Cloud Trail 로그를 Splunk Enterprise로 적재
Object Storage에 저장된 Cloud Trail 로그를 Splunk Enterprise로 수집 및 분석하는 방법을 안내합니다.
- 예상 소요 시간: 40분
- 권장 운영 체제: macOS, Ubuntu
- 사전 준비 사항
시나리오 소개
이 시나리오는 Object Storage에 저장된 Cloud Trail 로그를 Splunk Enterprise로 적재하는 방법을 자세히 설명합니다. 이를 통해 실시간 모니터링 및 분석 환경을 구축하고, 시스템 상태를 시각적으로 확인하며 이상 징후를 빠르게 감지해 장애에 신속하게 대응할 수 있습니다.
주요 내용은 다음과 같습니다.
- Splunk Enterprise 인스턴스 설정
- Splunk Universal Forwarder 에이전트 설정: Forwarder 에이전트를 설치하고, 로그 파일을 Splunk Enterprise로 포워딩하는 설정
- 로그 저장 자동화: Object Storage에 저장된 Cloud Trail 로그를 Forwarder 에이전트의 특정 디렉터리에 저장하는 자동 스크립트 작성
- 오류 발생 시, 누락된 로그를 자동으로 다운로드하도록 설정
- 백그라운드 프로세스 등록: 스크립트를 매시간 실행되는 백그라운드 프로세스로 등록
- Splunk Enterprise에 적재된 로그 확인
- Splunk Enterprise: 기업용 데이터 분석 플랫폼으로, 다양한 로그 데이터를 실시간으로 수집·분석하여 시스템 운영 현황을 모니터링하고 이상 징후를 신속하게 감지합니다.
- Splunk Universal Forwarder: 경량 데이터 수집 에이전트로, 원격 서버의 로그와 데이터를 수집하여 Splunk Indexer로 전송하는 역할을 합니다. 이를 활용하면 Object Storage에서 로그를 자동으로 가져와 Splunk Enterprise로 전송할 수 있으며, 이를 통해 실시간 분석 및 검색이 가능합니다.
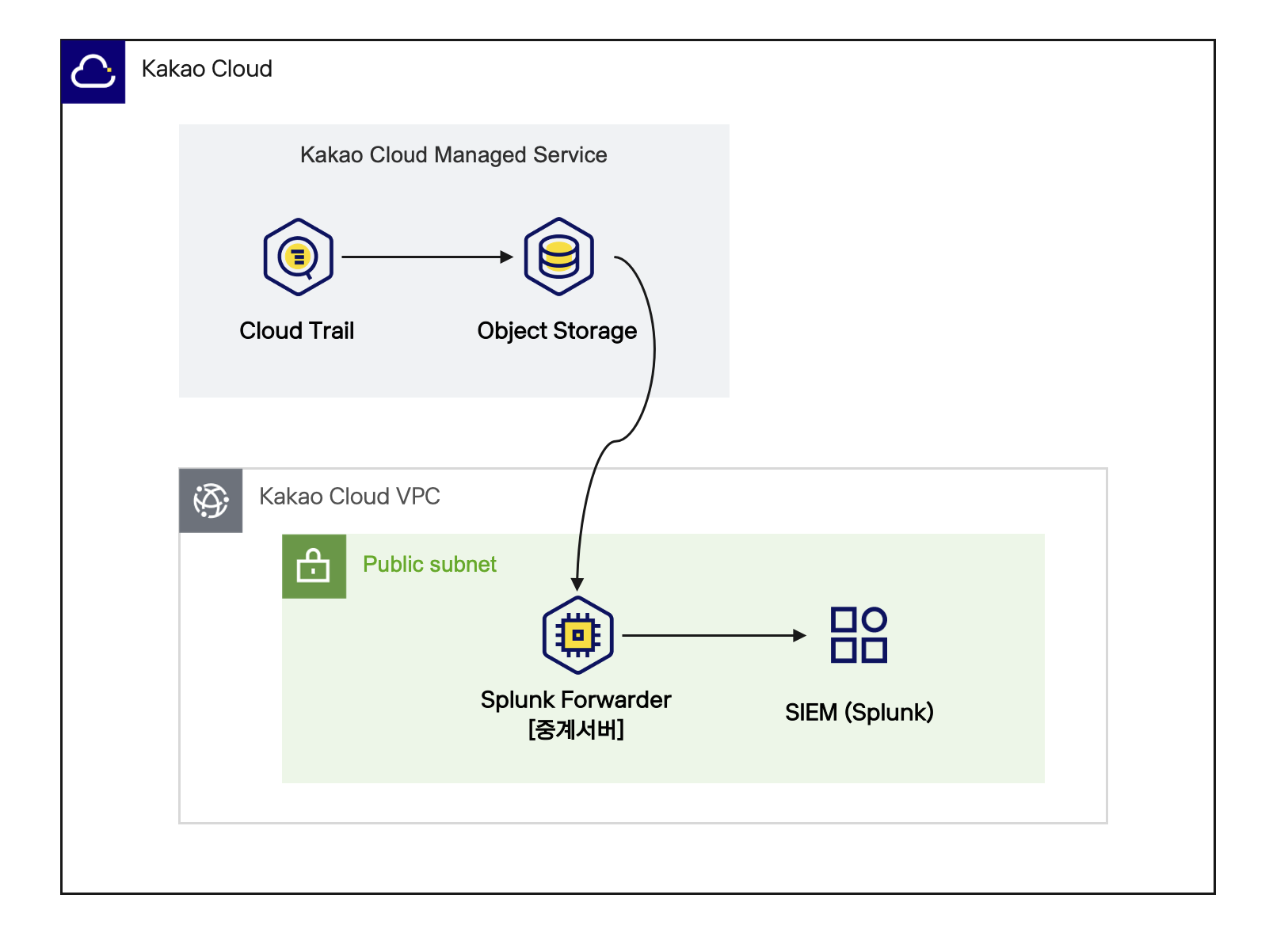 아키텍처
아키텍처
시작하기 전에
Splunk 서버와 Forwarder 에이전트의 설정 및 로그 처리 환경을 구축하기 위해 필요한 사전 작업을 안내합니다.
