요.
export ISVC_NAME=kanana-isvc # 또는 llama-isvc
export NAMESPACE=<사용자의 네임스페이스 입력>
export KUBEFLOW_PUBLIC_DOMAIN=<연결한 kubeflow 도메인>
curl --insecure --location 'https://${KUBEFLOW_PUBLIC_DOMAIN}/openai/v1/completions' \
--header 'Host: ${ISVC_NAME}.${NAMESPACE}.${KUBEFLOW_PUBLIC_DOMAIN}' \
--header 'Content-Type: application/json' \
--data '{
"model": "kanana-nano-inst", # 또는 llama3-inst
"prompt": "카카오엔터프라이즈에 대해서 설명해줘",
"stream": false,
"max_tokens": 100
}'
NAMESPACE 변수는 kbm-u/kbm-g로 시작하는 사용자 네임스페이스 이름이며, KUBEFLOW_PUBLIC_DOMAIN 변수는 Kubeflow 생성 시 연결한 도메인 값을 입력합니다. NAMESPACE와 KUBEFLOW_PUBLIC_DOMAIN은 각자 Kubeflow 생성 시 확인한 값을 입력해야 합니다.
{
"id": "c37b34de-a647-4d88-b891-c0fe8a1ee291",
"object": "text_completion",
"created": 1742535948,
"model": "kanana-nano-inst" ## 또는 "llama3-inst"
"choices": [
{
"index": 0,
"text": "\n카카오엔터프라이즈(Kakao Enterprise)는 카카오가 2020년 5월에 공식적으로 출범한 기업으로 기업용 소프트웨어 및 서비스를 제공하는 기업입니다. 카카오 엔터프라이즈는 기업용 메신저, 협업 도구, 비즈니스 플랫폼 등 다양한 서비스를 제공하며, 기업의 업무 효율성을 높이고 비즈니스 성과를 향상시키는 데 도움을 줍니다. 카카오 엔터프라이즈",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 15,
"total_tokens": 115,
"completion_tokens": 100,
"prompt_tokens_details": null
},
"system_fingerprint": null
}
방법 2. Python 패키지를 이용한 요청 테스트
노트북과 같은 파이썬 환경에서는 langchain과 requests 패키지를 사용하여 추론이 가능합니다.
- Kubeflow 내부 환경(노트북)
- 외부환경
from langchain_openai import ChatOpenAI
import os
isvc_name = "<Endpoints(Inference Service) 이름>"
namespace = "<사용자의 네임스페이스>"
model_name = "<Inference Service에 작성한 모델 이름>"
llm_svc_url = f"http://{isvc_name}.{namespace}.svc.cluster.local/"
llm = ChatOpenAI(
model_name=model_name,
base_url=os.path.join(llm_svc_url,'openai','v1'),
openai_api_key="empty" #
)
input_text = "카카오 엔터프라이즈에 대해서 설명해줘"
llm.invoke(input_text)
# "\n카카오 엔터프라이즈는 카카오의 자회사로, 기업용 소프트웨어 및 서비스를 제공하는 기업입니다. ..."
# python 버전에 맞는 패키지 설치를 진행합니다.
## pip install langchain-openai
isvc_name = "<Endpoints(Inference Service) 이름>"
namespace = "<사용자의 네임스페이스>"
host = "<kubeflow 도메인>"
model_name= "<모델 이름>"
base_url = f"https://{host}"
# http client 설정
client = httpx.Client(
base_url=base_url,
headers={
"Host": f"{isvc_name}.{namespace}.{host}",
"Content-Type": "application/json"
},
verify=False
)
# llm client 생성
llm = OpenAI(
model_name=model_name,
base_url=os.path.join(base_url, "openai", "v1"),
openai_api_key="empty",
http_client=client # client 추가
)
# 테스트
input_text = "카카오엔터프라이즈에 대해서 설명해줘"
output_response = llm.invoke(
input_text
)
print(output_response)
아래는 생성된 Endpoint에 프롬프트를 전송한 후 반환된 응답 예시입니다.
카카오엔터프라이즈(Kakao Enterprise)는 카카오의 자회사로, 인공지능(AI)과 클라우드 컴퓨팅을 비롯한 다양한 디지털 기술을 기반으로 한 종합 IT 서비스 기업입니다. 다음은 카카오엔터프라이즈의 주요 특징과 역할에 대한 상세한 설명입니다:
### 주요 특징
1. **AI 및 클라우드 솔루션**:
- **AI 비서**: 카카오의 AI 기술로 제작된 비서 서비스인 '카카오 i'를 통해 사용자 맞춤형 서비스를 제공합니다.
- **클라우드 서비스**: 카카오엔터프라이즈는 클라우드 인프라를 제공하여 다양한 기업들이 효율적으로 IT 자원을 관리할 수 있도록 지원합니다.
2. **데이터 분석 및 인사이트**:
- **데이터 분석 솔루션**: 기업의 다양한 데이터를 분석해 인사이트를 제공하고, 이를 통해 의사결정을 지원합니다.
- **지능형 고객 관리**: AI 기술을 활용한 고객 상담 및 관리 솔루션을 제공하여 고객 만족도를 높입니다.