2. 모델 하이퍼파라미터 튜닝
카카오클라우드 Kubeflow에서 트래픽 예측 모델의 성능 향상을 위한 하이퍼파라미터 자동 튜닝을 수행합니다.
- 예상 소요 시간: 40분
- 권장 운영 체제: macOS, Ubuntu
- 사전 준비 사항
시나리오 소개
이 튜토리얼에서는 Kubeflow Katib을 활용하여 트래픽 예측 모델의 하이퍼파라미터를 자동으로 최적화합니다. 튜닝 코드 작성부터 Docker 이미지 생성, Experiment 설정 및 실행, 결과 확인까지의 전 과정을 실습합니다.
Katib을 활용하려면 다음과 같은 구성 요소가 필요합니다.
- 하이퍼파라미터를 받아 모델을 학습하는 Python 스크립트 (tune.py)
- 해당 스크립트를 실행할 Docker 이미지 및 종속성 파일 (requirements.txt)
- 실험 실행을 정의하는 Experiment YAML 설정 파일 (katib-experiment.yaml)
시작하기 전에
이 실습은 앞선 트래픽 예측 튜토리얼(1편) 을 완료한 상태를 기준으로 작성되었습니다. 특히, 모델 학습에 사용할 전처리된 데이터셋(nlb-sample.csv)이 준비되어 있어야 하며, Kubeflow Katib 기능이 활성화된 환경에서 실습을 진행해야 합니다.
필수 조건
| 항목 | 설명 |
|---|---|
| Kubeflow 환경 | Katib 기능이 포함되어 있어야 함 |
| PVC 설정 | dataset-pvc로 데이터가 /dataset 경로에 마운트되어야 함 |
| Container Registry | 퍼블릭 또는 카카오클라우드 Container Registry 사용 가능 |
시작하기
Step 1. 튜닝 코드 작성 및 이미지 빌드
1. 튜닝 코드 작성
하이퍼파라미터 튜닝을 위한 tune.py 파일을 생성하고 아래 코드를 입력합니다.
이 코드는 이전 실습에서 사용한 GradientBoosting 모델을 기반으로 동작하며, 여러 파라미터 중 n_estimators, learning_rate, max_depth, subsample를 조합하여 모델을 학습합니다.
데이터셋은 5개의 폴드로 분할한 뒤, 교차 검증(Cross-validation) 을 통해 각 조합의 성능을 평가합니다. 각 반복에서 측정된 MAE(Mean Absolute Error) 값을 평균 내어 출력하며, Katib 실험의 평가 지표로 활용됩니다.
import argparse
import pandas as pd
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import cross_val_score
parser = argparse.ArgumentParser()
parser.add_argument('--n_estimators', type=int, default=100)
parser.add_argument('--learning_rate', type=float, default=0.1)
parser.add_argument('--max_depth', type=int, default=3)
parser.add_argument('--subsample', type=float, default=1.0)
parser.add_argument('--data_version', type=str, default='sample')
parser.add_argument('--random_state', type=int, default=1234)
if __name__ == "__main__":
args = parser.parse_args()
df = pd.read_csv(f'/dataset/nlb-{args.data_version}.csv') # 전처리된 데이터셋 경로
model = GradientBoostingRegressor(
n_estimators=args.n_estimators,
learning_rate=args.learning_rate,
max_depth=args.max_depth,
subsample=args.subsample,
random_state=args.random_state
)
X = df[['x1', 'x2', 'x3', 'x4']]
y = df['y']
scores = cross_val_score(model, X, y, cv=5, scoring='neg_mean_absolute_error')
mae = -scores.mean()
print("MAE=%f" % mae)
/dataset 경로에는 학습용 데이터셋 nlb-sample.csv이 위치해야 합니다.
해당 파일은 이전 실습에서 생성된 결과물로, Katib 실험 시 dataset-pvc를 이 경로에 마운트하여 사용할 수 있습니다.
2. 튜닝 이미지 빌드
Katib은 사용자가 정의한 컨테이너 이미지를 실행하여 실험을 수행하므로, tune.py가 포함된 Docker 이미지를 직접 빌드하고 컨테이너 레지스트리에 푸시해야 합니다.