1. Object Storage 버킷 생성 및 Cloud Trail 로그 저장 활성화
Cloud Trail 로그를 활용하려면 먼저 로그를 저장할 Object Storage 버킷을 생성해야 합니다. 이 버킷은 Cloud Trail 로그를 저장할 장소로 사용되며, 이후에 해당 데이터를 Splunk 서버로 전달하여 분석에 활용할 수 있습니다. 또한, Cloud Trail 로그가 Object Storage에 자동으로 저장되도록 Cloud Trail 로그 저장 기능 활성화 설정을 합니다.
2. 네트워크 환경 구축
Splunk Enterprise 서버와 Forwarder 에이전트 간 원활한 통신을 위한 VPC와 서브넷을 구성합니다.
VPC 및 서브넷: tutorial
-
카카오클라우드 콘솔 > Networking > VPC 메뉴로 이동합니다.
-
우측의 [+ VPC 생성] 버튼을 클릭한 후, 다음과 같이 VPC 및 서브넷을 생성합니다.
구분 항목 설정/입력값 VPC 정보 VPC 이름 tutorial VPC IP CIDR 블록 10.0.0.0/16 Availability Zone 가용 영역 개수 1 첫 번째 AZ kr-central-2-a 서브넷 설정 가용 영역당 퍼블릭 서브넷 개수 1 kr-central-2-a 퍼블릭 서브넷 IPv4 CIDR 블록: 10.0.0.0/20
-
하단에 생성되는 토폴로지를 확인 후, 이상이 없다면 [생성] 버튼을 클릭합니다.
- 서브넷의 상태는 Pending Create > Pending Update > Active 순서로 변경됩니다. Active 상태가 되어야 다음 단계를 진행할 수 있습니다.
3. 보안 그룹 설정
보안 그룹을 설정하면 외부 접근을 차단하고 필요한 트래픽만 허용하여 Splunk 서버와 Forwarder 에이전트 간 보안을 강화할 수 있습니다.
보안 그룹: tutorial-splunk-sg
-
카카오클라우드 콘솔 > VPC > 보안 그룹 메뉴로 이동합니다. 아래 표를 참조하여 보안 그룹을 생성합니다.
이름 설명(선택) tutorial-splunk-sg Splunk 서버의 보안정책 -
하단의 [+ 추가하기] 버튼을 클릭한 뒤 인바운드 조건을 아래와 같이 설정하고 [적용] 버튼을 클릭합니다.
