Analyze web server logs using Hadoop Eco
This document introduces how to easily set up an environment for analyzing server logs by integrating Hadoop Eco, Object Storage, and Data Catalog.
- Estimated time: 60 minutes
- Recommended operating system: any
- Prerequisites
About this scenario
This scenario guides you through the process of building an environment for analyzing web server logs by integrating Hadoop Eco, Object Storage, and Data Catalog. Users will learn how to efficiently analyze large log datasets to extract meaningful insights.
Key topics include:
- Uploading and managing log files using Object Storage
- Creating data catalogs and tables with Data Catalog
- Configuring a data analysis environment using a Hadoop Eco cluster
Getting started
Step 1. Upload log files to Object Storage
Upload web server logs to Object Storage for analysis.
-
Example log files use the default format of the Nginx web server. Open your local terminal and execute the following commands to save the example log files in the local downloads folder.
cat << EOF > ~/Downloads/access.log
172.16.0.174 - - [02/Mar/2023:03:04:05 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
172.16.0.174 - - [02/Mar/2023:03:04:07 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
172.16.0.174 - - [02/Mar/2023:03:04:30 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
172.16.0.174 - - [02/Mar/2023:03:48:54 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
172.16.0.174 - - [02/Mar/2023:03:48:57 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
172.16.0.174 - - [02/Mar/2023:03:48:59 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
172.16.0.174 - - [02/Mar/2023:03:49:34 +0000] "GET / HTTP/1.1" 200 396 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.3 Safari/605.1.15"
EOF -
Upload the log file to Object Storage. Refer to the table below to create a bucket and directory and upload the example log file saved in your local downloads folder.
Item Value Bucket name hands-on Directory /nginx/ori/date_id=2023-02-01/hour_id=00 File name access.log -
Verify that the example log file has been uploaded to Object Storage.
Step 2. Create Data Catalog resource
Data Catalog is a fully managed service in KakaoCloud that helps you understand and efficiently manage your organizational and user data assets. It consists of Catalog, Database, and Table components.
-
Create a Catalog as a fully managed central repository within the VPC before using the Data Catalog service.
Item Value Name hands_on VPC ${any}Subnet ${public} -
Once the created catalog is in the
Runningstate, create a Database. A database in Data Catalog serves as a container for storing tables.Item Value Catalog hands_on Name hands_on_db Path: Bucket hands-on Path: Directory nginx -
Create metadata tables: Original Data Table, Refined Data Table, and Result Data Table.
- Original data table
- Refined data table
- Result data table
| Item | Value |
|---|---|
| Database | hands_on_db |
| Table name | handson_table_original |
| Path: Bucket | hands-on |
| Path: Directory | nginx/ori |
| Data type | CSV |
Schema
| Partition key | Column number | Field name | Data type |
|---|---|---|---|
| off | 1 | log | string |
| on | - | date_id | string |
| on | - | hour_id | string |
| Item | Value |
|---|---|
| Database | hands_on_db |
| Table name | handson_table_orc |
| Path: Bucket | hands-on |
| Path: Directory | nginx/orc |
| Data type | ORC |
Schema
| Partition key | Column number | Field name | Data type |
|---|---|---|---|
| off | 1 | remote_addr | string |
| off | 2 | date_time | string |
| off | 3 | request_method | string |
| off | 4 | request_url | string |
| off | 5 | status | string |
| off | 6 | request_time | string |
| on | - | date_id | string |
| on | - | hour_id | string |
| Item | Value |
|---|---|
| Database | hands_on_db |
| Table name | handson_table_request_url_count |
| Path: Bucket | hands-on |
| Path: Directory | nginx/request_url_count |
| Data type | JSON |
Schema
| Partition key | Column number | Field name | Data type |
|---|---|---|---|
| off | 1 | request_url | string |
| off | 2 | status | string |
| off | 3 | count | int |
| on | - | date_id | string |
| on | - | hour_id | string |
Step 3. Create Hadoop Eco resource
Hadoop Eco is a KakaoCloud service designed to execute distributed processing tasks using an open-source framework.