-
tune.py와requirements.txt,Dockerfile을 동일 디렉터리에 준비합니다.DockerfileFROM python:3.10.0-slim
WORKDIR /app
COPY requirements.txt /app/requirements.txt
COPY tune.py /app/tune.py
RUN pip install -r requirements.txt
RUN rm requirements.txt
CMD ["python", "/app/tune.py"]requirements.txtpandas==2.2.2
numpy==2.1.1
scikit-learn==1.5.1
scipy==1.14.1 -
터미널에서 아래 명령어를 사용하여 Docker 이미지를 빌드하고, 클러스터에서 사용 가능한 컨테이너 레지스트리에 푸시합니다.
docker build -t <your-registry>/lb-pred-model.edu .
docker push <your-registry>/lb-pred-model.edu공개 이미지 사용 안내컨테이너 이미지 빌드와 레지스트리 등록이 어려운 경우, 카카오클라우드에서 제공하는 공개 이미지를 사용할 수 있습니다.
- 이미지 경로:
mlops.kr-central-2.kcr.dev/kc-kubeflow-registry/lb-pred-model:edu
이 이미지는
tune.py스크립트와 필요한 라이브러리가 포함되어 있으며,/dataset경로에 데이터셋이 마운트되어 있을 경우 바로 사용 가능합니다. 별도 이미지 빌드 없이 Katib 실습을 빠르게 시작하고자 할 때 유용합니다. - 이미지 경로:
Step 2. Experiment 설정
Katib에서 하이퍼파라미터 튜닝을 수행하려면 실험 목표, 파라미터 범위, 실행 환경 등 관련 설정이 포함된 katib-experiment.yaml 파일을 정의해야 합니다.
- IMAGE: 사용하려는 Docker 이미지 경로를 입력합니다.
- IMAGE_SECRET: 개인 레지스트리 사용 시 인증 정보가 필요합니다. 공개 이미지를 사용하는 경우 생략 가능합니다. 카카오클라우드 기술 문서 레지스트리 인증 및 관리를 참고하세요.
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
name: lb-gbr-tune
spec:
objective:
type: minimize
goal: 0.0
objectiveMetricName: MAE
metricCollectorSpec:
collector:
kind: StdOut
parallelTrialCount: 2
maxTrialCount: 10
maxFailedTrialCount: 3
algorithm:
algorithmName: random
parameters:
- name: n_estimators
parameterType: int
feasibleSpace:
min: "50"
max: "200"
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.2"
- name: max_depth
parameterType: int
feasibleSpace:
min: "2"
max: "10"
- name: subsample
parameterType: double
feasibleSpace:
min: "0.5"
max: "1.0"
trialTemplate:
primaryContainerName: training-container
trialParameters:
- name: n_estimators
description: "Number of estimators"
reference: "n_estimators"
- name: learning_rate
description: "Learning rate"
reference: "learning_rate"
- name: max_depth
description: "Maximum depth of the trees"
reference: "max_depth"
- name: subsample
description: "Subsample ratio"
reference: "subsample"
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
metadata:
annotations:
sidecar.istio.io/inject: 'false'
spec:
containers:
- name: training-container
image: {{IMAGE}}
command:
- "python"
- "/app/tune.py"
args:
- "--n_estimators"
- "${trialParameters.n_estimators}"
- "--learning_rate"
- "${trialParameters.learning_rate}"
- "--max_depth"
- "${trialParameters.max_depth}"
- "--subsample"
- "${trialParameters.subsample}"
resources:
requests:
cpu: '0.5'
memory: 1Gi
limits:
cpu: '1'
memory: 2Gi
volumeMounts:
- name: dataset
mountPath: /dataset
imagePullSecrets:
- name: {IMAGE_SECRET}
restartPolicy: Never
volumes:
- name: dataset
persistentVolumeClaim:
claimName: dataset-pvc
주요 필드 설명
| 필드 | 설명 |
|---|---|
spec.objective | 튜닝의 목표로 하는 metric, 최소나 최대로 설정 이미지 내에서 값이 출력되도록 설정 |
spec.parameters | 탐색하고자 하는 하이퍼파라미터에 대한 명세 타입과 범위 지정 |
trialTemplate.trialParameters | 실험에서 사용하는 하이퍼파라미터 명세 Katib UI에서 입력 받는 항목 |
trialTemplate.trialSpec | 실험을 수행할 파드의 스펙 |
Step 3. Experiment 실행
Katib 실험을 Kubeflow 대시보드에서 생성하는 방법은 다음과 같습니다.