추가할 인바운드 규칙 항목 설정값 splunk inbound policy 1 프로토콜 TCP 패킷 출발지 {사용자 퍼블릭 IP}/32포트 번호 22 정책 설명(선택) SSH 접속 허용 splunk inbound policy 2 프로토콜 TCP 패킷 출발지 {사용자 퍼블릭 IP}/32포트 번호 8000 정책 설명(선택) splunk enterprise web (관리 페이지) 접속 허용
보안 그룹: tutorial-forwarder-sg
-
카카오클라우드 콘솔 > VPC > 보안 그룹 메뉴로 이동합니다. 아래 표를 참조하여 보안 그룹을 생성합니다.
이름 설명(선택) tutorial-forwarder-sg Forwarder 서버의 보안정책 -
하단의 [+ 추가하기] 버튼을 클릭한 뒤 인바운드 조건을 아래와 같이 설정하고 [적용] 버튼을 클릭합니다.
추가할 인바운드 규칙 항목 설정값 forwarder inbound policy 1 프로토콜 TCP 패킷 출발지 {사용자 퍼블릭 IP}/32포트 번호 22 정책 설명(선택) SSH 접속 허용
시작하기
Splunk Enterprise와 Forwarder를 활용하여 로그 데이터를 수집하고 분석하는 환경을 구성합니다. 각 단계는 Splunk 인스턴스 생성, Forwarder 설정, 자동 로그 전송 스크립트 작성으로 구성됩니다.
Step 1. Splunk 인스턴스 구성
Splunk Enterprise를 설치할 인스턴스를 생성하고, 초기 설정을 통해 로그 수집 및 분석을 위한 기본 환경을 구성합니다.
-
Splunk 공식 사이트에서 무료 평가판 Splunk Enterprise 라이센스를 다운로드합니다. 이번 실습에서는 Linux > .tgz 파일의 wget 링크 복사를 클릭합니다.
-
카카오클라우드 Virtual Machine 서비스에서 Splunk Enterprise 서버로 사용할 인스턴스를 생성합니다.
Splunk 인스턴스: tutorial-splunk
-
카카오클라우드 콘솔 > Virtual Machine 메뉴로 이동합니다.
-
아래 표의 항목과 값을 참조하여 Splunk Enterprise 서버의 역할을 할 인스턴스를 생성합니다.
구분 항목 설정/입력값 비고 기본 정보 이름 tutorial-splunk 개수 1 이미지 Ubuntu 24.04 인스턴스 타입 m2a.large 볼륨 루트 볼륨 50 키 페어 {PRIVATE_KEY}⚠️ 키 파일은 최초 1회 안전하게 보관해야 합니다.
잃어버린 키는 복구할 수 없으며, 재발급이 필요합니다.네트워크 VPC tutorial 보안 그룹 tutorial-splunk-sg 네트워크 인터페이스 1 새 인터페이스 서브넷 main (10.0.0.0/20) IP 할당 방식 자동 -
생성된 Splunk 인스턴스에 퍼블릭 IP를 연결합니다.
-
-
생성된 Splunk 인스턴스에 SSH 접속을 하여 아래 명령어를 통해 Splunk Enterprise를 설치합니다.
# 다운로드
1번에서 복사한 wget 명령어 입력
# 다운로드한 파일 압축 해제
tar xvzf splunk-9.4.0-6b4ebe426ca6-linux-amd64.tgz
# Splunk 서버 시작
sudo ./splunk/bin/splunk start --accept-license --run-as-root
# 이때, 로그인할 username과 password를 입력합니다.
# 이후 정상 출력 예시
Waiting for web server at http://127.0.0.1:8000 to be available............ Done
If you get stuck, we're here to help.
Look for answers here: http://docs.splunk.com
The Splunk web interface is at http://host-172-16-0-32:8000 -
브라우저에서 http://
{SPLUNK_인스턴스_퍼블릭_IP}:8000에 접속 후, Splunk 서버 시작 시 입력한 username과 password로 로그인합니다. -
접속한 Splunk Enterprise 페이지에서 설정 > 전달 및 수신 > 데이터 수신에서 새 수신 포트 버튼을 클릭하여 9997 포트를 생성합니다. (아래 그림 참고)
 참고 그림
참고 그림
Step 2. Forwarder 인스턴스 구성
Object Storage에 저장된 로그를 쉽게 포워딩하기 위해 Splunk Universal Forwarder 에이전트를 설치합니다. 이 튜토리얼에서는 해당 에이전트 서버를 Forwarder 인스턴스라고 하겠습니다.
