3. 모델 서빙 API 생성
카카오클라우드 Kubeflow에서 학습한 트래픽 예측 모델을 API로 서빙하는 방법을 안내합니다.
- 예상 소요 시간: 30분
- 권장 운영 체제: macOS, Ubuntu
- 사전 준비 사항
시나리오 소개
KServe는 Kubernetes 기반의 서버리스 모델 추론(Serving) 프로젝트로, TensorFlow, PyTorch, Scikit-learn, XGBoost 등 다양한 머신러닝 프레임워크에 대한 표준화된 서빙 인터페이스를 제공합니다.
이 튜토리얼에서는 KServe를 활용한 머신러닝 모델 서빙 과정을 수행합니다. 클러스터에서 InferenceService를 생성하는 법과 Model Registry와 연동하여 파이썬으로 모델 배포하는 방법을 설명합니다.
시작하기
⚠️ 이 실습은 앞선 트래픽 예측 튜토리얼(1, 2편) 을 완료한 상태를 기준으로 작성되었습니다.
KServe를 활용한 모델 배포
KServe 에서는 InferenceService라는 사용자정의 리소스를 사용해 모델을 배포합니다.
-
아래 예제는 Scikit-learn 프레임워크를 사용한 모델을 배포하는 설정입니다. 이 코드를 참고하여
lb-isvc.yaml 파일을 작성합니다.InferenceService 작성 (lb-isvc.yaml)apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: lb-predictor
spec:
predictor:
model:
modelFormat:
name: sklearn
runtime: kserve-sklearnserver
args:
- '--model_name=lb-predictor'
storageUri: "pvc://model-pvc/lb-predictor"주요 필드 설명
필드 설명 name모델 서비스 이름 지정 (예: lb-predictor)modelFormat사용할 모델 프레임워크 형식 지정 (예: sklearn)runtime모델 서빙에 사용할 런타임 이름 지정 (예: kserve-sklearnserver)storageUri모델이 저장된 PVC 경로 지정 (예: pvc://model-pvc/lb-predictor)Scikit-learn 외의 프레임워크를 사용하는 방법은 공식 문서를 참고하세요.
-
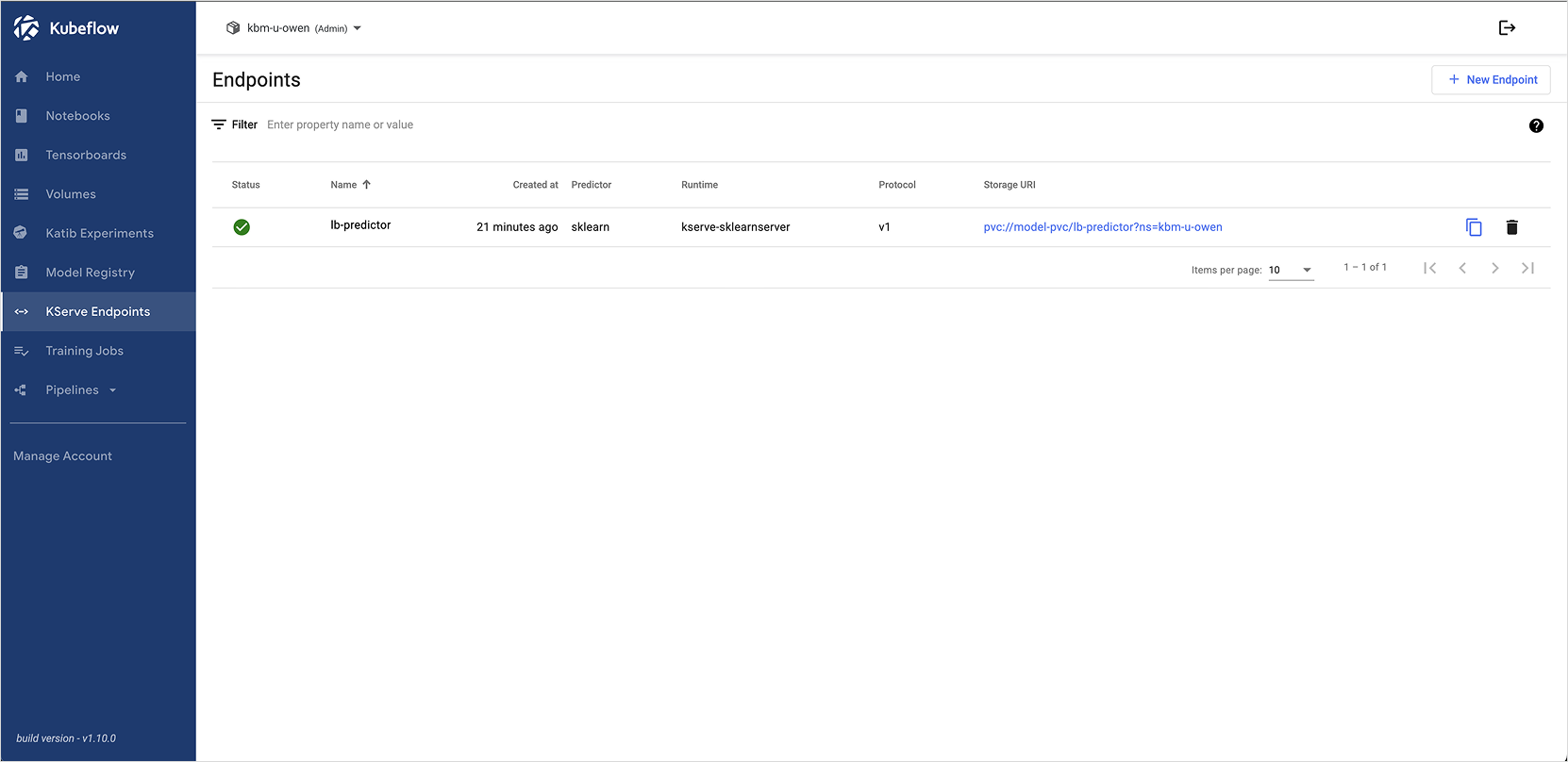
Kubeflow 대시보드에 접속한 뒤, 왼쪽 Endpoint 메뉴를 선택합니다.