-
Kubeflow 대시보드에 접속 후 왼쪽 Experiments (AutoML) 메뉴를 선택합니다.
-
[+ New Experiment] 버튼을 클릭하고, 중앙 하단의 Edit 버튼을 누릅니다.
-
이전 스텝에서 생성한
katib-experiment.yaml을 붙여넣고 CREATE 버튼을 클릭합니다.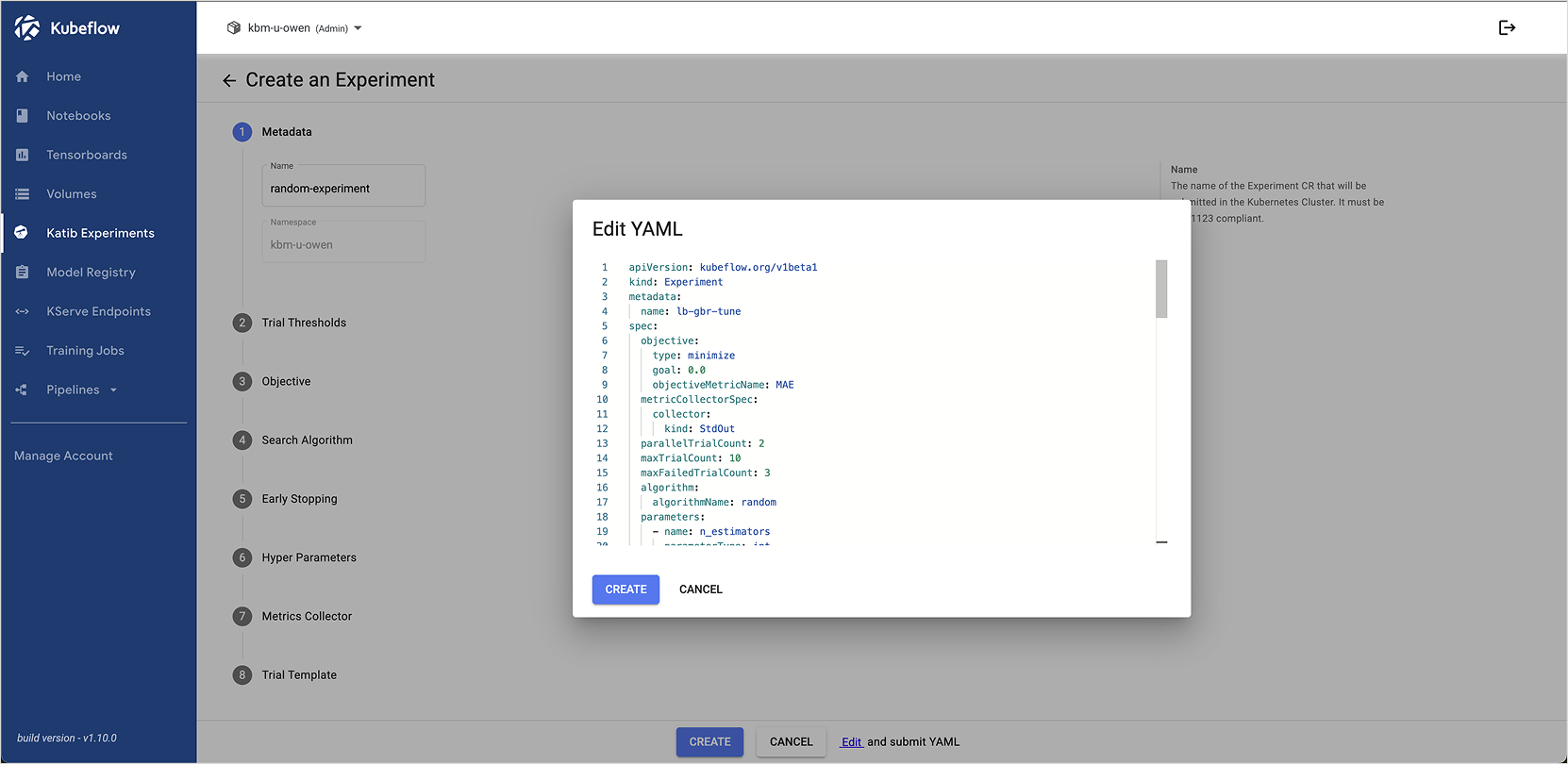