-
Forwarder 인스턴스를 생성합니다.
Forwarder 인스턴스: tutorial-forwarder
-
카카오클라우드 콘솔 > Virtual Machine 메뉴로 이동합니다.
-
아래 표의 항목과 값을 참조하여 Forwarder 에이전트의 역할을 할 인스턴스를 생성합니다.
구분 항목 설정/입력값 비고 기본 정보 이름 tutorial-forwarder 개수 1 이미지 Ubuntu 24.04 인스턴스 타입 m2a.large 볼륨 루트 볼륨 50 키 페어 {PRIVATE_KEY}⚠️ 키 파일은 최초 1회 안전하게 보관해야 합니다.
잃어버린 키는 복구할 수 없으며, 재발급이 필요합니다.네트워크 VPC tutorial 보안 그룹 tutorial-forwarder-sg 네트워크 인터페이스 1 새 인터페이스 서브넷 main (10.0.0.0/20) IP 할당 방식 자동 -
생성된 Splunk 인스턴스에 퍼블릭 IP를 연결합니다.
-
생성된 Splunk 인스턴스에 SSH 접속을 합니다.
-
-
Forwarder 인스턴스에 SSH로 접속한 후, Splunk 공식 문서를 참고하여 Universal Forwarder 에이전트를 설치합니다.
-
아래의 설정을 통해 Splunk Enterprise 서버로 로그 데이터를 전송할 준비를 합니다.
# Splunk Enterprise로 데이터를 보낼 파일이 저장되어 있을 디렉터리 생성
sudo mkdir /home/ubuntu/cloudtrail/processed_data
# Splunk에서 해당 디렉터리 내의 로그 파일을 모니터링하도록 설정
sudo /home/ubuntu/splunkforwarder/bin/splunk add monitor /home/ubuntu/cloudtrail/processed_data/
# 모니터링하는 로그 데이터를 Splunk Enterprise 서버로 전송하도록 설정
sudo /home/ubuntu/splunkforwarder/bin/splunk add forward-server ${SPLUNK_PRIVATE_IP}:${SPLUNK_PORT}환경변수 설명 SPLUNK_PRIVATE_IP🖌︎ Splunk 인스턴스 Private IP SPLUNK_PORT🖌︎ Splunk 수신 포트 9997 팁- Splunk Universal Forwarder가 정상적으로 작동하는 경우, processed_data 디렉터리에 저장된 모든 로그 파일은 자동으로 Splunk 서버로 전송됩니다.
- 네트워크 문제로 Forwarder와 Splunk 서버 간의 통신이 일시적으로 끊길 수 있습니다. 이 경우 로그 파일이 서버로 전송되지 않거나 반영되지 않을 수 있습니다. 이때는
/splunkforwarder/var/log/splunk/splunkd.log파일을 확인하여 통신이 끊긴 시간대를 파악할 수 있습니다. 해당 파일에는 Forwarder와 서버 간 연결 문제에 대한 상세 정보가 기록됩니다. - 만약 통신 장애로 인해 전송되지 않은 로그 파일이 있다면, 해당 로그 파일을 다시 processed_data 디렉터리에 복사하세요. Splunk Forwarder가 이를 자동으로 감지하여, 누락된 로그를 다시 서버로 전송합니다.
- 네트워크 문제로 인해 로그가 유실되더라도, 원본 데이터를 processed_data 디렉터리에 보관하고 있다면 후속 조치로 복구가 가능합니다.
권장 설정Splunk Forwarder 권한 문제 해결
Splunk Universal Forwarder(UF)는 기본적으로 splunk 사용자 계정으로 실행됩니다. 따라서 Forwarder가 processed_data 디렉터리에 접근할 수 있도록 권한을 부여해야 합니다.# processed_data 디렉터리 소유자 변경
sudo chown -R splunk:splunk /home/ubuntu/cloudtrail/processed_data
# 또는 필요한 경우 읽기 권한 부여
sudo chmod -R 755 /home/ubuntu/cloudtrail/processed_data권한이 제대로 설정되지 않으면 Forwarder가 로그 파일을 감지하지 못해 Splunk Enterprise로 로그가 전달되지 않습니다.