-
Go to KakaoCloud console > Analytics > Hadoop Eco, select the [Create cluster] button, and configure the cluster with the following details:
Item Value Cluster name hands-on Cluster version Hadoop Eco 2.0.0 Cluster type Core Hadoop Cluster availability Standard Admin ID ${ADMIN_ID}Admin password ${ADMIN_PASSWORD} -
Configure Master node and Worker nodes instances.
- Set up key pairs and network configuration (VPC, subnet) to ensure SSH access to the nodes. Select Create new security group for proper access control.
Configuration Master node Worker node Number of instances 1 2 Instance type m2a.2xlarge m2a.2xlarge Volume size 50GB 100GB -
Configure the Cluster settings.
Item Value Task scheduling None HDFS block size 128 HDFS replication 2 Cluster configuration Select [Manual input] and enter the following code: Cluster configuration for Object Storage integration{
"configurations": [
{
"classification": "core-site",
"properties": {
"fs.swifta.service.kic.credential.id": "${ACCESS_KEY}",
"fs.swifta.service.kic.credential.secret": "${ACCESS_SECRET_KEY}"
}
}
]
} -
Configure Service integration.
Item Value Monitoring agent install Do not install Service integration Enable Data Catalog integration Data Catalog name Select the previously created [hands_on] -
Review the entered information and create the cluster.
Step 4. Extract original data and write to refined table
-
Connect to the master node of the Hadoop cluster using SSH.
Connect to master nodessh -i ${PRIVATE_KEY_FILE} ubuntu@${HADOOP_MST_NODE_ENDPOINT}cautionThe created master node uses a private IP and cannot be accessed directly from a public network. You may need to use a bastion host or configure a public IP for access.
-
Use Apache Hive to extract data. Apache Hive simplifies reading, writing, and managing large datasets stored in distributed storage using SQL.
Start Apache Hivehive -
Set the working database to the one created in the Data Catalog step.
Set databaseuse hands_on_db; -
Add partitions to the original log table. Verify the added partition details on the Data Catalog Console.
Add original log table partitionsmsck repair table handson_table_original;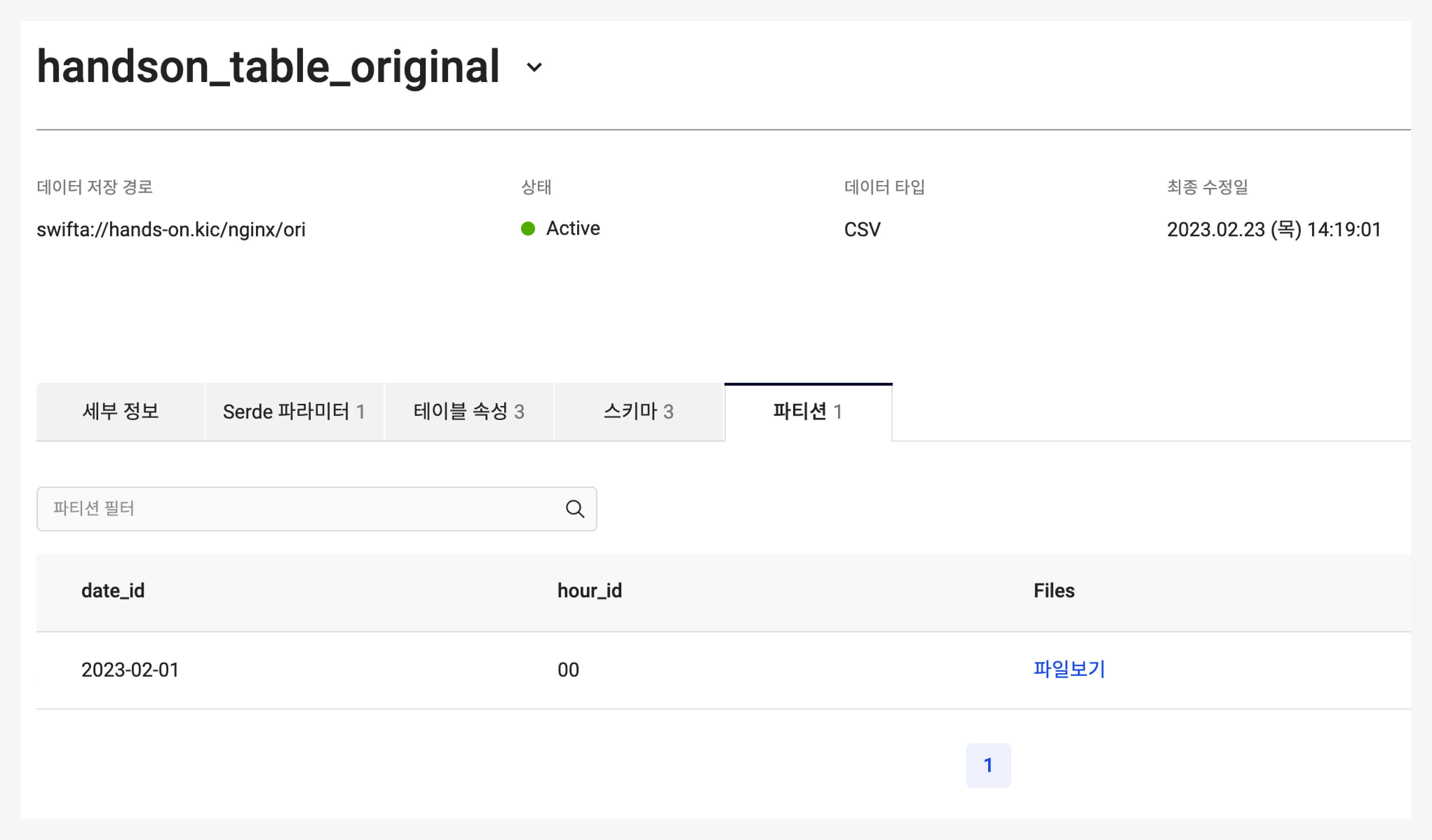
-
Run the following SQL query in HiveCLI to extract the original log data and write it to the refined table.