-
[+ New Endpoint] 버튼을 클릭하고, 위 infsvc.yaml 파일의 내용을 붙여넣습니다.
-
생성 결과를 확인합니다. (상황에 따라 수 분 정도 소요될 수 있음)
-
Notebook 터미널에서 다음 명령어로 추론을 수행할 수 있습니다.
추론 명령어curl -X POST http://{ISVC_NAME}.{NAMESPACE}.svc.cluster.local/v1/models/{MODEL_NAME}:predict \
-H "Content-Type: application/json" \
-d '{"instances": [[0.1, 0.1, 0.1, 0.1]]}' # 입력 데이터ISVC_NAME: 생성한 InferenceService 이름 (예:lb-predictor)NAMESPACE: 사용자 네임스페이스MODEL_NAME: 아규먼트로 넘겨준 모델 이름 (예:lb-predictor)
-
명령어 실행 시 아래와 같은 결과가 출력됩니다.
실행 결과{"predictions":[46.52174265571983]}위 URL은 클러스터 내부에서만 접근 가능합니다. 외부에서 접속하려면 KServe 문서를 참고하세요.
Model Registry를 활용한 모델 배포
Model Registry는 Kubeflow의 컴포넌트 중 하나로, 머신러닝 모델의 버전, 아티팩트(artifact), 메타데이터를 관리할 수 있도록 지원합니다. KServe는 Model Registry와의 통합을 통해, 모델을 등록하고 관리한 후 간편하게 배포할 수 있도록 지원합니다.
아래 예제는 Model Registry에 모델을 등록하고 KServe로 배포하는 전체 과정을 보여줍니다.
-
Notebook 터미널에서 Model Registry 및 KServe 관련 패키지를 설치합니다.
필수 라이브러리 설치pip install --user model-registry==0.2.19 kserve==0.15.0 --quiet일부 환경에서는 특정 버전으로 설치할 경우 의존성 충돌이 발생할 수 있습니다.
-
모듈을 import 하고 Model Registry 클라이언트를 생성합니다. [USER_NAME]에는 사용자 계정, [NAMESPACE] 에는 사용자의 namespace를 넣어줍니다.
클라이언트 구성from model_registry import ModelRegistry
registry = ModelRegistry(
server_address="http://model-registry-service.{{namespace}}.svc.cluster.local",
port=8080,
author="[USER_NAME]",
is_secure=False
) -
PVC 경로에 저장된 모델 파일을 레지스트리에 등록합니다. 등록 시 모델 이름, 버전, 포맷 정보를 함께 지정해야 합니다. (metadata에는 사용자의 namespace 정보를 넣어줍니다.)
모델 등록model_name = "lb-predictor"
model_path = f"pvc://model-pvc/lb-predictor/model.joblib" # PVC 경로 사용
model_version = "1.0.0"
rm = registry.register_model(
model_name,
model_path,
model_format_name="joblib",
model_format_version="1",
version=model_version,
metadata= {"namespace": {NAMESPACE}}
) -
등록된 모델 정보를 기반으로 Kserve의
InferenceService를 생성합니다.Kserve 배포from kubernetes import client
import kserve
model = registry.get_registered_model(model_name)
print("Registered Model:", model, "with ID", model.id)
version = registry.get_model_version(model_name, model_version)
print("Model Version:", version, "with ID", version.id)
art = registry.get_model_artifact(model_name, model_version)
print("Model Artifact:", art, "with ID", art.id)
isvc = kserve.V1beta1InferenceService(
api_version=kserve.constants.KSERVE_GROUP + "/v1beta1",
kind=kserve.constants.KSERVE_KIND_INFERENCESERVICE,
metadata=client.V1ObjectMeta(
name=model_name,
labels={
"modelregistry/registered-model-id": model.id,
"modelregistry/model-version-id": version.id,
},
),
spec=kserve.V1beta1InferenceServiceSpec(
predictor=kserve.V1beta1PredictorSpec(
sklearn=kserve.V1beta1SKLearnSpec(
args=['--model_name=lb-predictor'],
storage_uri=art.uri
)
)
),
)
ks_client = kserve.KServeClient()
ks_client.create(isvc) -
모델 배포가 완료되면 클러스터 내에서 다음 명령어로 추론을 테스트할 수 있습니다.
추론 테스트import requests
import json
isvc_name = "lb-predictor" # isvc 서비스 이름
model_name = "lb-predictor" # 모델 이름
namespace = "{NAMESPACE}" # 사용자의 네임스페이스 (kbm-u-XX)
url = f"http://{isvc_name}.{namespace}.svc.cluster.local/v1/models/{model_name}:predict"
# 요청 데이터 (입력 값)
payload = {
"instances": [[0.1, 0.1, 0.1, 0.1]]
}
# HTTP 요청 헤더
headers = {
"Content-Type": "application/json"
}
# POST 요청 보내기
response = requests.post(url, data=json.dumps(payload), headers=headers)
# 응답 출력
print("Status Code:", response.status_code)
print("Response:", response.json())실행 결과Status Code: 200
Response: {'predictions': [65.98312040830406]}