- Splunk Universal Forwarder가 정상적으로 작동하는 경우, processed_data 디렉터리에 저장된 모든 로그 파일은 자동으로 Splunk 서버로 전송됩니다.
-
위에서 설정한 내용이 제대로 반영되었는지 확인합니다. 아래 파일은 Splunk Universal Forwarder의
outputs.conf파일로, 데이터를 전송할 대상 서버에 대한 설정을 포함하고 있습니다.sudo cat /home/ubuntu/splunkforwarder/etc/system/local/outputs.conf
# 출력 예시
[tcpout]
defaultGroup = default-autolb-group
[tcpout:default-autolb-group]
server = ${SPLUNK_PRIVATE_IP}:${SPLUNK_PORT}
[tcpout-server://${SPLUNK_PRIVATE_IP}:${SPLUNK_PORT}]환경변수 설명 SPLUNK_PRIVATE_IP🖌︎ Splunk 인스턴스 Private IP SPLUNK_PORT🖌︎ Splunk 수신 포트 9997 -
Splunk 인스턴스를 위한 보안 그룹(tutorial-splunk-sg)에 아래 인바운드 규칙을 추가합니다.
보안 그룹: tutorial-splunk-sg
-
카카오클라우드 콘솔 > VPC > 보안 그룹 메뉴로 이동합니다. 아래 표를 참조하여 보안 그룹을 생성합니다.
이름 설명(선택) tutorial-splunk-sg Splunk 서버의 보안정책 -
하단의 [+ 추가하기] 버튼을 클릭한 뒤 인바운드 규칙을 추가하고 [적용] 버튼을 클릭합니다.
추가할 인바운드 규칙 항목 설정값 splunk inbound policy 3 프로토콜 TCP 패킷 출발지 {Forwarder Server Private IP}/32포트 번호 9997 정책 설명(선택) UF에서 로그를 수집하는 포트
-
Step 3. 자동 로그 저장 스크립트 작성
Cloud Trail의 로그 저장 기능을 사용하면, 매시간마다 로그가 Object Storage 버킷 내에 하나의 파일로 저장됩니다. 이 로그를 매시간 Splunk Universal Forwarder 에이전트로 읽어 Splunk Enterprise 서버로 전송하는 자동 스크립트를 작성할 수 있습니다.
- 최초 스크립트 실행 시, Object Storage의 로그 파일과 Forwarder 에이전트의 로컬 로그 파일을 비교하여 모든 파일을 다운로드합니다.
- 가장 최근에 수정된 파일을 Object Storage에서 다운로드하고 압축을 해제합니다.
- 압축 해제된 파일을 JSON 객체 리스트로 변환하여 processed_data 디렉터리에 저장한 후, 해당 JSON 객체 리스트를 Splunk로 이벤트 전송합니다.
- 중간에 오류가 발생하면, 누락된 로그 파일을 자동으로 확인하고 다운로드합니다.
- 참고 사항: 2~4번 과정은 매시간 10분마다 반복됩니다.
-
Forwarder 인스턴스에서 스크립트를 실행하기 위해 Python 환경을 준비합니다.
python3 --version
sudo apt update
sudo apt install -y python3-venv python3-pip
python3 -m venv myenv
source myenv/bin/activate
pip install --upgrade pip안내본 튜토리얼에서는 AWS CLI를 사용하여 Object Storage에 접근하므로, boto3와 같은 별도의 Python SDK 설치는 필요하지 않습니다.
-
자동 스크립트에서 AWS CLI를 사용하려면, 먼저 AWS CLI를 설치하고 설정합니다.
AWS CLI 설치# 패키지 업데이트 및 필수 도구 설치
sudo apt update
sudo apt install -y curl unzip
# AWS CLI 2.15.41 다운로드
curl -sSL "https://awscli.amazonaws.com/awscli-exe-linux-x86_64-2.15.41.zip" -o awscliv2.zip
# 압축 해제 및 설치
unzip -q awscliv2.zip
sudo ./aws/install --update
# 설치 확인
aws --version주의카카오클라우드 Object Storage와 호환되는 AWS CLI 권장 버전은 2.15.x ~ 2.22.x입니다. 본 가이드에서는 2.15.41 버전을 예시로 사용합니다.