Run SQL queryINSERT INTO TABLE handson_table_orc PARTITION(date_id, hour_id)
SELECT remote_addr,
from_unixtime(unix_timestamp(time_local, '[DD/MMM/yyyy:HH:mm:ss')) as date_time,
request_method,
request_url,
status,
request_time,
date_id,
hour_id
FROM (
SELECT split(log, " ")[0] AS remote_addr,
split(log, " ")[3] AS time_local,
split(log, " ")[5] AS request_method,
split(log, " ")[6] AS request_url,
split(log, " ")[8] AS status,
split(log, " ")[9] AS request_time,
date_id,
hour_id
FROM handson_table_original
) R; -
Exit HiveCLI after completing the tasks.
Exit HiveCLIexit;
Step 5. Extract required data and create table
-
Start the Spark shell.
Start Spark shellspark-shell -
Use Spark to process the refined table data. Calculate the count of
request_urlandstatusand save the results in JSON format to the result table.Process and write dataspark.conf.set("spark.sql.hive.convertMetastoreOrc", false)
spark.sql("use hands_on_db").show()
spark.sql("SELECT request_url, status, count(*) as count FROM handson_table_orc GROUP BY request_url, status").write.format("json").option("compression", "gzip").save("swifta://hands-on.kic/nginx/request_url_count/date_id=2023-02-01/hour_id=01")
Step 6. Check results using Hue
Hue (Hadoop User Experience) is a web-based user interface designed for use with Apache Hadoop clusters. It allows easy access to Hadoop data and seamless integration with various Hadoop ecosystem components.
-
Access the Hue page. Open your browser and connect to port
8888on the Hadoop cluster's master node. Log in with the admin ID and password configured during cluster creation.Access Hueopen http://{HADOOP_MST_NODE_ENDPOINT}:8888cautionThe created nodes use private IPs and cannot be accessed directly from a public network. Use a bastion host or configure a public IP for access.
-
In the Hue interface, execute Hive queries. Set the working database to the one created in the Data Catalog step.
Set databaseuse hands_on_db; -
Add partitions to the result table using the following command.
Add partitions to result tablemsck repair table handson_table_request_url_count; -
Verify the partition details in the Data Catalog console.
-
Query the result table. To process JSON data, add the necessary library.