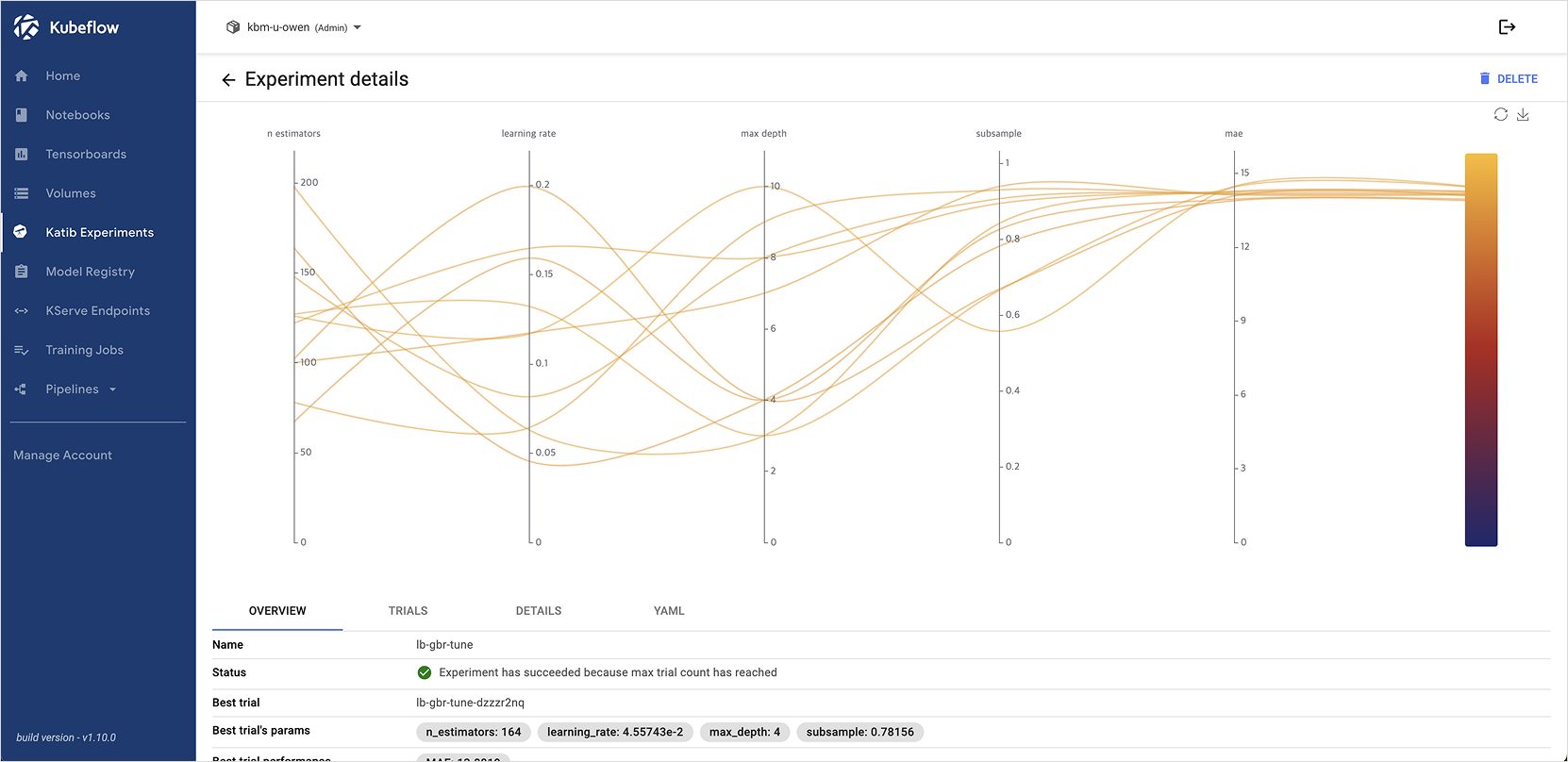
Step 4. 튜닝 결과 확인
Experiment 생성 후 [lb-gbr-tune]을 클릭하면 튜닝 결과를 확인할 수 있습니다. Katib은 각 Trial에서 실행된 파라미터 조합과 평가 결과를 자동으로 기록하며, 성능이 가장 우수한 조합을 쉽게 찾을 수 있습니다.