사전 준비에서 S3 API 사용을 위해 발급받은 크리덴셜을 확인하고, 아래 명령어로 AWS CLI를 설정합니다.
AWS CLI를 설정aws configureAWS Access Key ID: ${CREDENTIAL_ACCESS_KEY}
AWS Secret Access Key: ${CREDENTIAL_SECRET_ACCESS_KEY}
Default region name: kr-central-2
Default output format: json환경변수 설명 CREDENTIAL_ACCESS_KEY🖌︎ S3 API 사용에 필요한 액세스 키 CREDENTIAL_SECRET_ACCESS_KEY🖌︎ S3 API 사용에 필요한 비밀 액세스 키 -
정확한 로그 수집 및 이벤트 시간 정렬을 위해 서버의 시간을 한국 표준시(KST)로 설정하고 NTP 기반 동기화를 수행합니다.
# 타임존을 한국(Seoul)으로 변경
sudo timedatectl set-timezone Asia/Seoul
# chrony 설치 및 강제 동기화
sudo apt-get update && sudo apt-get install -y chrony
sudo systemctl restart chrony
sudo chronyc -a makestep
# 시간 확인 (KST 확인)
date -
스크립트 파일을 엽니다.
스크립트 파일 열기sudo vi /home/ubuntu/cloudtrail/script.py -
아래 스크립트의 변수를 수정하여 자동 스크립트를 작성합니다.
안내아래 스크립트에 작성된 IAM 엔드포인트 URL과 Object Storage 엔드포인트 URL은 추후 프라이빗 엔드포인트가 제공될 경우, 변경하여 사용할 수 있습니다.
import os, json, gzip, subprocess, datetime, time, logging
# === 사용자 지정 변수 ===
# Cloud Trail 로그가 저장되는 Object Storage 버킷 이름
BUCKET_NAME = "<BUCKET_NAME>"
# 다운로드 및 가공 로그 저장 경로
DOWNLOAD_DIR = "/home/ubuntu/cloudtrail"
PROCESSED_DIR = os.path.join(DOWNLOAD_DIR, "processed_data")
# 체크포인트 파일 (중복 적재 방지)
CHECKPOINT_FILE = "/home/ubuntu/cloudtrail/.checkpoint"
# 로그 디렉터리 준비
os.makedirs(PROCESSED_DIR, exist_ok=True)
# 로그 파일 설정
logging.basicConfig(
filename="/home/ubuntu/cloudtrail/process_log.log",
level=logging.INFO
)
def log(level, message):
"""로그 파일에 시간/레벨/메시지를 기록"""
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
logging.info(f"{now} [{level}] {message}")
def get_checkpoint():
if not os.path.exists(CHECKPOINT_FILE):
return None
with open(CHECKPOINT_FILE, "r") as f:
return f.read().strip()
def update_checkpoint(file_name):
with open(CHECKPOINT_FILE, "w") as f:
f.write(file_name)
def list_s3_files():
"""
Object Storage 버킷 내 파일 목록 조회
- recursive 옵션을 사용하여 하위 경로 포함 조회
- CloudTrail 실제 저장 형식(.gz) 기준
"""
cmd = [
"aws", "--endpoint-url", "https://objectstorage.kr-central-2.kakaocloud.com",
"s3", "ls", f"s3://{BUCKET_NAME}/", "--recursive"
]
result = subprocess.run(cmd, stdout=subprocess.PIPE, text=True)
files = [
line.split()[-1]
for line in result.stdout.splitlines()
if line.endswith(".gz")
]
return sorted(files)
def download_file(file_name):
"""
지정한 로그 파일을 Object Storage에서 다운로드
"""
local_path = os.path.join(DOWNLOAD_DIR, os.path.basename(file_name))
cmd = [
"aws", "--endpoint-url", "https://objectstorage.kr-central-2.kakaocloud.com",
"s3", "cp", f"s3://{BUCKET_NAME}/{file_name}", local_path
]
subprocess.run(cmd, check=True)
log("INFO", f"Downloaded {file_name}")
return local_path
def process_file(file_path):
"""
다운로드한 .gz 파일을 JSON 파일로 변환
"""
try:
output_file = os.path.join(
PROCESSED_DIR,
os.path.basename(file_path).replace(".gz", ".json")
)
with gzip.open(file_path, "rt") as f_in, open(output_file, "w") as f_out:
data = [json.loads(line) for line in f_in]
json.dump(data, f_out, indent=4)
if len(data) == 0:
log("WARN", f"{output_file} processed but contains 0 records")
else:
log("SUCCESS", f"Processed {output_file} ({len(data)} records)")
except Exception as e:
log("ERROR", f"Processing failed: {e}")
def run():
"""
메인 실행 함수
- 버킷 내 최신 로그 파일 조회
- 중복 처리 방지(checkpoint)
"""
files = list_s3_files()
if not files:
log("ERROR", "No .gz files found in bucket.")