Add library for JSON data processingadd jar /opt/hive/lib/hive-hcatalog-core-3.1.3.jar; -
Retrieve and display the stored data from the result table.
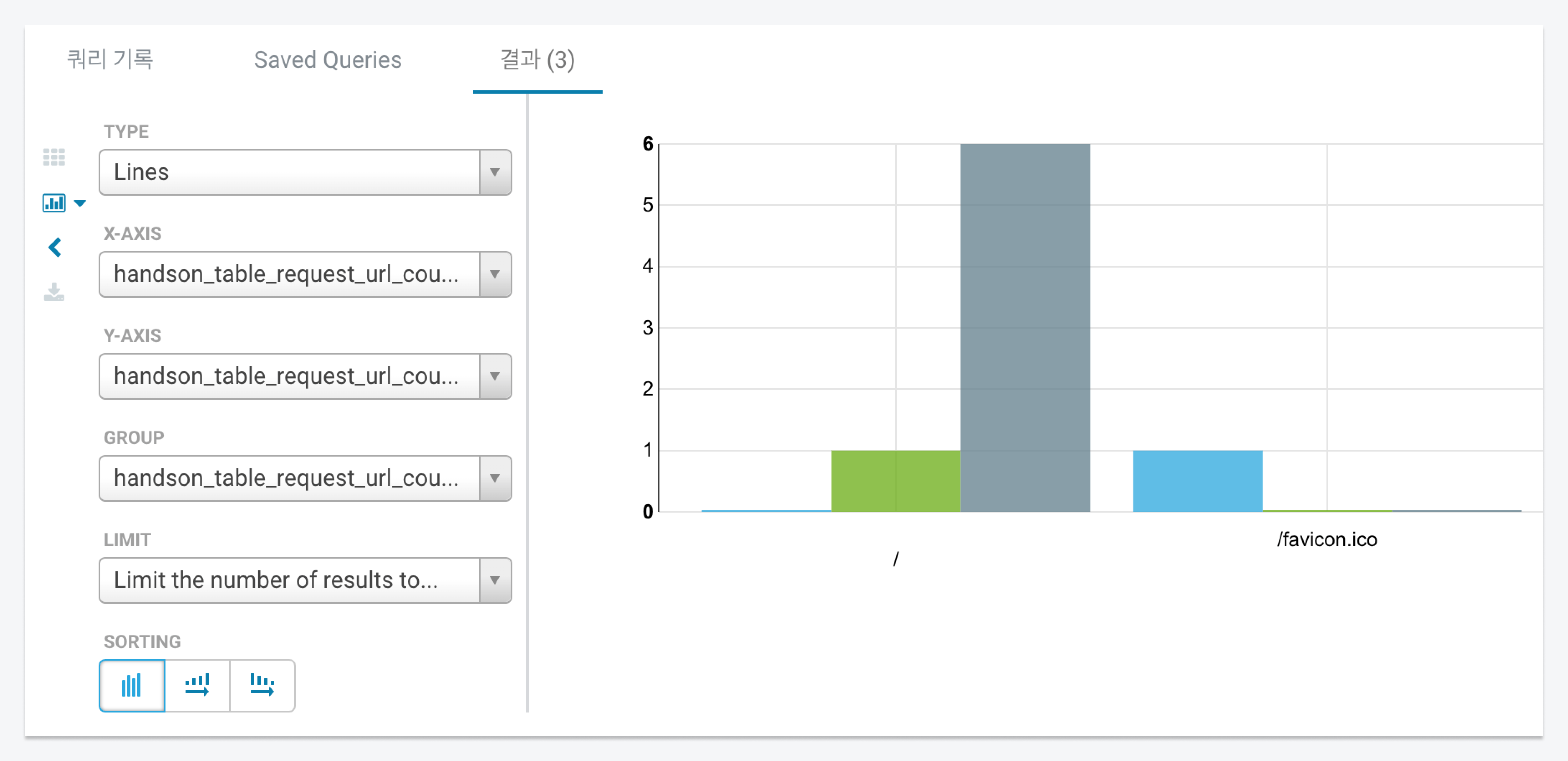
Query result dataselect * from handson_table_request_url_count order by count limit 10; -
View the query results as a graph on the Hue interface.