return
last_file = get_checkpoint()
# 아직 처리되지 않은 파일만 선택
new_files = [f for f in files if last_file is None or f > last_file]
if not new_files:
log("INFO", "No new files to process.")
return
latest_file = new_files[-1]
file_path = download_file(latest_file)
process_file(file_path)
update_checkpoint(latest_file)
if __name__ == "__main__":
# 무한 루프: 매시간 실행
while True:
run()
log("INFO", "Waiting for next run...")
time.sleep(3600)권장 설정로그 중복 적재 방지
Forwarder가 동일 로그를 여러 번 적재하지 않도록 체크포인트 파일을 사용해 최근 처리한 파일명을 기록하는 방식을 권장합니다.CHECKPOINT_FILE = "/home/ubuntu/cloudtrail/.checkpoint"
def update_checkpoint(file_name):
"""처리 완료된 파일명을 체크포인트에 기록"""
with open(CHECKPOINT_FILE, "w") as f:
f.write(file_name)
def already_processed(file_name):
"""해당 파일이 이미 처리되었는지 확인"""
if not os.path.exists(CHECKPOINT_FILE):
return False
with open(CHECKPOINT_FILE, "r") as f:
last_file = f.read().strip()
return last_file == file_namerun 함수 수정 예시
def run():
files = list_s3_files()
if not files:
log("ERROR", "No .zip files found in bucket.")
return
latest_file = files[-1]
if already_processed(latest_file):
log("INFO", f"Already processed {latest_file}, skipping.")
return
file_path = download_file(latest_file)
process_file(file_path)
update_checkpoint(latest_file)이 로직을 추가하면 동일 로그 파일을 반복해서 Splunk에 적재하는 문제를 방지할 수 있습니다.
Step 4. 백그라운드 프로세스 실행
-
스크립트와 로그 파일에 적절한 권한을 추가합니다.
# 로그 파일 생성
sudo touch /home/ubuntu/cloudtrail/process_log.log
# 로그 파일 권한 설정
sudo chmod 666 /home/ubuntu/cloudtrail/process_log.log
# 스크립트 파일 권한 설정
sudo chmod +x /home/ubuntu/cloudtrail/script.py -
백그라운드 프로세스로 스크립트를 실행합니다.
nohup python3 /home/ubuntu/cloudtrail/script.py > /dev/null 2>&1 & -
결과를 확인합니다.
-
스크립트가 매시간 10분마다 최신 로그 파일을 /home/ubuntu/cloudtrail/processed_data 디렉터리에 json 형식으로 생성합니다.
-
ls /home/ubuntu/cloudtrail/processed_data명령어로 로그 파일이 생성되었는지 확인합니다. -
tail -f /home/ubuntu/cloudtrail/process_log.log명령어로 스크립트 실행 상태를 확인하며, 로그 파일에 출력되는 내용을 확인합니다.예시: /home/ubuntu/cloudtrail/process_log.log 파일 내용INFO:root:로컬 디렉터리에서 가져온 .zip 파일들: ['trail_XXXX-XX-XX-XX.zip', 'trail_XXXX-XX-XX-XX.zip', ...]
INFO:root:API에서 가져온 .zip 파일들: ['trail_XXXX-XX-XX-XX.zip', 'trail_XXXX-XX-XX-XX.zip', ...]
INFO:root:다운로드할 파일 목록: []
[INFO] 메인 스크립트 시작
[INFO] {'/home/ubuntu/cloudtrail/trail_XXXX-XX-XX-XX.zip'}
[SUCCESS] {'processed_data/trail_XXXX-XX-XX-XX.json'}
[SUCCESS] {'processed_data/trail_XXXX-XX-XX-XX.json'}
[INFO] 메인 스크립트 종료
[INFO] 다음 실행까지 453.866015초 대기 중...
[INFO] 메인 스크립트 시작
[INFO] {'/home/ubuntu/cloudtrail/trail_XXXX-XX-XX-XX.zip'}
[SUCCESS] {'processed_data/trail_XXXX-XX-XX-XX.json'}
[SUCCESS] {'processed_data/trail_XXXX-XX-XX-XX.json'}
[INFO] 메인 스크립트 종료
[INFO] 다음 실행까지 3597.749401초 대기 중...
[INFO] 메인 스크립트 시작
[INFO] {'/home/ubuntu/cloudtrail/trail_XXXX-XX-XX-XX.zip'}
[SUCCESS] {'processed_data/trail_XXXX-XX-XX-XX.json'}
[SUCCESS] {'processed_data/trail_XXXX-XX-XX-XX.json'}
[INFO] 메인 스크립트 종료
[INFO] 다음 실행까지 3598.177826초 대기 중...
-
Step 5. Splunk Enterprise에 적재된 로그 확인
Splunk Enterprise 웹 UI에 접속 및 로그인을 하여 Cloud Trail 로그를 확인합니다.
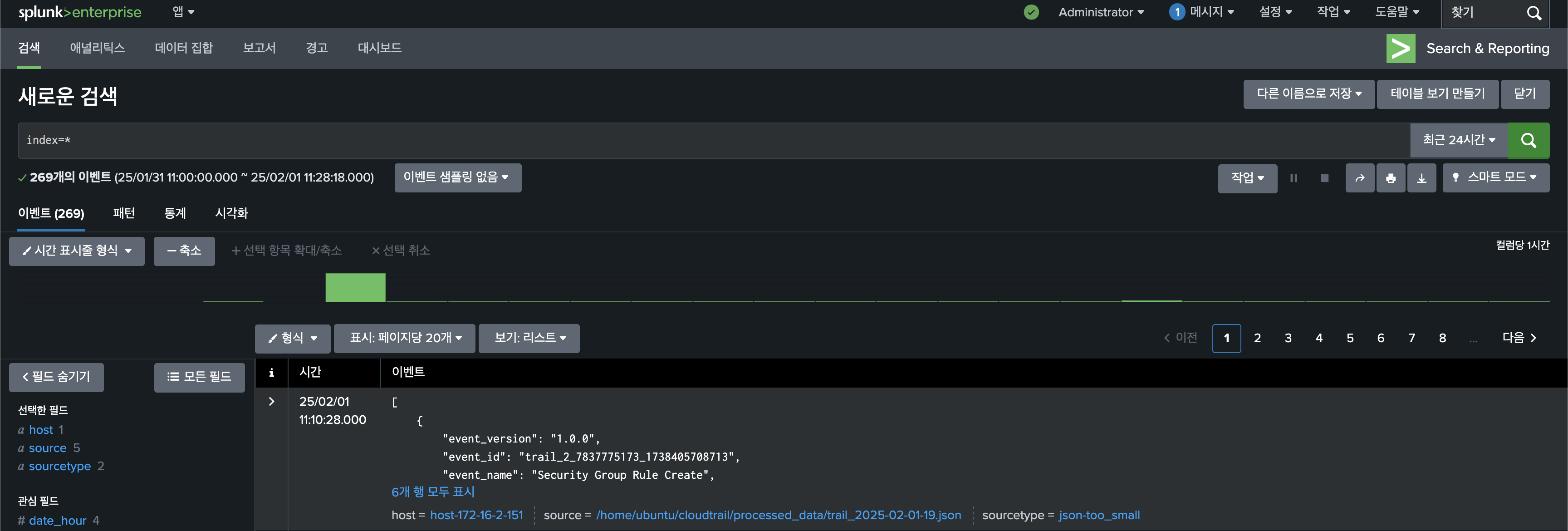 예시
예시